
コンピューター上で RTX AI チャットボットを使用して Nvidia のチャットを使用する方法
 ブラウズ:805
ブラウズ:805
Nvidia は、PC 上で動作し、ChatGPT などと同様の機能を提供する AI チャットボットである Chat with RXT を開始しました。必要なのは Nvidia RTX GPU だけで、Nvidia の新しい AI チャットボットを使い始める準備は完了です。
RTX を使用した Nvidia チャットとは何ですか?
Nvidia Chat with RTX は、大規模言語モデル (LLM) をコンピューター上でローカルに実行できる AI ソフトウェアです。そのため、ChatGPT のような AI チャットボットをオンラインで使用する代わりに、いつでもオフラインで Chat with RTX を使用できます。
RTX とのチャットは、TensorRT-LLM、RTX アクセラレーション、および量子化された Mistral 7-B LLM を使用して、他のオンライン AI チャットボットと同等の高速パフォーマンスと高品質の応答を提供します。また、検索拡張生成 (RAG) も提供し、チャットボットがファイルを読み取って、提供されたデータに基づいてカスタマイズされた回答を可能にすることができます。これにより、チャットボットをカスタマイズして、より個人的なエクスペリエンスを提供できるようになります。
Nvidia Chat を RTX で試してみたい場合は、コンピューターにダウンロード、インストール、構成する方法を次に示します。
RTX でチャットをダウンロードしてインストールする方法

Nvidia により、コンピューター上でローカルに LLM を実行することがはるかに簡単になりました。 Chat with RTX を実行するには、他のソフトウェアと同様に、アプリをダウンロードしてインストールするだけです。ただし、Chat with RTX を適切にインストールして使用するには、いくつかの最小仕様要件があります。
RTX 30 シリーズまたは 40 シリーズ GPU 16 GB RAM 100 GB の空きメモリ容量 Windows 11PC が最小システム要件を満たしている場合は、アプリをインストールできます。
ステップ 1: Chat with RTX ZIP ファイルをダウンロードします。ダウンロード: Chat with RTX (無料 - 35GB ダウンロード)ステップ 2: 右クリックして 7Zip などのファイル アーカイブ ツールを選択して、ZIP ファイルを解凍します。または、ファイルをダブルクリックして「すべて展開」を選択します。ステップ 3: 解凍したフォルダーを開き、setup.exe をダブルクリックします。画面上の指示に従い、カスタム インストール プロセス中にすべてのボックスをオンにします。 [次へ] をクリックすると、インストーラーは LLM とすべての依存関係をダウンロードしてインストールします。
Chat with RTX のインストールは、大量のデータをダウンロードしてインストールするため、完了するまでに時間がかかります。インストールプロセスが完了したら、「閉じる」をクリックして完了です。今度は、アプリを試してみましょう。
Nvidia Chat with RTX を使用する方法
Chat with RTX は通常のオンライン AI チャットボットのように使用できますが、RAG 機能を確認することを強くお勧めします。これにより、出力ベースでカスタマイズできるようになります。アクセスを許可したファイルに適用されます。
ステップ 1: RAG フォルダーの作成
RTX とのチャットで RAG の使用を開始するには、AI に分析させたいファイルを保存する新しいフォルダーを作成します。
作成後、データ ファイルをフォルダーに配置します。保存するデータには、ドキュメント、PDF、テキスト、ビデオなど、さまざまなトピックやファイル タイプが含まれます。ただし、パフォーマンスに影響を与えないように、このフォルダーに配置するファイルの数を制限することもできます。検索するデータが増えると、RTX とチャットすると、特定のクエリに対する応答が返されるまでに時間がかかります (ただし、これはハードウェアにも依存します)。
これでデータベースの準備ができました。RTX でチャットをセットアップし、質問やクエリに答えるために使用を開始できます。
ステップ 2: 環境をセットアップする
RTX でチャットを開きます。以下の画像のようになります。
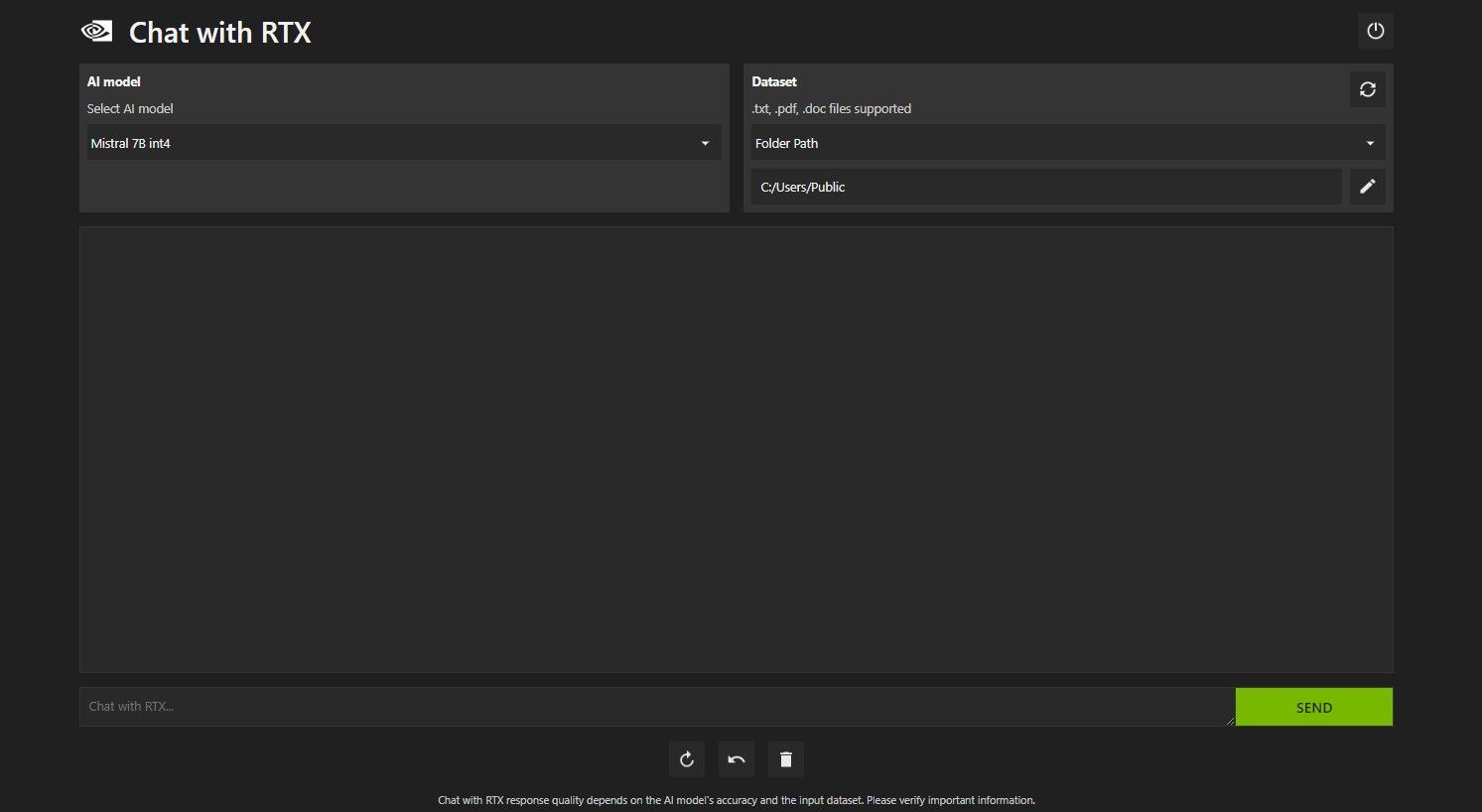
[データセット] で、[フォルダー パス] オプションが選択されていることを確認します。次に、下の編集アイコン (ペンのアイコン) をクリックし、Chat with RTX に読み取らせたいすべてのファイルが含まれるフォルダーを選択します。他のオプションが利用可能な場合は、AI モデルを変更することもできます (執筆時点では、Mistral 7B のみが利用可能です)。
これで、RTX でチャットを使用する準備ができました。
ステップ 3: RTX にチャットで質問してください!
RTX で Chat をクエリするにはいくつかの方法があります。 1つ目は、通常のAIチャットボットのように使用することです。 Chat with RTX にローカル LLM を使用する利点について尋ねたところ、その答えに満足しました。それほど詳しくはありませんでしたが、十分正確でした。
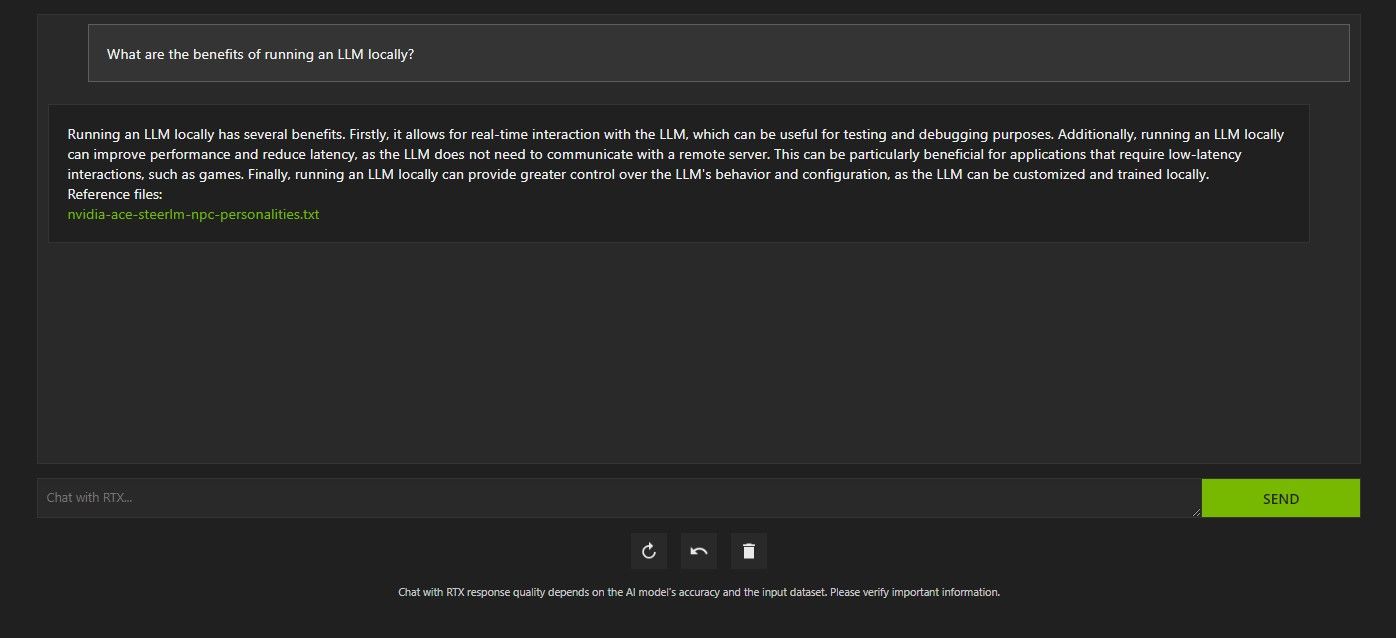
ただし、Chat with RTX は RAG に対応しているため、パーソナル AI アシスタントとしても使用できます。
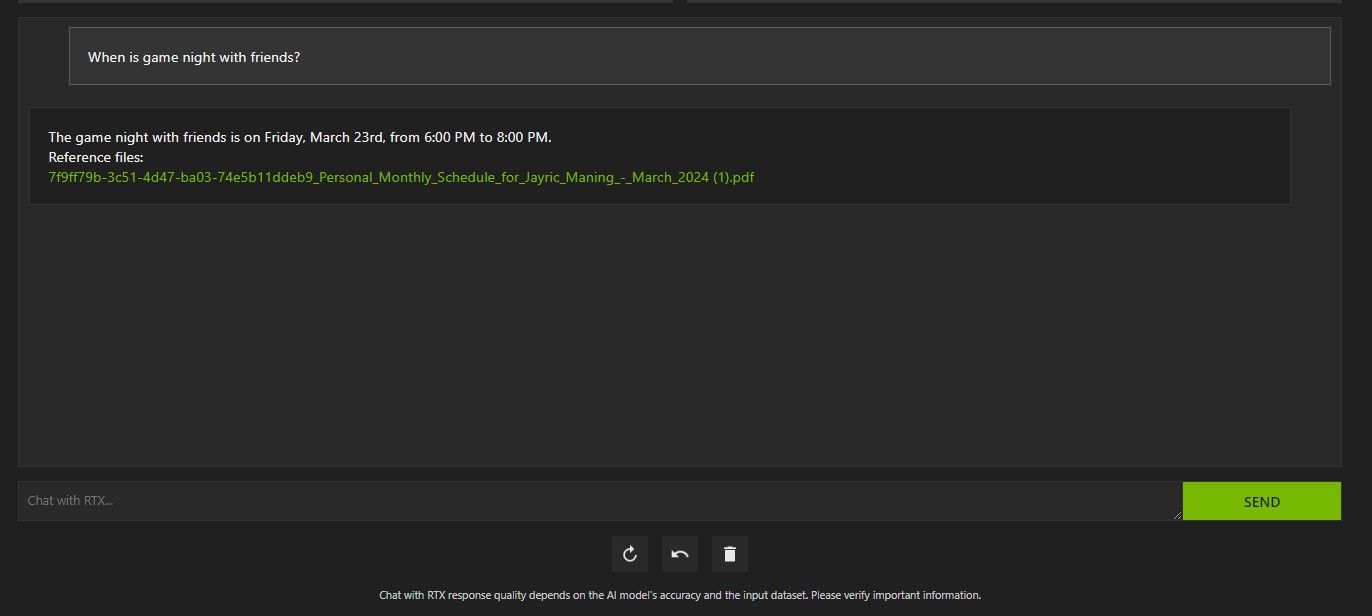
上記では、RTX とのチャットを使用してスケジュールについて尋ねました。データは、スケジュール、カレンダー、イベント、仕事などが含まれた PDF ファイルからのものでした。この場合、Chat with RTX はデータから正しいカレンダー データを取得しています。他のアプリと統合されるまで、このような機能が適切に動作するには、データ ファイルとカレンダーの日付を最新の状態に保つ必要があります。
RTX の RAG を使用してチャットを有利に活用できる方法はたくさんあります。たとえば、法律文書を読んで概要を示したり、開発中のプログラムに関連するコードを生成したり、忙しくて見られないビデオのハイライトを箇条書きで取得したりするために使用できます。
ステップ 4: ボーナス機能
ローカル データ フォルダーに加えて、Chat with RTX を使用して YouTube ビデオを分析できます。これを行うには、[データセット] で、フォルダー パスを YouTube URL に変更します。
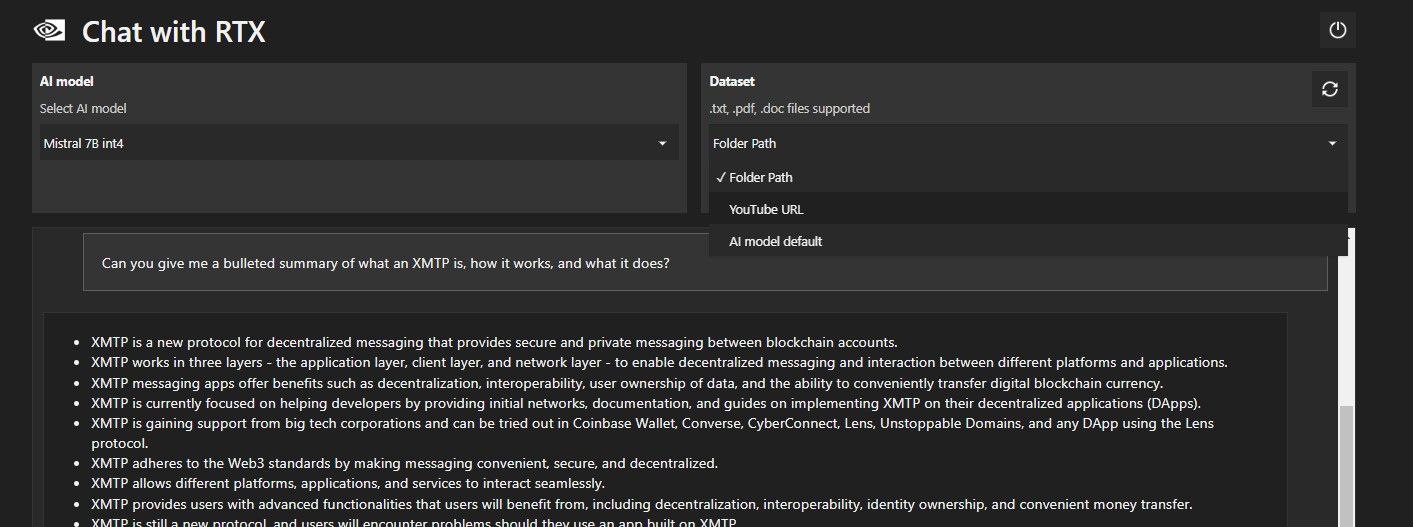
分析したい YouTube URL をコピーし、ドロップダウン メニューの下に貼り付けます。それなら聞いてください!
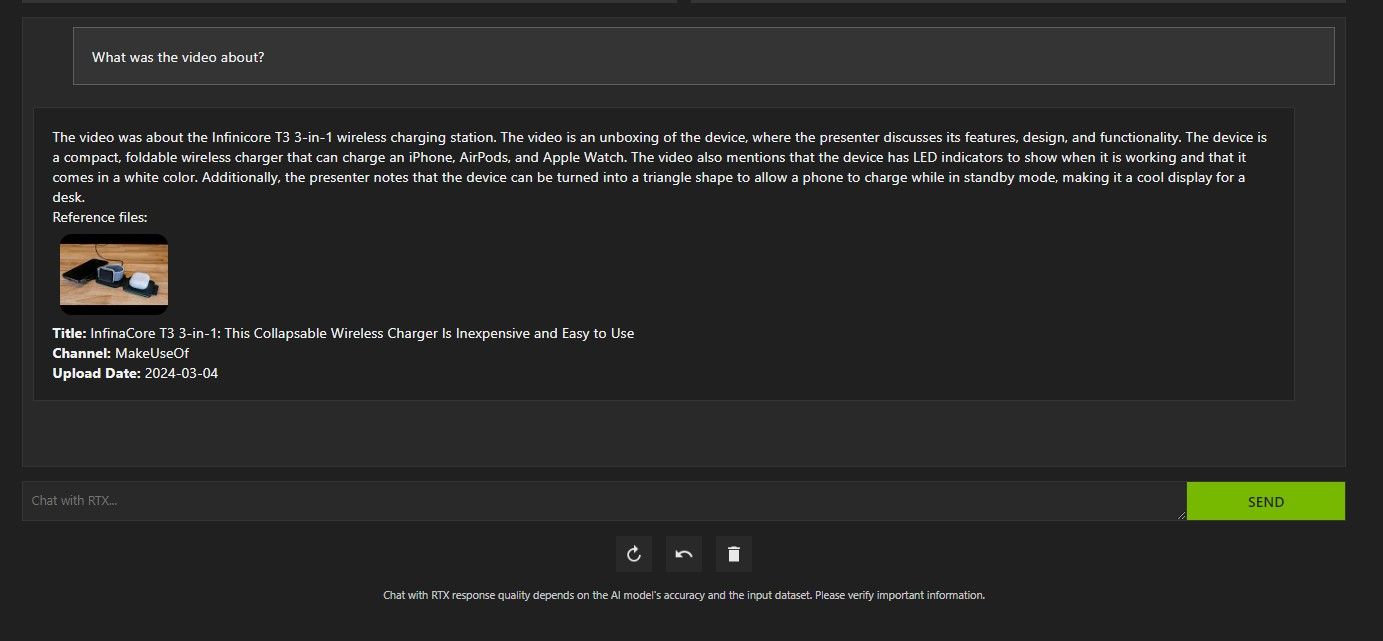
Chat with RTX の YouTube ビデオ分析は非常に優れており、正確な情報が提供されたため、調査や迅速な分析などに便利です。
Nvidia の RTX とのチャットは役に立ちますか?
ChatGPT は RAG 機能を提供します。一部のローカル AI チャットボットのシステム要件は大幅に低くなります。では、RTX を使用した Nvidia Chat は使用する価値がありますか?
答えはイエスです! RTX とのチャットは、競合にもかかわらず使用する価値があります。
RTX で Nvidia Chat を使用する最大のセールス ポイントの 1 つは、ファイルをサードパーティ サーバーに送信せずに RAG を使用できることです。オンライン サービスを通じて GPT をカスタマイズすると、データが公開される可能性があります。ただし、Chat with RTX はインターネット接続なしでローカルで実行されるため、Chat with RTX で RAG を使用すると、機密データは安全であり、PC 上でのみアクセスできることが保証されます。
Mistral 7B を実行し、ローカルで実行されている他の AI チャットボットと同様に、Chat with RTX のパフォーマンスが向上し、高速になります。パフォーマンス向上の大部分はハイエンド GPU の使用によるものですが、Nvidia TensorRT-LLM と RTX アクセラレーションの使用により、チャットに最適化された LLM を実行する他の方法と比較して、RTX とのチャットでの Mistral 7B の実行が高速になりました。
現在使用している Chat with RTX バージョンはデモであることに注意してください。 Chat with RTX の今後のリリースでは、より最適化され、パフォーマンスが向上する可能性があります。
RTX 30 または 40 シリーズ GPU がない場合はどうすればよいですか?
RTX とのチャットは、インターネット接続を必要とせずにローカルで LLM を実行する簡単、高速、安全な方法です。 LLM またはローカルでの実行にも興味があるが、RTX 30 または 40 シリーズ GPU を持っていない場合は、ローカルで LLM を実行する他の方法を試すことができます。最も人気のあるものの 2 つは、GPT4ALL と Text Gen WebUI です。 LLM をローカルで実行するプラグアンドプレイ エクスペリエンスが必要な場合は、GPT4ALL を試してください。ただし、もう少し技術的な傾向がある場合は、Text Gen WebUI を通じて LLM を実行すると、より優れた微調整と柔軟性が得られます。
-
 Swarm Intelligence Algorithms:3つのPython実装Imagine watching a flock of birds in flight. There's no leader, no one giving directions, yet they swoop and glide together in perfect harmony. It may...AI 2025-03-24に投稿されました
Swarm Intelligence Algorithms:3つのPython実装Imagine watching a flock of birds in flight. There's no leader, no one giving directions, yet they swoop and glide together in perfect harmony. It may...AI 2025-03-24に投稿されました -
ラグ&微調整によりLLMをより正確にする方法Imagine studying a module at university for a semester. At the end, after an intensive learning phase, you take an exam – and you can recall th...AI 2025-03-24に投稿されました
-
Google Geminiとは何ですか? GoogleのChatGptのライバルについて知る必要があるすべてGoogle recently released its new Generative AI model, Gemini. It results from a collaborative effort by a range of teams at Google, including members ...AI 2025-03-23に投稿されました
-
DSPYでのプロンプトのガイドdspy:LLMアプリケーションを構築および改善するための宣言的なフレームワーク dspy(宣言的自己改善言語プログラム)は、迅速なエンジニアリングの複雑さを抽象化することにより、LLMアプリケーション開発に革命をもたらします。 このチュートリアルは、DSPYの宣言的アプローチを使用して強力な...AI 2025-03-22に投稿されました
-
ブログをTwitterスレッドに自動化しますこの記事では、GoogleのGemini-2.0 LLM、Chromadb、およびRiremlitを使用して、長型コンテンツ(ブログ投稿など)のTwitterスレッドの魅力を自動化することを詳しく説明しています。 手動スレッドの作成には時間がかかります。このアプリケーションはプロセスを合理化します...AI 2025-03-11に投稿されました
-
人工免疫系(AIS):Pythonの例を備えたガイドこの記事では、脅威を特定し、中和する人間の免疫系の顕著な能力に触発された計算モデルである人工免疫システム(AIS)を探ります。 AISのコア原則を掘り下げ、クローン選択、ネガティブ選択、免疫ネットワーク理論などの重要なアルゴリズムを調べ、Pythonコードの例でそれらのアプリケーションを説明します...AI 2025-03-04に投稿されました
-
ChatGPT に自分自身についての楽しい質問をしてみてくださいChatGPT があなたについて何を知っているのか疑問に思ったことはありますか?時間をかけて与えられた情報をどのように処理するのでしょうか?私はさまざまなシナリオで ChatGPT ヒープを使用してきましたが、特定のインタラクションの後にそのヒープが何を言うのかを見るのは常に興味深いものです。&#x...AI 2024 年 11 月 22 日に公開
-
謎の GPT-2 チャットボットをまだ試す方法は次のとおりですAI モデルやチャットボットに興味がある場合は、謎の GPT-2 チャットボットとその有効性に関する議論を見たことがあるかもしれません。ここでは、GPT-2 チャットボットとは何か、およびその方法について説明します。 GPT-2 チャットボットとは何ですか? 2024 年 4 月下旬、gpt2-c...AI 2024 年 11 月 8 日に公開
-
ChatGPT のキャンバス モードは素晴らしい: 4 つの使用方法ChatGPT の新しい Canvas モードは、世界をリードする生成 AI ツールでの書き込みと編集にさらなる次元を追加しました。私は ChatGPT Canvas の発売以来使用してきましたが、この新しい AI ツールを使用するためのいくつかの異なる方法を見つけました。✕ 広告の削除...AI 2024 年 11 月 8 日に公開
-
ChatGPT のカスタム GPT がデータを公開する仕組みとその安全性を保つ方法ChatGPT のカスタム GPT 機能を使用すると、誰でも思いつく限りのほとんどすべてのカスタム AI ツールを作成できます。クリエイティブ、テクニカル、ゲーム、カスタム GPT はすべてを行うことができます。さらに良いのは、カスタム GPT 作成を誰とでも共有できることです。 ただし、カスタ...AI 2024 年 11 月 8 日に公開
-
ChatGPT が LinkedIn での仕事の獲得に役立つ 10 の方法2,600 文字が利用できる LinkedIn プロフィールの About セクションは、あなたの経歴、スキル、情熱、将来の目標について詳しく説明するのに最適なスペースです。 LinkedIn の経歴を、あなたの職業上の背景、スキル、願望を簡潔にまとめたものとして表示します。 ChatGPT に...AI 2024 年 11 月 8 日に公開
-
ユニークなエクスペリエンスを提供する、あまり知られていない 6 つの AI アプリをチェックしてください現時点では、AI ブームをリードしてきた 2 つの先駆的な生成 AI アプリである ChatGPT と Copilot については、ほとんどの人が聞いたことがあるでしょう。しかし、あまり知られていない AI ツールの山が素晴らしい、ユニークな体験?ここでは最高のものを 6 つ紹介します。 1 同上ミ...AI 2024 年 11 月 8 日に公開
-
これらの 7 つの兆候は、AI がすでにピークに達していることを示していますオンラインでどこを見ても、AI の使用が最良の選択肢になると宣言するサイト、サービス、アプリがあります。あなたはどうか知りませんが、常に存在していると疲れてきます。 AI は確かに私たちの日常生活に定着していますが、AI の誇大宣伝がすでにピークに達していることを示す兆候がいくつかあります。 1 一...AI 2024 年 11 月 8 日に公開
-
教師、講師、上司向けの 4 つの AI チェック ChatGPT 検出ツールChatGPT の性能が向上するにつれて、何が人間によって書かれ、何が AI によって生成されたかを区別することがますます困難になってきています。そのため、教師や上司が、人間の手によって書かれたものと、ChatGPT を通じて生成されたものを識別することが困難になります。 違いを見分けるのが難し...AI 2024 年 11 月 8 日に公開
-
ChatGPT の高度な音声機能がより多くのユーザーに展開されますChatGPT で本格的な会話をしたいと思ったことがあるなら、今ならそれが可能です。つまり、ChatGPT を使用する特権に対して料金を支払っている限りです。より多くの有料ユーザーが ChatGPT の高度な音声モード (AVM) にアクセスできるようになりました。これは、ChatGPT との対話を...AI 2024 年 11 月 8 日に公開















中国語を勉強する
- 1 「歩く」は中国語で何と言いますか? 走路 中国語の発音、走路 中国語学習
- 2 「飛行機に乗る」は中国語で何と言いますか? 坐飞机 中国語の発音、坐飞机 中国語学習
- 3 「電車に乗る」は中国語で何と言いますか? 坐火车 中国語の発音、坐火车 中国語学習
- 4 「バスに乗る」は中国語で何と言いますか? 坐车 中国語の発音、坐车 中国語学習
- 5 中国語でドライブは何と言うでしょう? 开车 中国語の発音、开车 中国語学習
- 6 水泳は中国語で何と言うでしょう? 游泳 中国語の発音、游泳 中国語学習
- 7 中国語で自転車に乗るってなんて言うの? 骑自行车 中国語の発音、骑自行车 中国語学習
- 8 中国語で挨拶はなんて言うの? 你好中国語の発音、你好中国語学習
- 9 中国語でありがとうってなんて言うの? 谢谢中国語の発音、谢谢中国語学習
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









