
Magic Mushrooms: exploring and treating null data with Mage
 Browse:246
Browse:246
Mage is a powerful tool for ETL tasks, with features that enable data exploration and mining, quick visualizations through graph templates and several other features that transform your work with data into something magical.
In data processing, during an ETL process it is common to find missing data that can generate problems in the future, depending on the activity we are going to carry out with the dataset, null data can be quite disruptive.
To identify the absence of data in our dataset, we can use Python and the pandas library to check the data that presents null values, in addition we can create graphs that show even more clearly the impact of these null values in our dataset.
Our pipeline consists of 4 steps: starting with loading the data, two processing steps and exporting the data.
Data Loader
In this article we will use the dataset: Binary Prediction of Poisonous Mushrooms which is available on Kaggle as part of a competition. Let's use the training dataset available on the website.
Let's create a Data Loader step using python to be able to load the data we are going to use. Before this step, I created a table in the Postgres database, which I have locally on my machine, to be able to load the data. As the data is in Postgres, we will use the already defined Postgres load template within Mage.
from mage_ai.settings.repo import get_repo_path from mage_ai.io.config import ConfigFileLoader from mage_ai.io.postgres import Postgres from os import path if 'data_loader' not in globals(): from mage_ai.data_preparation.decorators import data_loader if 'test' not in globals(): from mage_ai.data_preparation.decorators import test @data_loader def load_data_from_postgres(*args, **kwargs): """ Template for loading data from a PostgreSQL database. Specify your configuration settings in 'io_config.yaml'. Docs: https://docs.mage.ai/design/data-loading#postgresql """ query = 'SELECT * FROM mushroom' # Specify your SQL query here config_path = path.join(get_repo_path(), 'io_config.yaml') config_profile = 'default' with Postgres.with_config(ConfigFileLoader(config_path, config_profile)) as loader: return loader.load(query) @test def test_output(output, *args) -> None: """ Template code for testing the output of the block. """ assert output is not None, 'The output is undefined'
Within the function load_data_from_postgres() we will define the query that we will use to load the table in the database. In my case, I configured the bank information in the file io_config.yaml where it is defined as the default configuration, so we only need to pass the default name to the variable config_profile.
After executing the block, we will use the Add chart feature, which will provide information about our data through already defined templates. Just click on the icon next to the play button, marked in the image with a yellow line.

We will select two options to explore our dataset further, the summay_overview and feature_profiles options. Through summary_overview, we obtain information about the number of columns and rows in the dataset. We can also view the total number of columns by type, for example the total number of categorical, numeric and Boolean columns. Feature_profiles, on the other hand, presents more descriptive information about the data, such as: type, minimum value, maximum value, among other information, we can even visualize the missing values, which are the focus of our treatment.
To be able to focus more on missing data, let's use the template: % of missing values, a bar graph with the percentage of data that is missing, in each of the columns.
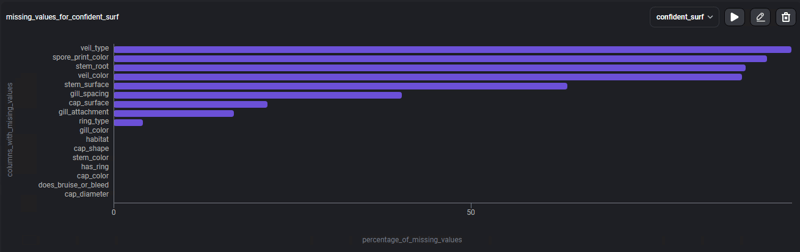
The graph presents 4 columns where missing values correspond to more than 80% of its content, and other columns that present missing values but in smaller quantities, this information now allows us to seek different strategies to deal with this null data.
Transformer Drop Columns
For columns that have more than 80% of null values, the strategy we will follow will be to perform a drop columns in the dataframe, selecting the columns that we are going to exclude from the dataframe. Using the TRANSFORMER Block in the Python language, we will select the option Colum removal .
from mage_ai.data_cleaner.transformer_actions.base import BaseAction from mage_ai.data_cleaner.transformer_actions.constants import ActionType, Axis from mage_ai.data_cleaner.transformer_actions.utils import build_transformer_action from pandas import DataFrame if 'transformer' not in globals(): from mage_ai.data_preparation.decorators import transformer if 'test' not in globals(): from mage_ai.data_preparation.decorators import test @transformer def execute_transformer_action(df: DataFrame, *args, **kwargs) -> DataFrame: """ Execute Transformer Action: ActionType.REMOVE Docs: https://docs.mage.ai/guides/transformer-blocks#remove-columns """ action = build_transformer_action( df, action_type=ActionType.REMOVE, arguments=['veil_type', 'spore_print_color', 'stem_root', 'veil_color'], axis=Axis.COLUMN, ) return BaseAction(action).execute(df) @test def test_output(output, *args) -> None: """ Template code for testing the output of the block. """ assert output is not None, 'The output is undefined'
Within the function execute_transformer_action() we will insert a list with the name of the columns that we want to exclude from the dataset, in the arguments variable, after this step, just execute the block.
Transformer Fill in Missing Values
Now for the columns that have less than 80% of null values, we will use the strategy Fill in Missing Values, as in some cases despite having missing data, replacing these with values such as average, or fashion, it may be able to meet the data needs without causing many changes to the dataset, depending on your final objective.
There are some tasks, such as classification, where replacing missing data with a value that is relevant (mode, mean, median) for the dataset, can contribute to the classification algorithm, which could reach other conclusions if the data were deleted as in the other strategy we used.
To make a decision regarding which measurement we will use, we will use Mage's Add chart functionality again. Using the template Most frequent values we can visualize the mode and frequency of this value in each of the columns.
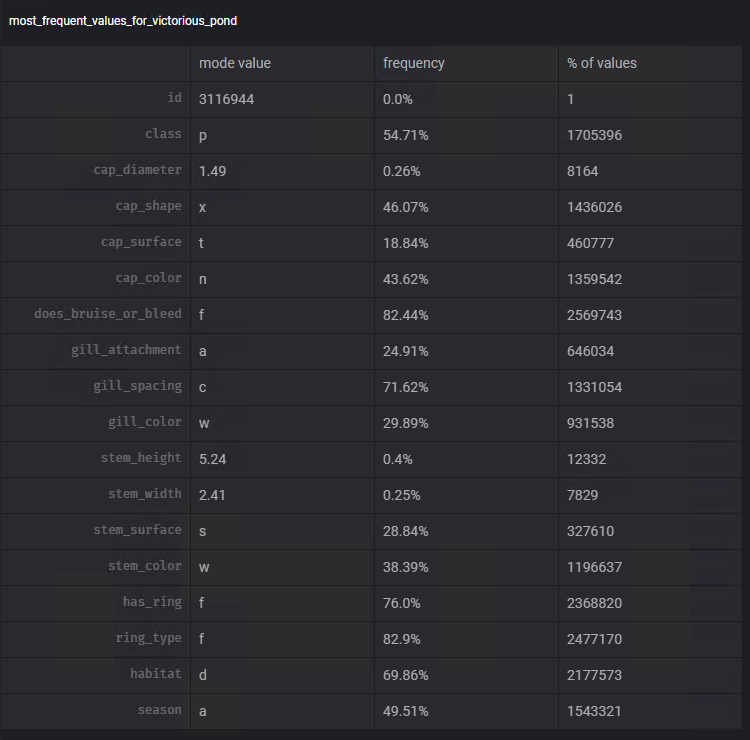
Following steps similar to the previous ones, we will use the transformer Fill in missing values, to perform the task of subtracting the missing data using the mode of each of the columns: steam_surface, gill_spacing, cap_surface, gill_attachment, ring_type.
from mage_ai.data_cleaner.transformer_actions.constants import ImputationStrategy
from mage_ai.data_cleaner.transformer_actions.base import BaseAction
from mage_ai.data_cleaner.transformer_actions.constants import ActionType, Axis
from mage_ai.data_cleaner.transformer_actions.utils import build_transformer_action
from pandas import DataFrame
if 'transformer' not in globals():
from mage_ai.data_preparation.decorators import transformer
if 'test' not in globals():
from mage_ai.data_preparation.decorators import test
@transformer
def execute_transformer_action(df: DataFrame, *args, **kwargs) -> DataFrame:
"""
Execute Transformer Action: ActionType.IMPUTE
Docs: https://docs.mage.ai/guides/transformer-blocks#fill-in-missing-values
"""
action = build_transformer_action(
df,
action_type=ActionType.IMPUTE,
arguments=df.columns, # Specify columns to impute
axis=Axis.COLUMN,
options={'strategy': ImputationStrategy.MODE}, # Specify imputation strategy
)
return BaseAction(action).execute(df)
@test
def test_output(output, *args) -> None:
"""
Template code for testing the output of the block.
"""
assert output is not None, 'The output is undefined'
In the function execute_transformer_action() , we define the strategy for replacing data in a Python dictionary. For more replacement options, just access the transformer documentation: https://docs.mage.ai/guides/transformer-blocks#fill-in-missing-values.
Data Exporter
When carrying out all the transformations, we will save our now treated dataset, in the same Postgres database but now with a different name so we can differentiate. Using the Data Exporter block and selecting Postgres, we will define the shema and the table where we want to save, remembering that the database configurations are previously saved in the file io_config.yaml.
from mage_ai.settings.repo import get_repo_path from mage_ai.io.config import ConfigFileLoader from mage_ai.io.postgres import Postgres from pandas import DataFrame from os import path if 'data_exporter' not in globals(): from mage_ai.data_preparation.decorators import data_exporter @data_exporter def export_data_to_postgres(df: DataFrame, **kwargs) -> None: """ Template for exporting data to a PostgreSQL database. Specify your configuration settings in 'io_config.yaml'. Docs: https://docs.mage.ai/design/data-loading#postgresql """ schema_name = 'public' # Specify the name of the schema to export data to table_name = 'mushroom_clean' # Specify the name of the table to export data to config_path = path.join(get_repo_path(), 'io_config.yaml') config_profile = 'default' with Postgres.with_config(ConfigFileLoader(config_path, config_profile)) as loader: loader.export( df, schema_name, table_name, index=False, # Specifies whether to include index in exported table if_exists='replace', #Specify resolution policy if table name already exists )
Thank you and see you next time?
repo -> https://github.com/DeadPunnk/Mushrooms/tree/main
-
 Guide to Solve CORS Issues in Spring Security 4.1 and aboveSpring Security CORS Filter: Troubleshooting Common IssuesWhen integrating Spring Security into an existing project, you may encounter CORS-related er...Programming Posted on 2025-07-03
Guide to Solve CORS Issues in Spring Security 4.1 and aboveSpring Security CORS Filter: Troubleshooting Common IssuesWhen integrating Spring Security into an existing project, you may encounter CORS-related er...Programming Posted on 2025-07-03 -
Can template parameters in C++20 Consteval function depend on function parameters?Consteval Functions and Template Parameters Dependent on Function ArgumentsIn C 17, a template parameter cannot depend on a function argument because...Programming Posted on 2025-07-03
-
PHP SimpleXML parsing XML method with namespace colonParsing XML with Namespace Colons in PHPSimpleXML encounters difficulties when parsing XML containing tags with colons, such as XML elements with pref...Programming Posted on 2025-07-03
-
Python Read CSV File UnicodeDecodeError Ultimate SolutionUnicode Decode Error in CSV File ReadingWhen attempting to read a CSV file into Python using the built-in csv module, you may encounter an error stati...Programming Posted on 2025-07-03
-
How to pass exclusive pointers as function or constructor parameters in C++?Managing Unique Pointers as Parameters in Constructors and FunctionsUnique pointers (unique_ptr) uphold the principle of unique ownership in C 11. Wh...Programming Posted on 2025-07-03
-
How to efficiently repeat string characters for indentation in C#?Repeating a String for IndentationWhen indenting a string based on an item's depth, it's convenient to have an efficient way to return a strin...Programming Posted on 2025-07-03
-
How to efficiently detect empty arrays in PHP?Checking Array Emptiness in PHPAn empty array can be determined in PHP through various approaches. If the need is to verify the presence of any array ...Programming Posted on 2025-07-03
-
How to efficiently INSERT or UPDATE rows based on two conditions in MySQL?INSERT INTO or UPDATE with Two ConditionsProblem Description:The user encounters a time-consuming challenge: inserting a new row into a table if there...Programming Posted on 2025-07-03
-
How to upload files with additional parameters using java.net.URLConnection and multipart/form-data encoding?Uploading Files with HTTP RequestsTo upload files to an HTTP server while also submitting additional parameters, java.net.URLConnection and multipart/...Programming Posted on 2025-07-03
-
Method for correct passing of C++ member function pointersHow to Pass Member Function Pointers in C When passing a class member function to a function that accepts a member function pointer, it's essenti...Programming Posted on 2025-07-03
-
How to Correctly Use LIKE Queries with PDO Parameters?Using LIKE Queries in PDOWhen trying to implement LIKE queries in PDO, you may encounter issues like the one described in the query below:$query = &qu...Programming Posted on 2025-07-03
-
MySQL database method is not required to dump the same instanceCopying a MySQL Database on the Same Instance without DumpingCopying a database on the same MySQL instance can be done without having to create an int...Programming Posted on 2025-07-03
-
When does a Go web application close the database connection?Managing Database Connections in Go Web ApplicationsIn simple Go web applications that utilize databases like PostgreSQL, the timing of database conne...Programming Posted on 2025-07-03
-
How to Create a Smooth Left-Right CSS Animation for a Div Within Its Container?Generic CSS Animation for Left-Right MovementIn this article, we'll explore creating a generic CSS animation to move a div left and right, reachin...Programming Posted on 2025-07-03
-
Why can't Java create generic arrays?Generic Array Creation ErrorQuestion:When attempting to create an array of generic classes using an expression like:public static ArrayList<myObjec...Programming Posted on 2025-07-03















Study Chinese
- 1 How do you say "walk" in Chinese? 走路 Chinese pronunciation, 走路 Chinese learning
- 2 How do you say "take a plane" in Chinese? 坐飞机 Chinese pronunciation, 坐飞机 Chinese learning
- 3 How do you say "take a train" in Chinese? 坐火车 Chinese pronunciation, 坐火车 Chinese learning
- 4 How do you say "take a bus" in Chinese? 坐车 Chinese pronunciation, 坐车 Chinese learning
- 5 How to say drive in Chinese? 开车 Chinese pronunciation, 开车 Chinese learning
- 6 How do you say swimming in Chinese? 游泳 Chinese pronunciation, 游泳 Chinese learning
- 7 How do you say ride a bicycle in Chinese? 骑自行车 Chinese pronunciation, 骑自行车 Chinese learning
- 8 How do you say hello in Chinese? 你好Chinese pronunciation, 你好Chinese learning
- 9 How do you say thank you in Chinese? 谢谢Chinese pronunciation, 谢谢Chinese learning
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









