 Página delantera > Programación > FireDucks: ¡Obtenga un rendimiento superior al de los pandas sin coste de aprendizaje!
Página delantera > Programación > FireDucks: ¡Obtenga un rendimiento superior al de los pandas sin coste de aprendizaje!
FireDucks: ¡Obtenga un rendimiento superior al de los pandas sin coste de aprendizaje!
 Navegar:515
Navegar:515
Pandas es una de las bibliotecas más populares. Cuando buscaba una manera más fácil de acelerar su rendimiento, ¡descubrí FireDucks y me interesé en ella!
Comparación con los pandas: ¿Por qué FireDucks?
Un programa Pandas puede encontrar un problema de rendimiento grave dependiendo de cómo se haya escrito. Sin embargo, como científico de datos, quiero dedicar cada vez más tiempo a analizar datos en lugar de mejorar el rendimiento de mi código. Por lo tanto, sería fantástico si pudiera hacer algo como intercambiar el orden de los procesos y acelerar el rendimiento del programa automáticamente. Por ejemplo, el Proceso A =>Proceso B será más lento, por lo que lo reemplazaremos como Proceso B =>Proceso A. (Por supuesto, se garantiza que el resultado será el mismo). Se dice que los científicos de datos gastan alrededor del 45% de su tiempo preparando los datos, y cuando estaba pensando en hacer algo para acelerar el proceso, me encontré con un módulo llamado FireDucks.
Según la documentación de FireDucks, parece ser compatible solo con plataformas Linux. Como uso Windows en mi máquina principal, me gustaría probarlo desde WSL2 (Subsistema de Windows para Linux), un entorno que puede ejecutar Linux en Windows.
El entorno que probé es el siguiente.
- SO Microsoft Windows 11 Pro
- Versión 10.0.22631 Compilación 22631
- Modelo del sistema Z690 Pro RS
- Tipo de sistema basado en x64
- Procesador de PC Intel(R) Core(TM) i3–12100 de 12.ª generación, 3300 Mhz, 4 núcleos, 8 procesadores lógicos
- Producto de placa base Z690 Pro RS
- Rol de plataforma Escritorio
- Memoria física instalada (RAM)64,0 GB
Instalación y configuración de FireDucks
Instalar WSL
WSL se instaló con la ayuda de la siguiente documentación de Microsoft; la distribución de Linux es Ubuntu 22.04.1 LTS.
Instalar FireDucks
Luego instale FireDucks. Sin embargo, es muy fácil de instalar.
instalación de pip patos disparados
La instalación de FireDucks (junto con pyarrow, pandas y otras bibliotecas) llevará unos minutos.
Intenté ejecutar el siguiente código, la velocidad de carga fue tan rápida que los pandas tardaron 4 segundos y los fireDucks solo tardaron 74,5 ns.
# 1. analysis based on time period and creative duration # convert timestamp to date/time object df['timestamp_converted'] = pd.to_datetime(df['timestamp'], unit='s ') # define time period def get_part_of_day(hour): if 5Todo este preprocesamiento y análisis de datos tomó alrededor de 8 segundos en pandas, mientras que podría completarse en 4 segundos cuando se usa FireDucks. Se podría lograr casi el doble de velocidad.
Rendimiento mejorado
Una de las cosas más estresantes de usar pandas es esperar cuando se cargan grandes conjuntos de datos, y luego tengo que esperar operaciones complejas como groupby. Por otro lado, dado que FireDucks realiza una evaluación diferida, la carga no toma tiempo, por lo que el procesamiento se realiza donde es necesario, y sentí que fue muy significativo con una gran reducción en el tiempo total de espera.
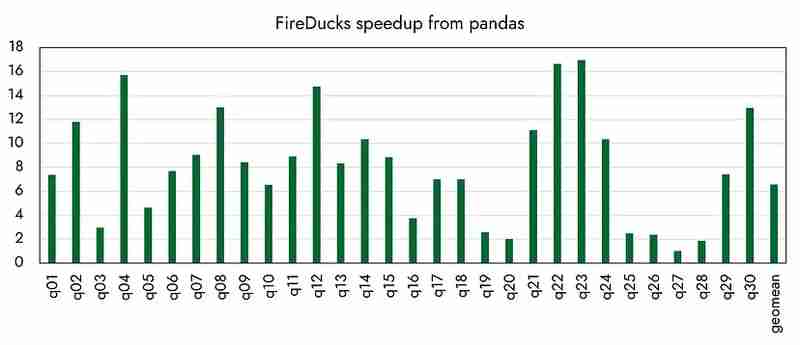
En cuanto a otros rendimientos, parece que se ha logrado hasta 16 veces más rápido en comparación con los pandas, como anunció oficialmente la organización. (La próxima vez compararé el rendimiento con varias bibliotecas de la competencia).
coste de aprendizaje cero
La capacidad de seguir la notación pandas exacta sin tener que pensar en nada es una gran ventaja. Además de FireDucks, existen otras bibliotecas de aceleración de marcos de datos, pero son demasiado costosas de aprender y demasiado fáciles de olvidar.
Por ejemplo, si quieres agregar columnas con polares, tienes que escribir algo como esto.
# pandas df["new_col"] = df["A"] 1 # polars df = df.with_columns((pl.col("A") 1).alias("new_col"))Casi no es necesario cambiar un código existente
Tengo varios ETL y otros proyectos que usan pandas, y sería bueno ver una mejora en el rendimiento simplemente instalando y reemplazando la declaración de importación con FireDucks.
Si deseas agregarlo más, no dudes en comentar a continuación.
-
 ¿Por qué Microsoft Visual C ++ no implementa correctamente la instanciación de la plantilla de dos fases?El misterio de la plantilla de dos fases "roto" instanciación en Microsoft Visual c declaración de problemas: usuarios comúnmente ...Programación Publicado el 2025-03-12
¿Por qué Microsoft Visual C ++ no implementa correctamente la instanciación de la plantilla de dos fases?El misterio de la plantilla de dos fases "roto" instanciación en Microsoft Visual c declaración de problemas: usuarios comúnmente ...Programación Publicado el 2025-03-12 -
UTF-8 vs. Latin-1: ¡la codificación del secreto del carácter!Distinguing UTF-8 y LATIN1 Cuando se trata de codificar, emergen dos opciones prominentes: UTF-8 y LATIN1. En medio de sus aplicaciones, surge...Programación Publicado el 2025-03-12
-
FormaciónLos métodos son fns que se pueden llamar a los objetos Las matrices son objetos, por lo tanto, también tienen métodos en js. Slice (Begi...Programación Publicado el 2025-03-12
-
Parte Serie de inyección SQL: explicación detallada de las técnicas avanzadas de inyección SQLautor: trix cyrus WayMap Pentesting Tool: Haga clic aquí Trixsec Github: haga clic aquí TrixSec Telegram: haga clic aquí Explotos ...Programación Publicado el 2025-03-12
-
¿Cómo podemos asegurar las cargas de archivos contra contenido malicioso?Las preocupaciones de seguridad con las cargas de archivo Los archivos de carga a un servidor pueden introducir riesgos de seguridad significa...Programación Publicado el 2025-03-12
-
¿Cómo eliminar los descansos de línea de las cadenas usando expresiones regulares en JavaScript?Eliminación de rupturas de línea de las cadenas En este escenario de código, el objetivo es eliminar las rupturas de línea de una cadena de text...Programación Publicado el 2025-03-12
-
¿Por qué cesan la ejecución de JavaScript cuando se usa el botón de retroceso de Firefox?Problema de historial de navegación: JavaScript deja de ejecutar después de usar el botón de retroceso de Firefox Los usuarios de Firefox pued...Programación Publicado el 2025-03-12
-
¿Cómo insertar correctamente las blobs (imágenes) en MySQL usando PHP?Inserte blobs en bases de datos MySQL con php Al intentar almacenar una imagen en una base de datos MySQL, puede encontrar un asunto. Esta gu...Programación Publicado el 2025-03-12
-
¿Puedo migrar mi cifrado de MCRYPT a OpenSSL y descifrar datos cifrados de MCRYPT usando OpenSSL?actualizando mi biblioteca de cifrado de MCRYP En OpenSSL, ¿es posible descifrar datos encriptados con MCRYPT? Dos publicaciones diferentes propo...Programación Publicado el 2025-03-12
-
¿Existe una diferencia de rendimiento entre usar un bucle for-ENTRES y un iterador para la transmisión de recorrido en Java?para cada bucle vs. iterator: eficiencia en la colección traversal introduction cuando la colección en java, la opción, la opción iba entr...Programación Publicado el 2025-03-12
-
¿Cómo verificar si un objeto tiene un atributo específico en Python?para determinar el atributo de objeto existencia Esta consulta busca un método para verificar la presencia de un atributo específico dentro de...Programación Publicado el 2025-03-12
-
Explicación detallada del método de adquisición de elementos aleatorios de Java Hashset/Linkedhashsetpara encontrar un elemento aleatorio en un set en programación, puede ser útil seleccionar un elemento aleatorio de una colección, como un conju...Programación Publicado el 2025-03-12
-
¿Cuándo los atributos CSS se vuelven a caer a los píxeles (PX) sin unidades?fallback para atributos CSS sin unidades: un estudio de caso atributos CSS a menudo requiere unidades (por ejemplo, PX, EM, %) para especifica...Programación Publicado el 2025-03-12
-
¿Cómo recuperar la última biblioteca jQuery de Google API?recuperando la última biblioteca jQuery de Google APIS La URL de jQuery proporcionada en la pregunta es para la versión 1.2.6. Para recuperar ...Programación Publicado el 2025-03-12
-
¿Cuáles fueron las restricciones al usar Current_Timestamp con columnas de marca de tiempo en MySQL antes de la versión 5.6.5?en las columnas de la marca de tiempo con cursion_timestamp en predeterminado o en las cláusulas de actualización en las versiones mySql antes de ...Programación Publicado el 2025-03-12















Estudiar chino
- 1 ¿Cómo se dice "caminar" en chino? 走路 pronunciación china, 走路 aprendizaje chino
- 2 ¿Cómo se dice "tomar un avión" en chino? 坐飞机 pronunciación china, 坐飞机 aprendizaje chino
- 3 ¿Cómo se dice "tomar un tren" en chino? 坐火车 pronunciación china, 坐火车 aprendizaje chino
- 4 ¿Cómo se dice "tomar un autobús" en chino? 坐车 pronunciación china, 坐车 aprendizaje chino
- 5 ¿Cómo se dice conducir en chino? 开车 pronunciación china, 开车 aprendizaje chino
- 6 ¿Cómo se dice nadar en chino? 游泳 pronunciación china, 游泳 aprendizaje chino
- 7 ¿Cómo se dice andar en bicicleta en chino? 骑自行车 pronunciación china, 骑自行车 aprendizaje chino
- 8 ¿Cómo se dice hola en chino? 你好Pronunciación china, 你好Aprendizaje chino
- 9 ¿Cómo se dice gracias en chino? 谢谢Pronunciación china, 谢谢Aprendizaje chino
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









