
Llama 2 をローカルにダウンロードしてインストールする方法
 ブラウズ:626
ブラウズ:626
これを念頭に置いて、Text-Generation-WebUI を使用して量子化された Llama 2 LLM をコンピューターにローカルにロードする方法に関するステップバイステップのガイドを作成しました。
Llama 2 をローカルにインストールする理由
Llama 2 を直接実行することを選択する理由はたくさんあります。プライバシーを考慮してこれを行うものもあれば、カスタマイズを目的とするもの、オフライン機能を目的として行うものもあります。プロジェクトに合わせて Llama 2 を研究、微調整、または統合している場合、API 経由で Llama 2 にアクセスすることは適していない可能性があります。 LLM を PC 上でローカルに実行することのポイントは、サードパーティの AI ツールへの依存を減らし、企業や他の組織に機密データが漏洩する可能性を心配することなく、いつでもどこでも AI を使用できるようになることです。
そうは言っても、Llama 2 をローカルにインストールするためのステップバイステップ ガイドから始めましょう。
ステップ 1: Visual Studio 2019 ビルド ツールをインストールする
話を簡単にするために、Text-Generation-WebUI (GUI で Llama 2 をロードするために使用されるプログラム) のワンクリック インストーラーを使用します。 。ただし、このインストーラーが機能するには、Visual Studio 2019 Build Tool をダウンロードし、必要なリソースをインストールする必要があります。
ダウンロード:Visual Studio 2019 (無料)
先に進み、ソフトウェアのコミュニティ エディションをダウンロードしてください。 次に、Visual Studio 2019 をインストールし、ソフトウェアを開きます。開いたら、[C によるデスクトップ開発] のボックスにチェックを入れて、インストールを押します。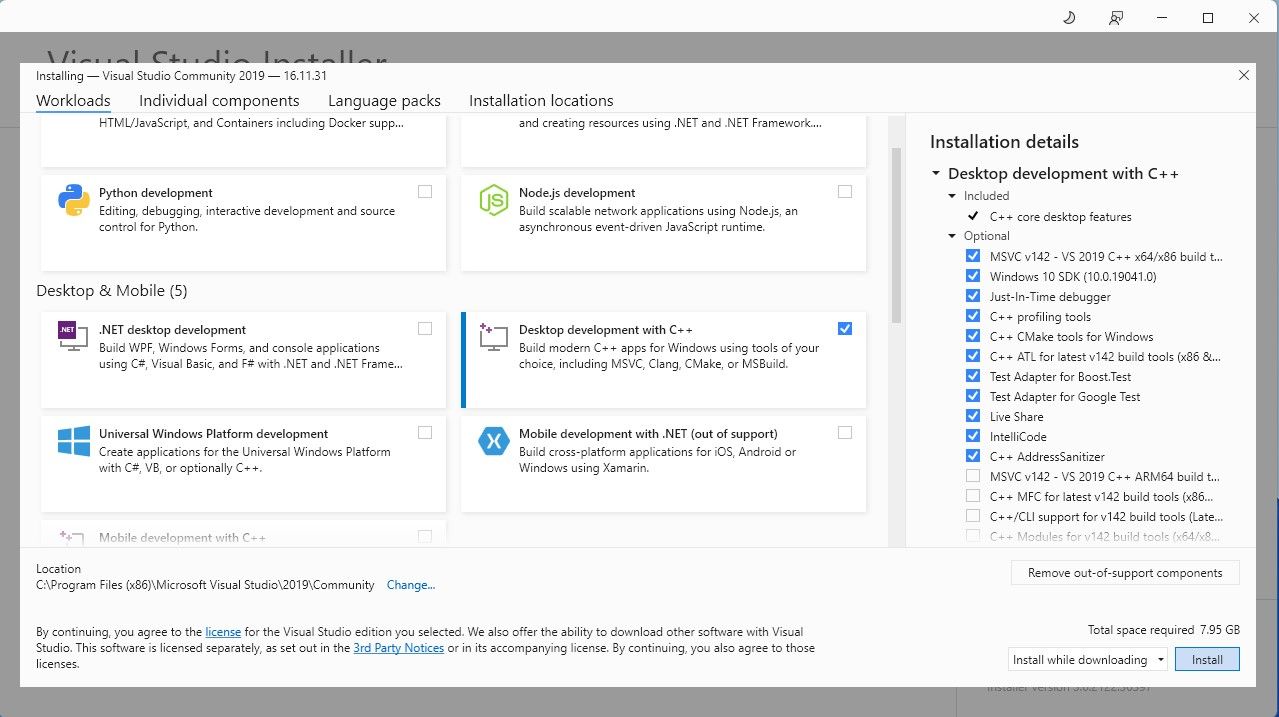
C によるデスクトップ開発がインストールされたので、Text-Generation-WebUI ワンクリック インストーラーをダウンロードします。
ステップ 2: Text-Generation-WebUI をインストールする
Text-Generation-WebUI のワンクリック インストーラーは、必要なフォルダーを自動的に作成し、Conda 環境と必要なすべての要件をセットアップするスクリプトです。 AI モデルを実行します。
スクリプトをインストールするには、[コード] > [ZIP のダウンロード] をクリックして、ワンクリック インストーラーをダウンロードします。
ダウンロード:Text-Generation-WebUI インストーラー (無料)
ダウンロードしたら、ZIP ファイルを任意の場所に解凍し、解凍したフォルダーを開きます。 フォルダー内で下にスクロールして、オペレーティング システムに適した起動プログラムを探します。適切なスクリプトをダブルクリックしてプログラムを実行します。 Windows を使用している場合は、MacOS の場合は start_windows バッチ ファイルを選択し、Linux の場合は start_macos シェル スクリプトを選択し、start_linux シェル スクリプトを選択します。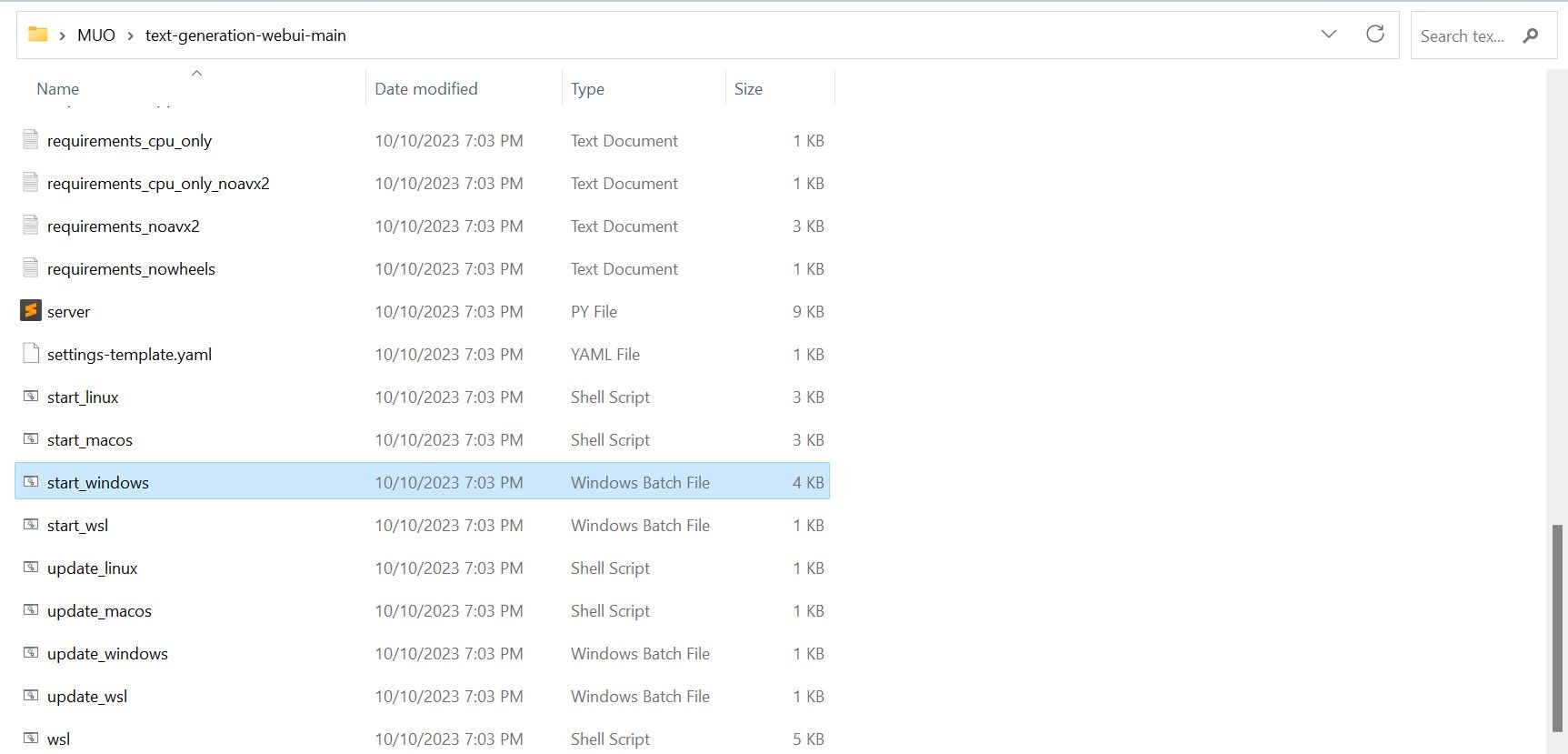
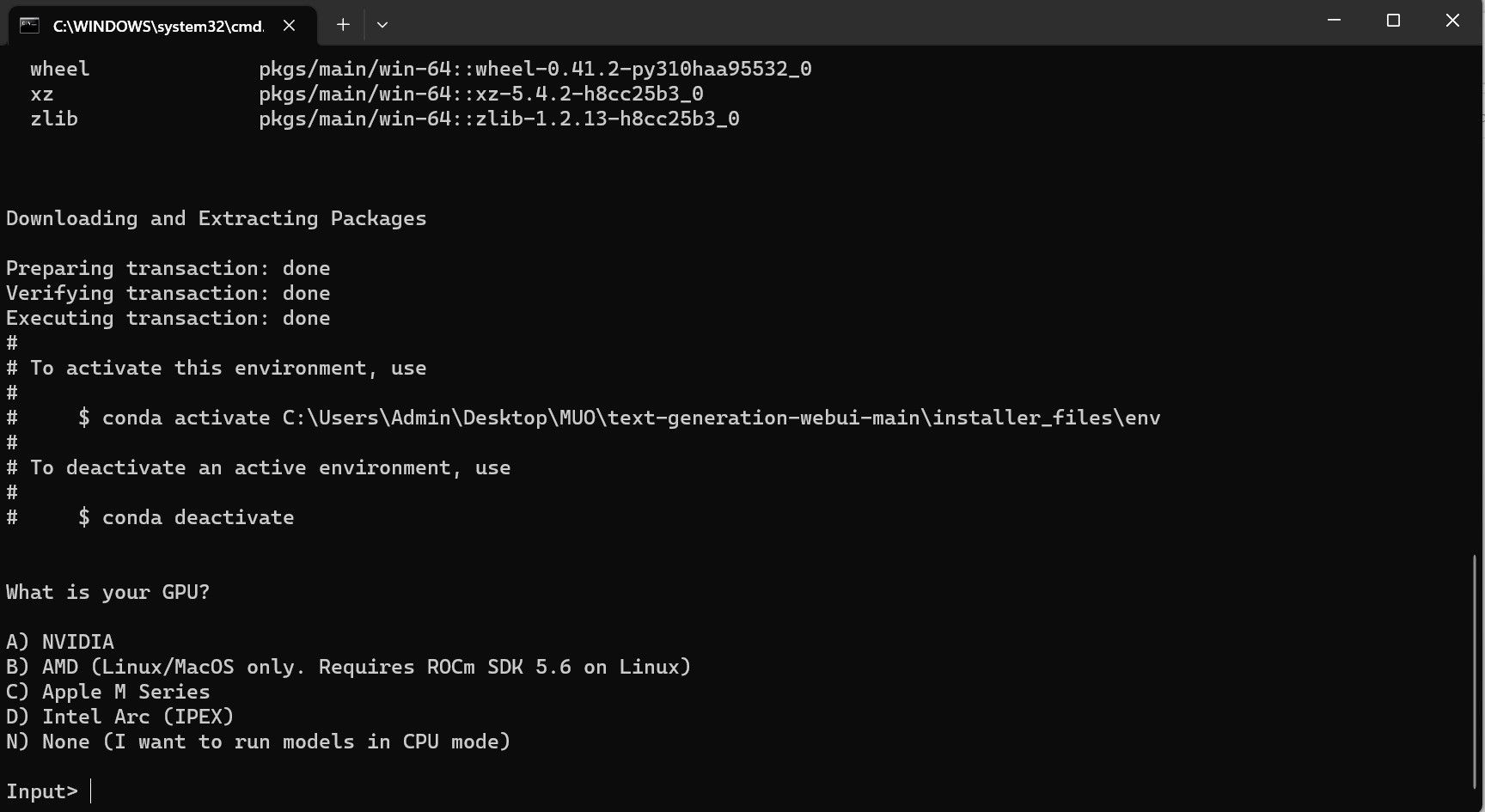
ウイルス対策ソフトによってアラートが作成される可能性があります。これは大丈夫です。このプロンプトは、バッチ ファイルまたはスクリプトを実行するためのウイルス対策の誤検知です。 「とにかく実行」をクリックします。 ターミナルが開き、セットアップが開始されます。初期段階では、セットアップが一時停止し、使用している GPU を尋ねられます。コンピューターにインストールされている適切なタイプの GPU を選択し、Enter キーを押します。専用のグラフィックス カードがない場合は、[なし] (モデルを CPU モードで実行したい) を選択します。 CPU モードでの実行は、専用 GPU でモデルを実行する場合に比べてはるかに遅いことに注意してください。
 セットアップが完了すると、Text-Generation-WebUI をローカルで起動できるようになります。これを行うには、お好みの Web ブラウザを開いて、指定された IP アドレスを URL に入力します。
セットアップが完了すると、Text-Generation-WebUI をローカルで起動できるようになります。これを行うには、お好みの Web ブラウザを開いて、指定された IP アドレスを URL に入力します。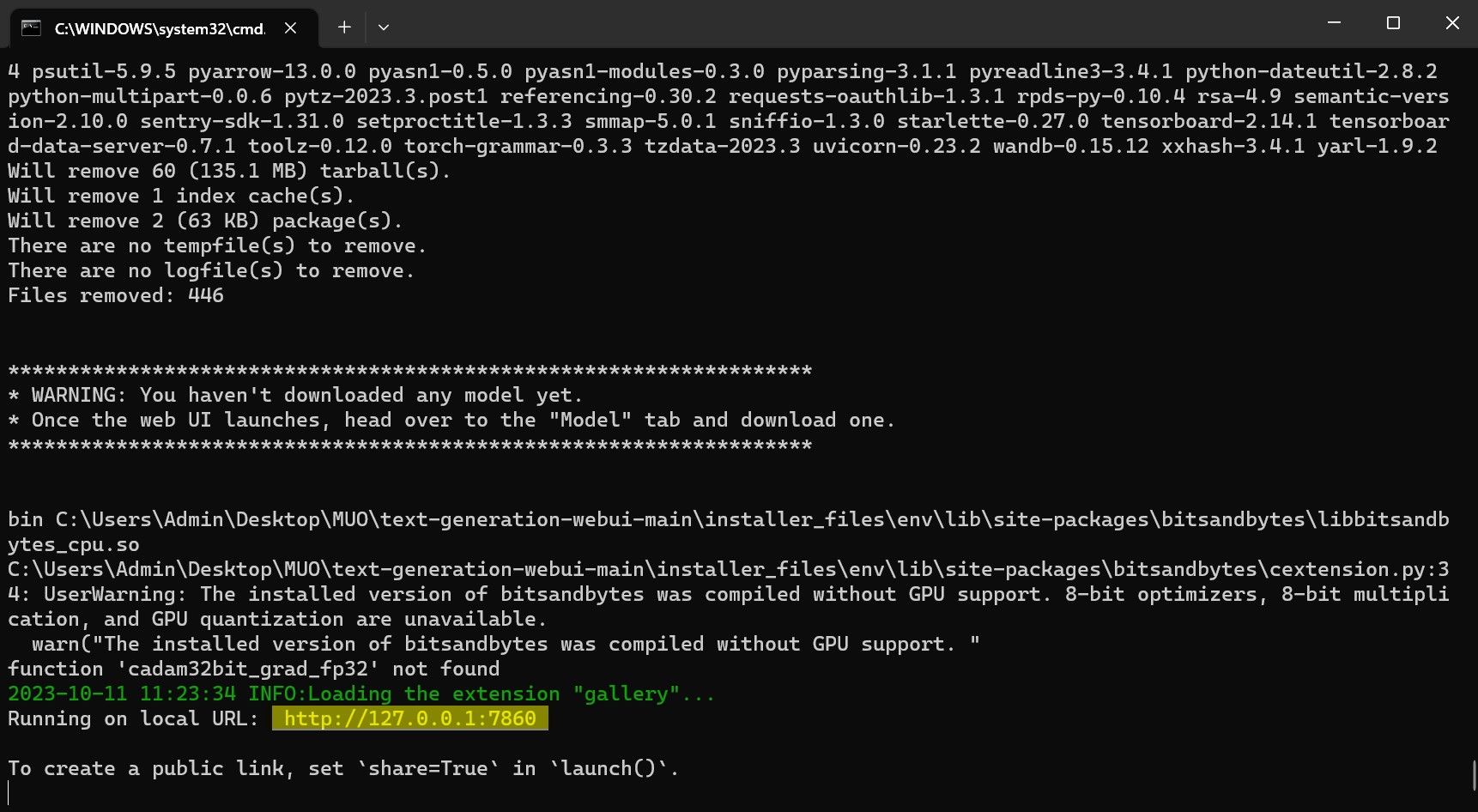 WebUI を使用する準備ができました。
WebUI を使用する準備ができました。
ただし、プログラムは単なるモデル ローダーです。モデルローダーを起動するために Llama 2 をダウンロードしましょう。
ステップ 3: Llama 2 モデルをダウンロードする
Llama 2 のどのイテレーションが必要かを決定する際には、考慮すべきことがかなり多くあります。これらには、パラメーター、量子化、ハードウェアの最適化、サイズ、使用法が含まれます。これらの情報はすべてモデル名に示されています。
パラメータ: モデルのトレーニングに使用されるパラメータの数。パラメータが大きいほどモデルの機能は向上しますが、パフォーマンスが犠牲になります。使用法: 標準またはチャットのいずれかです。チャット モデルは、ChatGPT のようなチャットボットとして使用するために最適化されていますが、標準がデフォルトのモデルです。ハードウェアの最適化: モデルを最適に実行するハードウェアを指します。 GPTQ はモデルが専用 GPU で実行するように最適化されているのに対し、GGML は CPU で実行するように最適化されていることを意味します。量子化: モデル内の重みとアクティベーションの精度を示します。推論の場合、q4 の精度が最適です。サイズ: 特定のモデルのサイズを指します。一部の機種では配置が異なったり、同じ種類の情報が表示されない場合がありますのでご注意ください。ただし、このタイプの命名規則は HuggingFace Model ライブラリではかなり一般的であるため、理解しておく価値はあります。

この例では、モデルは、専用 CPU を使用してチャット推論用に最適化された 130 億のパラメーターでトレーニングされた中型の Llama 2 モデルとして識別できます。
専用 GPU で実行している場合は GPTQ モデルを選択し、CPU を使用している場合は GGML を選択します。 ChatGPT と同じようにモデルとチャットしたい場合はチャットを選択しますが、モデルの全機能を試してみたい場合は標準モデルを使用してください。パラメーターに関しては、より大きなモデルを使用すると、パフォーマンスが犠牲になりますが、より良い結果が得られることに注意してください。個人的には7Bモデルから始めることをお勧めします。量子化については、推論専用なので q4 を使用します。
ダウンロード:GGML (無料)
ダウンロード:GPTQ (無料)
必要な Llama 2 のイテレーションがわかったので、必要なモデルをダウンロードしてください。
私の場合、これをウルトラブック上で実行しているため、チャット用に微調整された GGML モデル、llama-2-7b-chat-ggmlv3.q4_K_S.bin を使用します。
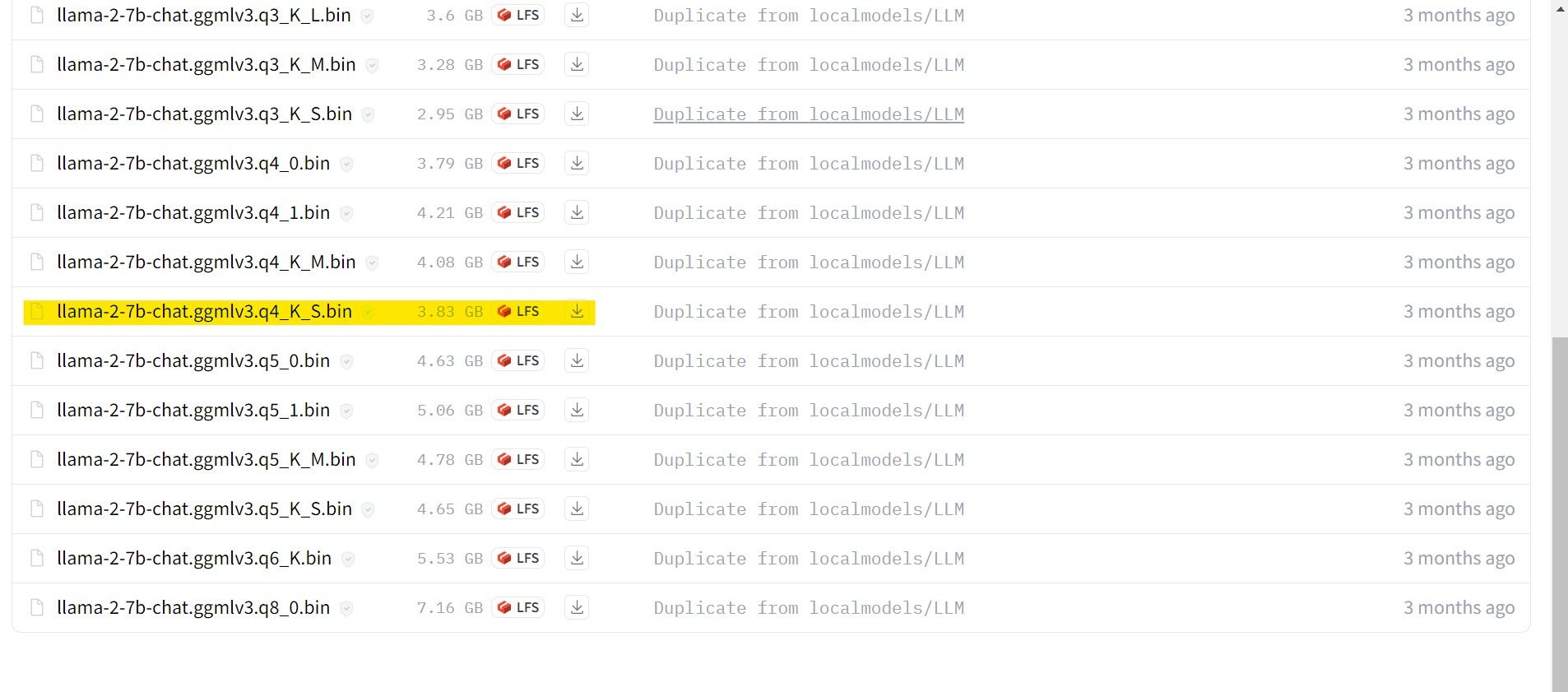
ダウンロードが完了したら、text-generation-webui-main > models にモデルを配置します。
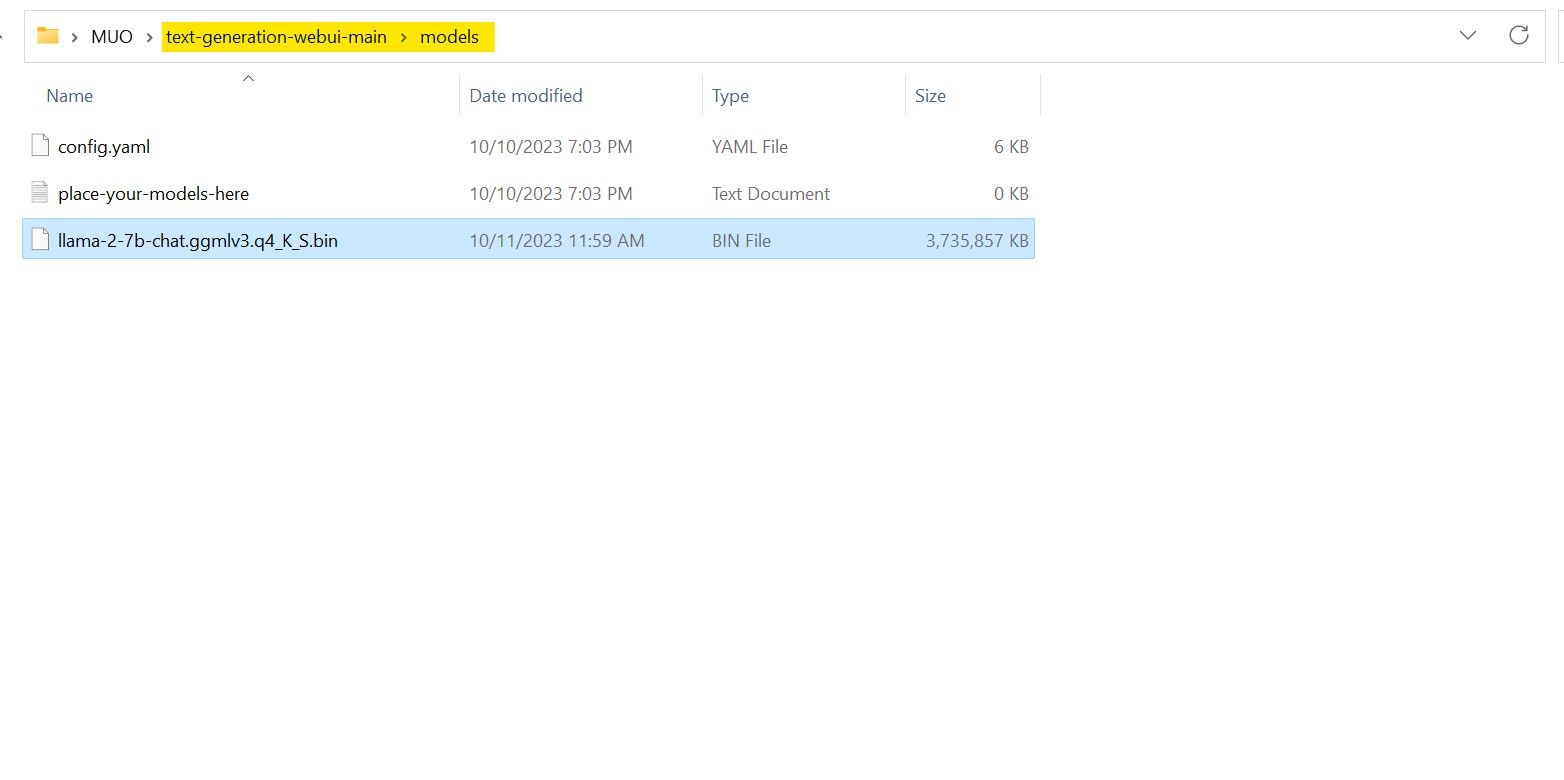
モデルをダウンロードしてモデル フォルダーに配置したので、モデル ローダーを構成します。
ステップ 4: Text-Generation-WebUI を構成する
次に、構成フェーズを開始しましょう。
もう一度、start_(OS) ファイルを実行して Text-Generation-WebUI を開きます (上記の前の手順を参照)。 GUI の上にあるタブで、「モデル」をクリックします。モデルのドロップダウン メニューで更新ボタンをクリックし、モデルを選択します。 次に、モデル ローダーのドロップダウン メニューをクリックし、GTPQ モデルを使用する場合は AutoGPTQ を選択し、GGML モデルを使用する場合は ctransformers を選択します。最後に、[ロード] をクリックしてモデルをロードします。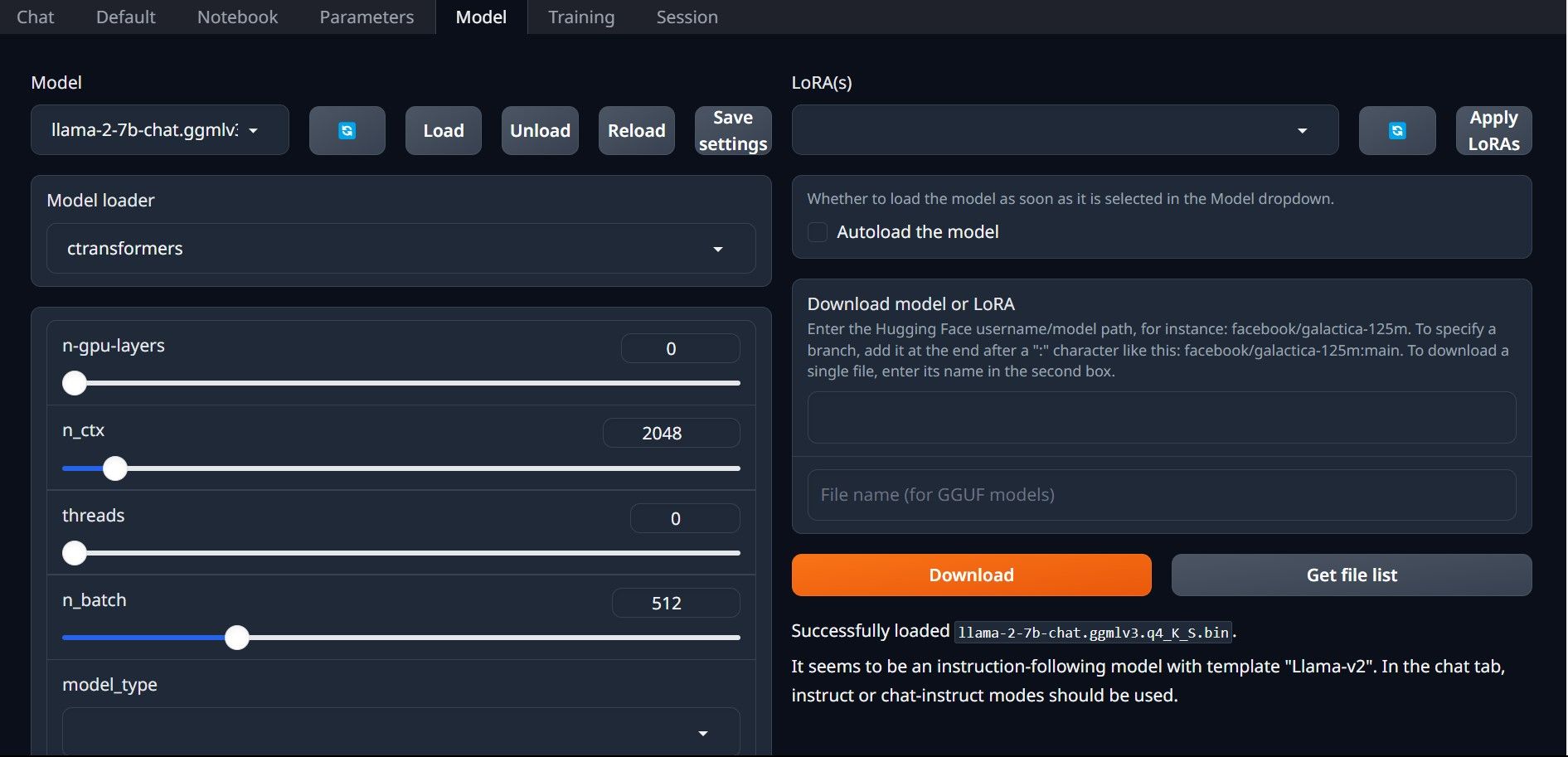 モデルを使用するには、[チャット] タブを開いてモデルのテストを開始します。
モデルを使用するには、[チャット] タブを開いてモデルのテストを開始します。
おめでとうございます。ローカル コンピュータに Llama2 が正常にロードされました。
他の LLM を試してみる
Text-Generation-WebUI を使用してコンピュータ上で Llama 2 を直接実行する方法がわかったので、Llama 以外の LLM も実行できるはずです。モデルの命名規則と、量子化されたモデル (通常は q4 精度) のみが通常の PC にロードできることを覚えておいてください。多くの量子化 LLM が HuggingFace で入手できます。他のモデルを調べたい場合は、HuggingFace のモデル ライブラリで TheBloke を検索すると、利用可能なモデルが多数見つかるはずです。
-
 気流とDockerを使用してCSVのインポートをPostgreSQLに自動化するこのチュートリアルは、Apache Airflow、Docker、およびPostgreSQLを使用して堅牢なデータパイプラインを構築して、CSVファイルからデータベースへのデータ転送を自動化することを示しています。 効率的なワークフロー管理のために、DAG、タスク、演算子などのコアエアフローの概念...AI 2025-04-12に投稿されました
気流とDockerを使用してCSVのインポートをPostgreSQLに自動化するこのチュートリアルは、Apache Airflow、Docker、およびPostgreSQLを使用して堅牢なデータパイプラインを構築して、CSVファイルからデータベースへのデータ転送を自動化することを示しています。 効率的なワークフロー管理のために、DAG、タスク、演算子などのコアエアフローの概念...AI 2025-04-12に投稿されました -
Swarm Intelligence Algorithms:3つのPython実装Imagine watching a flock of birds in flight. There's no leader, no one giving directions, yet they swoop and glide together in perfect harmony. It may...AI 2025-03-24に投稿されました
-
ラグ&微調整によりLLMをより正確にする方法Imagine studying a module at university for a semester. At the end, after an intensive learning phase, you take an exam – and you can recall th...AI 2025-03-24に投稿されました
-
Google Geminiとは何ですか? GoogleのChatGptのライバルについて知る必要があるすべてGoogle recently released its new Generative AI model, Gemini. It results from a collaborative effort by a range of teams at Google, including members ...AI 2025-03-23に投稿されました
-
DSPYでのプロンプトのガイドdspy:LLMアプリケーションを構築および改善するための宣言的なフレームワーク dspy(宣言的自己改善言語プログラム)は、迅速なエンジニアリングの複雑さを抽象化することにより、LLMアプリケーション開発に革命をもたらします。 このチュートリアルは、DSPYの宣言的アプローチを使用して強力な...AI 2025-03-22に投稿されました
-
ブログをTwitterスレッドに自動化しますこの記事では、GoogleのGemini-2.0 LLM、Chromadb、およびRiremlitを使用して、長型コンテンツ(ブログ投稿など)のTwitterスレッドの魅力を自動化することを詳しく説明しています。 手動スレッドの作成には時間がかかります。このアプリケーションはプロセスを合理化します...AI 2025-03-11に投稿されました
-
人工免疫系(AIS):Pythonの例を備えたガイドこの記事では、脅威を特定し、中和する人間の免疫系の顕著な能力に触発された計算モデルである人工免疫システム(AIS)を探ります。 AISのコア原則を掘り下げ、クローン選択、ネガティブ選択、免疫ネットワーク理論などの重要なアルゴリズムを調べ、Pythonコードの例でそれらのアプリケーションを説明します...AI 2025-03-04に投稿されました
-
ChatGPT に自分自身についての楽しい質問をしてみてくださいChatGPT があなたについて何を知っているのか疑問に思ったことはありますか?時間をかけて与えられた情報をどのように処理するのでしょうか?私はさまざまなシナリオで ChatGPT ヒープを使用してきましたが、特定のインタラクションの後にそのヒープが何を言うのかを見るのは常に興味深いものです。&#x...AI 2024 年 11 月 22 日に公開
-
謎の GPT-2 チャットボットをまだ試す方法は次のとおりですAI モデルやチャットボットに興味がある場合は、謎の GPT-2 チャットボットとその有効性に関する議論を見たことがあるかもしれません。ここでは、GPT-2 チャットボットとは何か、およびその方法について説明します。 GPT-2 チャットボットとは何ですか? 2024 年 4 月下旬、gpt2-c...AI 2024 年 11 月 8 日に公開
-
ChatGPT のキャンバス モードは素晴らしい: 4 つの使用方法ChatGPT の新しい Canvas モードは、世界をリードする生成 AI ツールでの書き込みと編集にさらなる次元を追加しました。私は ChatGPT Canvas の発売以来使用してきましたが、この新しい AI ツールを使用するためのいくつかの異なる方法を見つけました。✕ 広告の削除...AI 2024 年 11 月 8 日に公開
-
ChatGPT のカスタム GPT がデータを公開する仕組みとその安全性を保つ方法ChatGPT のカスタム GPT 機能を使用すると、誰でも思いつく限りのほとんどすべてのカスタム AI ツールを作成できます。クリエイティブ、テクニカル、ゲーム、カスタム GPT はすべてを行うことができます。さらに良いのは、カスタム GPT 作成を誰とでも共有できることです。 ただし、カスタ...AI 2024 年 11 月 8 日に公開
-
ChatGPT が LinkedIn での仕事の獲得に役立つ 10 の方法2,600 文字が利用できる LinkedIn プロフィールの About セクションは、あなたの経歴、スキル、情熱、将来の目標について詳しく説明するのに最適なスペースです。 LinkedIn の経歴を、あなたの職業上の背景、スキル、願望を簡潔にまとめたものとして表示します。 ChatGPT に...AI 2024 年 11 月 8 日に公開
-
ユニークなエクスペリエンスを提供する、あまり知られていない 6 つの AI アプリをチェックしてください現時点では、AI ブームをリードしてきた 2 つの先駆的な生成 AI アプリである ChatGPT と Copilot については、ほとんどの人が聞いたことがあるでしょう。しかし、あまり知られていない AI ツールの山が素晴らしい、ユニークな体験?ここでは最高のものを 6 つ紹介します。 1 同上ミ...AI 2024 年 11 月 8 日に公開
-
これらの 7 つの兆候は、AI がすでにピークに達していることを示していますオンラインでどこを見ても、AI の使用が最良の選択肢になると宣言するサイト、サービス、アプリがあります。あなたはどうか知りませんが、常に存在していると疲れてきます。 AI は確かに私たちの日常生活に定着していますが、AI の誇大宣伝がすでにピークに達していることを示す兆候がいくつかあります。 1 一...AI 2024 年 11 月 8 日に公開
-
教師、講師、上司向けの 4 つの AI チェック ChatGPT 検出ツールChatGPT の性能が向上するにつれて、何が人間によって書かれ、何が AI によって生成されたかを区別することがますます困難になってきています。そのため、教師や上司が、人間の手によって書かれたものと、ChatGPT を通じて生成されたものを識別することが困難になります。 違いを見分けるのが難し...AI 2024 年 11 月 8 日に公開















中国語を勉強する
- 1 「歩く」は中国語で何と言いますか? 走路 中国語の発音、走路 中国語学習
- 2 「飛行機に乗る」は中国語で何と言いますか? 坐飞机 中国語の発音、坐飞机 中国語学習
- 3 「電車に乗る」は中国語で何と言いますか? 坐火车 中国語の発音、坐火车 中国語学習
- 4 「バスに乗る」は中国語で何と言いますか? 坐车 中国語の発音、坐车 中国語学習
- 5 中国語でドライブは何と言うでしょう? 开车 中国語の発音、开车 中国語学習
- 6 水泳は中国語で何と言うでしょう? 游泳 中国語の発音、游泳 中国語学習
- 7 中国語で自転車に乗るってなんて言うの? 骑自行车 中国語の発音、骑自行车 中国語学習
- 8 中国語で挨拶はなんて言うの? 你好中国語の発音、你好中国語学習
- 9 中国語でありがとうってなんて言うの? 谢谢中国語の発音、谢谢中国語学習
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









