
ケーススタディ: 単語の出現
 ブラウズ:436
ブラウズ:436
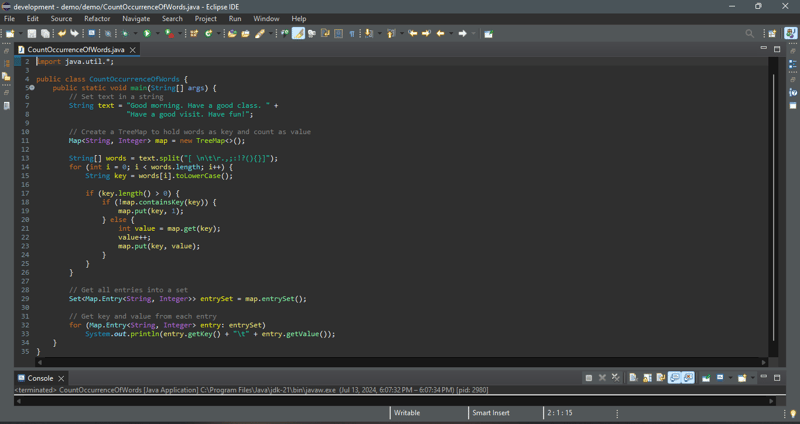
このケーススタディでは、テキスト内の単語の出現をカウントし、単語とその出現を単語のアルファベット順に表示するプログラムを作成します。プログラムは TreeMap を使用して、単語とその数で構成されるエントリを保存します。各単語について、それがすでにマップ内のキーであるかどうかを確認します。そうでない場合は、単語をキー、値 1 を使用してマップにエントリを追加します。それ以外の場合は、マップ内の単語 (キー) の値を 1 だけ増やします。単語は大文字と小文字が区別されないものとします。たとえば、Good は good と同じように扱われます。
以下のコードは問題の解決策を示します。
a 2
クラス1
楽しい1
良い 3
3 つあります
朝1
訪問 1
プログラムは TreeMap (行 11) を作成して、単語のペアとその出現回数を保存します。言葉が鍵となります。マップ内のすべての値はオブジェクトとして保存する必要があるため、カウントは Integer オブジェクトでラップされます。
プログラムは、String クラスの split メソッド (13 行目) を使用してテキストから単語を抽出します。抽出された各単語について、プログラムはその単語がすでにマップにキーとして格納されているかどうかを確認します (18 行目)。そうでない場合は、単語とその初期カウント (1) で構成される新しいペアがマップに保存されます (19 行目)。それ以外の場合、単語のカウントは 1 ずつ増加します (21 ~ 23 行目)。
プログラムはセット内のマップのエントリを取得し (29 行目)、セットを走査して各エントリのカウントとキーを表示します (32 ~ 33 行目)。
マップはツリーマップのため、単語の昇順に表示されます。出現回数の多い順に表示することもできます。ここで落ち着いて、マップを使用せずにこのプログラムをどのように書くかを考えてください。新しいプログラムはより長く、より複雑になります。マップは、このような問題を解決するための非常に効率的で強力なデータ構造であることがわかります。
-
 パンダのデータフレームでコンマ分離された文字列を別々の行に分割するにはどうすればよいですか?コンマ分離されたパンダデータフレーム文字列を別々の行に分割する パンダスデータフレームでは、1つまたは複数の列に個々の列に分割する必要があることがあることがよくあることがよくあります。これを達成するために、 series.explode()またはdataframe.explode() ...プログラミング 2025-03-25に投稿されました
パンダのデータフレームでコンマ分離された文字列を別々の行に分割するにはどうすればよいですか?コンマ分離されたパンダデータフレーム文字列を別々の行に分割する パンダスデータフレームでは、1つまたは複数の列に個々の列に分割する必要があることがあることがよくあることがよくあります。これを達成するために、 series.explode()またはdataframe.explode() ...プログラミング 2025-03-25に投稿されました -
毎日のJavaScript Challenge#js-因子を再帰的に計算します毎日のJavaScriptチャレンジ:要因を再帰的に計算します ちょっと仲間の開発者! ?今日のJavaScriptコーディングチャレンジへようこそ。これらのプログラミングスキルを鋭く保ちましょう! 挑戦 難易度:簡単 トピック:再帰 説...プログラミング 2025-03-25に投稿されました
-
formdata()で複数のファイルアップロードを処理するにはどうすればよいですか?formdata() を使用して複数のファイルアップロードを処理すると、複数のファイルアップロードを処理する必要があることがよくあります。 fd.append("fileToUpload[]", files[x]);メソッドはこの目的に使用でき、単一のリクエストで複数...プログラミング 2025-03-25に投稿されました
-
McRyptからOpenSSLに暗号化を移行し、OpenSSLを使用してMcRyptで暗号化されたデータを復号化できますか?暗号化ライブラリをMcRyptからOpenSSL にアップグレードして、暗号化ライブラリをMcRyptからOpenSLにアップグレードできますか? OpenSSLでは、McRyptで暗号化されたデータを復号化することは可能ですか? 2つの異なる投稿は矛盾する情報を提供します。もしそうなら...プログラミング 2025-03-25に投稿されました
-
さまざまな数の列を持つデータベーステーブルを結合するにはどうすればよいですか?異なる列とのテーブルを組み合わせた ] は、データベーステーブルを異なる列とマージしようとする場合に課題に遭遇する可能性があります。簡単な方法は、列が少ないテーブルに欠落している列にnull値を追加することです。 たとえば、表Aの2つの表Aと表Bを検討してください。表Aには、表Bよりも多く...プログラミング 2025-03-25に投稿されました
-
なぜ私の線形勾配の背景にストライプがあるのか、どうすればそれらを修正できますか?リニアグラデーションからの背景ストライプを追放する 背景に線形勾配プロパティを使用する場合、方向が上または下に設定されているときに顕著なストライプに遭遇する場合があります。これらの見苦しいアーティファクトは、複雑なバックグラウンド伝播現象に起因する可能性があります。その後、線形勾配はこの高...プログラミング 2025-03-25に投稿されました
-
Pandas DataFrame列を日付ごとにデータフレーム形式とフィルターに変換するにはどうすればよいですか?パンダのデータフレーム列をdatetime形式に変換 シナリオ: データは、ストリングを含むさまざまな形式でしばしば存在します。時間データを操作する場合、タイムスタンプは最初は文字列として表示されますが、正確な分析のためにデータタイム形式に変換する必要があります。この関数は、文字列列の予想...プログラミング 2025-03-25に投稿されました
-
Javaの「DD/MM/YYYY HH:MM:SS.SS」形式で現在の日付と時刻を正しく表示するにはどうすればよいですか?「dd/mm/yyyy hh:mm:ss.ss」形式で現在の日付と時刻を表示する方法。異なるフォーマットパターンを持つさまざまなSimpleDateFormatインスタンスの使用にあります。 java.text.simpledateformat; java.util.calendarをインポ...プログラミング 2025-03-25に投稿されました
-
純粋なCSSでは、複数の粘着性要素を互いに積み重ねることができますか?純粋なCSSで複数の粘着性要素を互いに積み重ねることは可能ですか?ここ: https://webthemez.com/demo/sticky-multi-header-scroll/index.html JavaScriptの実装ではなく、純粋なCSSを使用することのみです。複数の粘...プログラミング 2025-03-25に投稿されました
-
マウスクリック時にDiv内のすべてのテキストをプログラム的に選択するにはどうすればよいですか?マウスクリックでプログラムをプログラム的に選択する 質問 テキストコンテンツのdiv要素が与えられた場合、ユーザーは1つのマウスクリックでdiv内のテキスト全体をプログラム的に選択できますか?これにより、ユーザーは選択したテキストを簡単にドラッグアンドドロップしたり、直接コピーしたりできます。...プログラミング 2025-03-25に投稿されました
-
Linuxサーバーにarchive_zipをインストールした後、\ "class \ 'ziparchive \'が見つかりません\"エラーを取得するのはなぜですか?class 'ziparchive' linuxサーバーにarchive_zipをインストールする際のエラーは見つかりません 症状: を実行しようとするときに、Ziparkive follingive folling_zip 0.1.1.1.1.1.1.1.1.1.1.1...プログラミング 2025-03-25に投稿されました
-
なぜsqlalchemyフィルター条項で「flake8」はブールの比較にフラグを立てるのですか?flake8 Flake8 Flake8フラグをフィルター節のブール比較 SQLのブール比較に基づいてクエリ結果をフィルタリングしようとすると、開発者は「==」の使用に関してFLAKE8から警告を発する可能性があります。一般に、「condがfalse」または「condではない場合:」を...プログラミング 2025-03-25に投稿されました
-
Pandas DataFramesで列を効率的に選択するにはどうすればよいですか?Pandas DataFrames の列の選択データ操作タスクを扱うと、特定の列の選択が必要になります。パンダでは、列を選択するためのさまざまなオプションがあります。数値インデックス 列インデックスがわかっている場合、ILOC関数を使用してそれらを選択します。 Pythonインデック...プログラミング 2025-03-25に投稿されました
-
PostgreSQLの各一意の識別子の最後の行を効率的に取得するにはどうすればよいですか?postgresql:各一意の識別子の最後の行 を抽出します。次のデータを検討してください: select distinct on (id) id, date, another_info from the_table order by id, date desc; データセット内の一...プログラミング 2025-03-25に投稿されました
-
CSS「コンテンツ」プロパティを使用してFirefoxが画像を表示しないのはなぜですか?firefox のコンテンツURLを使用して画像を表示します。これは、提供されたCSSクラスで見ることができます: .googlePic { content: url('../../img/googlePlusIcon.PNG'); margin-top: -6.5%;...プログラミング 2025-03-25に投稿されました















中国語を勉強する
- 1 「歩く」は中国語で何と言いますか? 走路 中国語の発音、走路 中国語学習
- 2 「飛行機に乗る」は中国語で何と言いますか? 坐飞机 中国語の発音、坐飞机 中国語学習
- 3 「電車に乗る」は中国語で何と言いますか? 坐火车 中国語の発音、坐火车 中国語学習
- 4 「バスに乗る」は中国語で何と言いますか? 坐车 中国語の発音、坐车 中国語学習
- 5 中国語でドライブは何と言うでしょう? 开车 中国語の発音、开车 中国語学習
- 6 水泳は中国語で何と言うでしょう? 游泳 中国語の発音、游泳 中国語学習
- 7 中国語で自転車に乗るってなんて言うの? 骑自行车 中国語の発音、骑自行车 中国語学習
- 8 中国語で挨拶はなんて言うの? 你好中国語の発音、你好中国語学習
- 9 中国語でありがとうってなんて言うの? 谢谢中国語の発音、谢谢中国語学習
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









