
Hongos Mágicos: explorando y tratando datos nulos con Mage
 Navegar:966
Navegar:966
Mage es una poderosa herramienta para tareas ETL, con funciones que permiten la exploración y extracción de datos, visualizaciones rápidas a través de plantillas de gráficos y varias otras funciones que transforman tu trabajo con datos en algo mágico.
En el procesamiento de datos, durante un proceso ETL es común encontrar datos faltantes que pueden generar problemas en el futuro, dependiendo de la actividad que vayamos a realizar con el conjunto de datos, los datos nulos pueden ser bastante disruptivos.
Para identificar la ausencia de datos en nuestro conjunto de datos, podemos usar Python y la biblioteca pandas para verificar los datos que presentan valores nulos, además podemos crear gráficas que muestren aún más claramente el impacto de estos valores nulos en nuestro conjunto de datos.
Nuestro proceso consta de 4 pasos: comenzando con la carga de los datos, dos pasos de procesamiento y la exportación de los datos.
Cargador de datos
En este artículo utilizaremos el conjunto de datos: Predicción binaria de hongos venenosos que está disponible en Kaggle como parte de una competencia. Utilicemos el conjunto de datos de entrenamiento disponible en el sitio web.
Creemos un paso del Cargador de datos usando python para poder cargar los datos que vamos a utilizar. Antes de este paso, creé una tabla en la base de datos de Postgres, que tengo localmente en mi máquina, para poder cargar los datos. Como los datos están en Postgres, usaremos la plantilla de carga de Postgres ya definida dentro de Mage.
from mage_ai.settings.repo import get_repo_path from mage_ai.io.config import ConfigFileLoader from mage_ai.io.postgres import Postgres from os import path if 'data_loader' not in globals(): from mage_ai.data_preparation.decorators import data_loader if 'test' not in globals(): from mage_ai.data_preparation.decorators import test @data_loader def load_data_from_postgres(*args, **kwargs): """ Template for loading data from a PostgreSQL database. Specify your configuration settings in 'io_config.yaml'. Docs: https://docs.mage.ai/design/data-loading#postgresql """ query = 'SELECT * FROM mushroom' # Specify your SQL query here config_path = path.join(get_repo_path(), 'io_config.yaml') config_profile = 'default' with Postgres.with_config(ConfigFileLoader(config_path, config_profile)) as loader: return loader.load(query) @test def test_output(output, *args) -> None: """ Template code for testing the output of the block. """ assert output is not None, 'The output is undefined'
Dentro de la función load_data_from_postgres() definiremos la consulta que usaremos para cargar la tabla en la base de datos. En mi caso, configuré la información bancaria en el archivo io_config.yaml donde está definida como configuración predeterminada, por lo que solo necesitamos pasarle el nombre predeterminado a la variable config_profile.
Después de ejecutar el bloque, usaremos la función Agregar gráfico, que proporcionará información sobre nuestros datos a través de plantillas ya definidas. Simplemente haz clic en el icono al lado del botón de reproducción, marcado en la imagen con una línea amarilla.

Seleccionaremos dos opciones para explorar más nuestro conjunto de datos, las opciones summay_overview y feature_profiles. A través de resumen_overview, obtenemos información sobre la cantidad de columnas y filas en el conjunto de datos. También podemos ver la cantidad total de columnas por tipo, por ejemplo, la cantidad total de columnas categóricas, numéricas y booleanas. Feature_profiles por su parte presenta información más descriptiva sobre los datos, como: tipo, valor mínimo, valor máximo, entre otra información, incluso podemos visualizar los valores faltantes, que son el foco de nuestro tratamiento.
Para poder centrarnos más en los datos faltantes, usemos la plantilla: % de valores faltantes, un gráfico de barras con el porcentaje de datos que faltan, en cada una de las columnas.
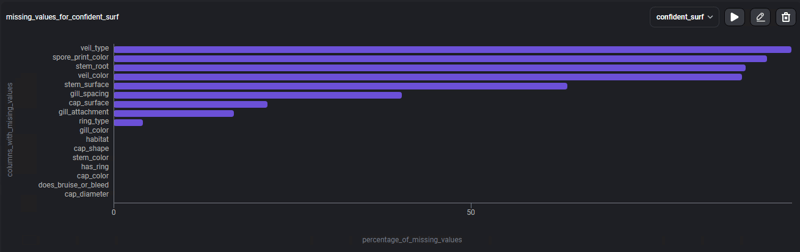
El gráfico presenta 4 columnas donde los valores faltantes corresponden a más del 80% de su contenido, y otras columnas que presentan valores faltantes pero en cantidades menores, esta información ahora nos permite buscar diferentes estrategias para enfrentar esto datos nulos
Columnas de caída de transformador
Para columnas que tengan más del 80% de valores nulos, la estrategia que seguiremos será realizar un drop de columnas en el dataframe, seleccionando las columnas que vamos a excluir del dataframe. Usando el Bloque TRANSFORMER en el lenguaje Python, seleccionaremos la opción Eliminación de columnas.
from mage_ai.data_cleaner.transformer_actions.base import BaseAction from mage_ai.data_cleaner.transformer_actions.constants import ActionType, Axis from mage_ai.data_cleaner.transformer_actions.utils import build_transformer_action from pandas import DataFrame if 'transformer' not in globals(): from mage_ai.data_preparation.decorators import transformer if 'test' not in globals(): from mage_ai.data_preparation.decorators import test @transformer def execute_transformer_action(df: DataFrame, *args, **kwargs) -> DataFrame: """ Execute Transformer Action: ActionType.REMOVE Docs: https://docs.mage.ai/guides/transformer-blocks#remove-columns """ action = build_transformer_action( df, action_type=ActionType.REMOVE, arguments=['veil_type', 'spore_print_color', 'stem_root', 'veil_color'], axis=Axis.COLUMN, ) return BaseAction(action).execute(df) @test def test_output(output, *args) -> None: """ Template code for testing the output of the block. """ assert output is not None, 'The output is undefined'
Dentro de la función execute_transformer_action() insertaremos una lista con el nombre de las columnas que queremos excluir del conjunto de datos, en la variable argumentos, luego de este paso, simplemente ejecuta el bloque.
Transformador completa los valores faltantes
Ahora para las columnas que tienen menos del 80% de valores nulos, usaremos la estrategia Rellenar valores faltantes, como en algunos casos a pesar de tener datos faltantes, reemplazando estos con valores como promedio, o moda, puede satisfacer las necesidades de datos sin causar muchos cambios en el conjunto de datos, dependiendo de su objetivo final.
Hay algunas tareas, como la clasificación, en las que reemplazar los datos faltantes con un valor que sea relevante (moda, media, mediana) para el conjunto de datos puede contribuir al algoritmo de clasificación, que podría llegar a otras conclusiones si los datos se eliminaran. como en la otra estrategia que utilizamos.
Para tomar una decisión con respecto a qué medición usaremos, usaremos la funcionalidad Agregar gráfico de Mage nuevamente. Usando la plantilla Valores más frecuentes podemos visualizar la moda y frecuencia de este valor en cada una de las columnas.
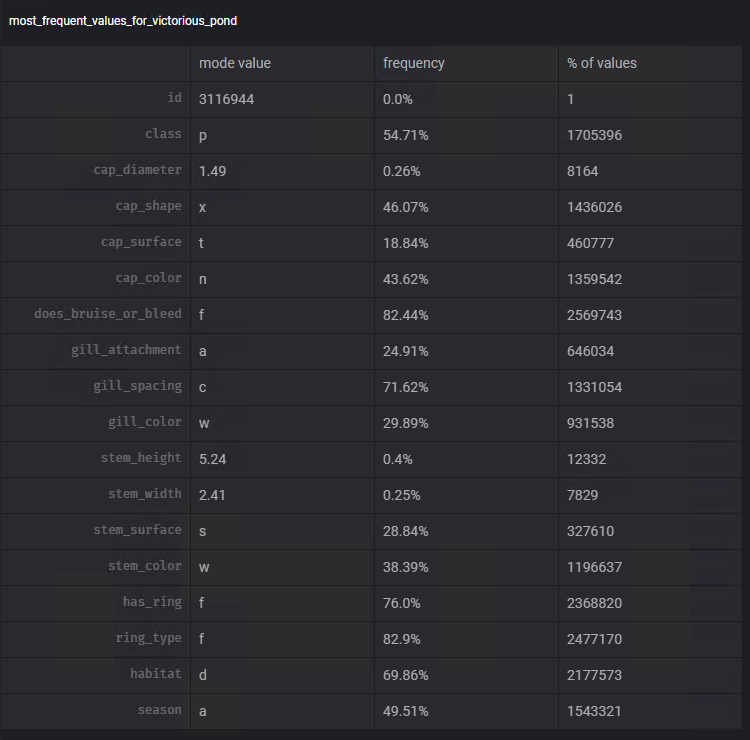
Siguiendo pasos similares a los anteriores, usaremos el transformador Rellenar valores faltantes, para realizar la tarea de restar los datos faltantes usando la moda de cada una de las columnas: steam_surface, gill_spacing, cap_surface , archivo adjunto_gill, tipo_anillo.
from mage_ai.data_cleaner.transformer_actions.constants import ImputationStrategy
from mage_ai.data_cleaner.transformer_actions.base import BaseAction
from mage_ai.data_cleaner.transformer_actions.constants import ActionType, Axis
from mage_ai.data_cleaner.transformer_actions.utils import build_transformer_action
from pandas import DataFrame
if 'transformer' not in globals():
from mage_ai.data_preparation.decorators import transformer
if 'test' not in globals():
from mage_ai.data_preparation.decorators import test
@transformer
def execute_transformer_action(df: DataFrame, *args, **kwargs) -> DataFrame:
"""
Execute Transformer Action: ActionType.IMPUTE
Docs: https://docs.mage.ai/guides/transformer-blocks#fill-in-missing-values
"""
action = build_transformer_action(
df,
action_type=ActionType.IMPUTE,
arguments=df.columns, # Specify columns to impute
axis=Axis.COLUMN,
options={'strategy': ImputationStrategy.MODE}, # Specify imputation strategy
)
return BaseAction(action).execute(df)
@test
def test_output(output, *args) -> None:
"""
Template code for testing the output of the block.
"""
assert output is not None, 'The output is undefined'
En la función execute_transformer_action() , definimos la estrategia para reemplazar datos en un diccionario de Python. Para obtener más opciones de reemplazo, simplemente acceda a la documentación del transformador: https://docs.mage.ai/guides/transformer-blocks#fill-in-missing-values.
Exportador de datos
Al realizar todas las transformaciones, guardaremos nuestro conjunto de datos ahora tratado, en la misma base de datos de Postgres pero ahora con un nombre diferente para poder diferenciarnos. Usando el bloque Data Exporter y seleccionando Postgres, definiremos el shema y la tabla donde queremos guardar, recordando que las configuraciones de la base de datos se guardan previamente en el archivo io_config.yaml.
from mage_ai.settings.repo import get_repo_path from mage_ai.io.config import ConfigFileLoader from mage_ai.io.postgres import Postgres from pandas import DataFrame from os import path if 'data_exporter' not in globals(): from mage_ai.data_preparation.decorators import data_exporter @data_exporter def export_data_to_postgres(df: DataFrame, **kwargs) -> None: """ Template for exporting data to a PostgreSQL database. Specify your configuration settings in 'io_config.yaml'. Docs: https://docs.mage.ai/design/data-loading#postgresql """ schema_name = 'public' # Specify the name of the schema to export data to table_name = 'mushroom_clean' # Specify the name of the table to export data to config_path = path.join(get_repo_path(), 'io_config.yaml') config_profile = 'default' with Postgres.with_config(ConfigFileLoader(config_path, config_profile)) as loader: loader.export( df, schema_name, table_name, index=False, # Specifies whether to include index in exported table if_exists='replace', #Specify resolution policy if table name already exists )
Gracias y ¿nos vemos la próxima vez?
repositorio -> https://github.com/DeadPunnk/Mushrooms/tree/main
-
 ¿Cómo puedo reorganizar las columnas en un diseño de cuadrícula CSS para lograr capacidad de respuesta móvil?Reordenar columnas en un diseño de cuadrícula CSSEn el diseño de cuadrícula CSS, existen varias técnicas para modificar el orden de las columnas para ...Programación Publicado el 2024-11-06
¿Cómo puedo reorganizar las columnas en un diseño de cuadrícula CSS para lograr capacidad de respuesta móvil?Reordenar columnas en un diseño de cuadrícula CSSEn el diseño de cuadrícula CSS, existen varias técnicas para modificar el orden de las columnas para ...Programación Publicado el 2024-11-06 -
Sistema de subastas en línea de la semana del HacktoberfestDescripción general Durante la semana 3 del Hacktoberfest, decidí contribuir a un proyecto más pequeño pero prometedor: un sistema de subasta...Programación Publicado el 2024-11-06
-
¿Cómo se propagan excepciones entre subprocesos en C++ usando `exception_ptr`?Propagar excepciones entre subprocesos en C La tarea de propagar excepciones entre subprocesos en C surge cuando una función llamada desde un subproce...Programación Publicado el 2024-11-06
-
¿Cómo arreglar bordes irregulares en Firefox con transformaciones CSS 3D?Bordes dentados en Firefox con transformaciones CSS 3DAl igual que el problema de los bordes dentados en Chrome con transformaciones CSS, Firefox tamb...Programación Publicado el 2024-11-06
-
¿Por qué la función mail() de PHP plantea desafíos para la entrega de correo electrónico?Por qué la función mail() de PHP se queda corta: limitaciones y trampasSi bien PHP proporciona la función mail() para enviar correos electrónicos, no ...Programación Publicado el 2024-11-06
-
Optimice sus conversiones de archivos NumPy con npyConverterSi trabaja con archivos .npy de NumPy y necesita convertirlos a formatos .mat (MATLAB) o .csv, npyConverter es la herramienta para usted. Esta sencill...Programación Publicado el 2024-11-06
-
¿Cómo deshabilitar las reglas de Eslint para una línea específica?Regla de Eslint deshabilitada para una línea específicaEn JSHint, las reglas de linting se pueden deshabilitar para una línea en particular usando la ...Programación Publicado el 2024-11-06
-
¿Cómo insertar listas en celdas del DataFrame de Pandas sin errores?Insertar listas en celdas de PandasProblemaEn Python, intentar insertar una lista en una celda de un Pandas DataFrame puede generar errores o resultad...Programación Publicado el 2024-11-06
-
¿Cuáles son las diferencias clave entre `plt.plot`, `ax.plot` y `figure.add_subplot` en Matplotlib?Diferencias entre trazado, ejes y figura en MatplotlibMatplotlib es una biblioteca Python orientada a objetos para crear visualizaciones. Utiliza tres...Programación Publicado el 2024-11-06
-
FireDucks: ¡Obtenga un rendimiento superior al de los pandas sin coste de aprendizaje!Pandas es una de las bibliotecas más populares. Cuando buscaba una manera más fácil de acelerar su rendimiento, ¡descubrí FireDucks y me interesé en e...Programación Publicado el 2024-11-06
-
Cuadrícula CSS: diseños de cuadrícula anidadosIntroducción CSS Grid es un sistema de diseño que rápidamente ha ganado popularidad entre los desarrolladores web por su flexibilidad y efici...Programación Publicado el 2024-11-06
-
Cuaderno Jupyter para JavaEl poderoso de Jupyter Notebook Jupyter Notebooks es una excelente herramienta, desarrollada originalmente para ayudar a los científicos e in...Programación Publicado el 2024-11-06
-
¿Cómo compartir datos entre la ventana principal y los subprocesos en PyQt: referencia directa frente a señales y ranuras?Compartir datos entre la ventana principal y el subproceso en PyQtLas aplicaciones multiproceso a menudo necesitan compartir datos entre el subproceso...Programación Publicado el 2024-11-06
-
¿Los atajos de código VS más útiles para desarrolladores profesionales?Los 20 atajos más útiles en VS Code Navegación general Paleta de comandos: acceda a todos los comandos disponibles en VS Code. Ctrl Shift P (Windows/...Programación Publicado el 2024-11-06
-
Creemos una mejor entrada numérica con ReactProgramación Publicado el 2024-11-06















Estudiar chino
- 1 ¿Cómo se dice "caminar" en chino? 走路 pronunciación china, 走路 aprendizaje chino
- 2 ¿Cómo se dice "tomar un avión" en chino? 坐飞机 pronunciación china, 坐飞机 aprendizaje chino
- 3 ¿Cómo se dice "tomar un tren" en chino? 坐火车 pronunciación china, 坐火车 aprendizaje chino
- 4 ¿Cómo se dice "tomar un autobús" en chino? 坐车 pronunciación china, 坐车 aprendizaje chino
- 5 ¿Cómo se dice conducir en chino? 开车 pronunciación china, 开车 aprendizaje chino
- 6 ¿Cómo se dice nadar en chino? 游泳 pronunciación china, 游泳 aprendizaje chino
- 7 ¿Cómo se dice andar en bicicleta en chino? 骑自行车 pronunciación china, 骑自行车 aprendizaje chino
- 8 ¿Cómo se dice hola en chino? 你好Pronunciación china, 你好Aprendizaje chino
- 9 ¿Cómo se dice gracias en chino? 谢谢Pronunciación china, 谢谢Aprendizaje chino
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









