
FireDucks: Get performance beyond pandas with zero learning cost!
 Browse:149
Browse:149
Pandas is one of the most popular libraries, when I was looking for an easier way to speed up its performance, I discovered FireDucks and became interested in it!
Comparison with pandas: Why FireDucks?
A Pandas program might encounter a serious performance issue depending on how it has been written. However, being a data scientist, I want to spend more and more time analyzing data rather than improving my code performance. So, it would be great if it could do something like interchange the order of processes and speed up the program performance automatically. For example, Process A =>Process B will be slower, so we will replace it as Process B =>Process A. (Of course, the result is guaranteed to be the same.) It is said that data scientists spend about 45% of their time preparing the data, and when I was thinking of doing something to speed-up the process, I came across a module called FireDucks.
From the FireDucks documentation, it seems to be supported for Linux only platforms. Since I use Windows on my main machine, I would like to try it from WSL2 (Windows Subsystem for Linux), an environment that can run Linux on Windows.
The environment I tried is as follows.
- OS Microsoft Windows 11 Pro
- Version 10.0.22631 Build 22631
- System model Z690 Pro RS
- System Type x64-based
- PC Processor 12th Gen Intel(R) Core(TM) i3–12100, 3300 Mhz, 4 Cores, 8 Logical Processors
- Baseboard Product Z690 Pro RS
- Platform Role Desktop
- Installed Physical Memory (RAM)64.0 GB
Installing and Configuring FireDucks
Install WSL
WSL was installed with the help of the following Microsoft documentation; the Linux distribution is Ubuntu 22.04.1 LTS.
Install FireDucks
Then actually install FireDucks. It is very easy to install, though.
pip install fireducks
It will take a few minutes to install FireDucks (along with pyarrow, pandas and other libraries).
I tried executing below code, the loading speed was so fast, pandas took 4 sec and fireDucks took only 74.5 ns.
# 1. analysis based on time period and creative duration # convert timestamp to date/time object df['timestamp_converted'] = pd.to_datetime(df['timestamp'], unit='s ') # define time period def get_part_of_day(hour): if 5All these data preprocessing and analysis took around 8 seconds in pandas, whereas it could be completed within 4 seconds when using FireDucks. Almost 2 times speed up could be achieved.
Improved performance
One of the most stressful things about using pandas is waiting when loading large data sets, and then I have to wait for complex operation like groupby. On the other hand, since FireDucks does lazy evaluation, loading itself takes no time at all, so processing is done where it is needed, and I felt it was very significant with a great reduction in total waiting time.
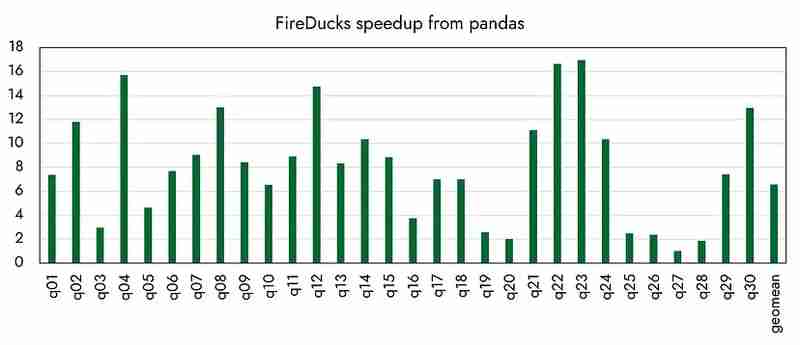
As for other performance, it seems that up to 16 times faster compared to pandas has been achieved, as officially announced by the organization. (I will compare the performance with various competing libraries next time.)
zero learning cost
The ability to follow the exact pandas notation without having to think about anything is a huge advantage. Apart from FireDucks, there are other data frame acceleration libraries, but they are too expensive to learn and too easy to forget.
For example, if you want to add columns with polars, you have to write something like this.
# pandas df["new_col"] = df["A"] 1 # polars df = df.with_columns((pl.col("A") 1).alias("new_col"))Nearly no need to change an existing code
I have several ETLs and other projects that use pandas, and it would be nice to see a performance improvement just by installing and replacing the import statement with FireDucks.
If you wanted to add it further, feel free to comment down below.
-
 Why Does Microsoft Visual C++ Fail to Correctly Implement Two-Phase Template Instantiation?The Mystery of "Broken" Two-Phase Template Instantiation in Microsoft Visual C Problem Statement:Users commonly express concerns that Micro...Programming Posted on 2025-03-12
Why Does Microsoft Visual C++ Fail to Correctly Implement Two-Phase Template Instantiation?The Mystery of "Broken" Two-Phase Template Instantiation in Microsoft Visual C Problem Statement:Users commonly express concerns that Micro...Programming Posted on 2025-03-12 -
UTF-8 vs. Latin-1: The secret of character encoding!Distinguishing UTF-8 and Latin1When dealing with encoding, two prominent choices emerge: UTF-8 and Latin1. Amidst their applications, a fundamental qu...Programming Posted on 2025-03-12
-
Part SQL injection series: Detailed explanation of advanced SQL injection techniquesAuthor: Trix Cyrus Waymap Pentesting tool: Click Here TrixSec Github: Click Here TrixSec Telegram: Click Here Advanced SQL Injection Exploits ...Programming Posted on 2025-03-12
-
How Can We Secure File Uploads Against Malicious Content?Security Concerns with File UploadsUploading files to a server can introduce significant security risks due to the potentially malicious content that ...Programming Posted on 2025-03-12
-
How to Remove Line Breaks from Strings using Regular Expressions in JavaScript?Removing Line Breaks from StringsIn this code scenario, the goal is to eliminate line breaks from a text string read from a textarea using the .value ...Programming Posted on 2025-03-12
-
Is There a Performance Difference Between Using a For-Each Loop and an Iterator for Collection Traversal in Java?For Each Loop vs. Iterator: Efficiency in Collection TraversalIntroductionWhen traversing a collection in Java, the choice arises between using a for-...Programming Posted on 2025-03-12
-
How to Check if an Object Has a Specific Attribute in Python?Method to Determine Object Attribute ExistenceThis inquiry seeks a method to verify the presence of a specific attribute within an object. Consider th...Programming Posted on 2025-03-12
-
Detailed explanation of Java HashSet/LinkedHashSet random element acquisition methodFinding a Random Element in a SetIn programming, it can be useful to select a random element from a collection, such as a set. Java provides multiple ...Programming Posted on 2025-03-12
-
When Do CSS Attributes Fallback to Pixels (px) Without Units?Fallback for CSS Attributes Without Units: A Case StudyCSS attributes often require units (e.g., px, em, %) to specify their values. However, in certa...Programming Posted on 2025-03-12
-
Why Isn\'t My CSS Background Image Appearing?Troubleshoot: CSS Background Image Not AppearingYou've encountered an issue where your background image fails to load despite following tutorial i...Programming Posted on 2025-03-12
-
How to upload files with additional parameters using java.net.URLConnection and multipart/form-data encoding?Uploading Files with HTTP RequestsTo upload files to an HTTP server while also submitting additional parameters, java.net.URLConnection and multipart/...Programming Posted on 2025-03-12
-
How can I merge two images in C#/.NET, centering a smaller image over a larger one while preserving transparency?Merging Images in C#/.NET: A Comprehensive GuideIntroductionCreating captivating visuals by combining multiple images is a common task in various doma...Programming Posted on 2025-03-12
-
How Can I UNION Database Tables with Different Numbers of Columns?Combined tables with different columns] Can encounter challenges when trying to merge database tables with different columns. A straightforward way i...Programming Posted on 2025-03-12
-
Python Read CSV File UnicodeDecodeError Ultimate SolutionUnicode Decode Error in CSV File ReadingWhen attempting to read a CSV file into Python using the built-in csv module, you may encounter an error stati...Programming Posted on 2025-03-12
-
Why Doesn\'t Firefox Display Images Using the CSS `content` Property?Displaying Images with Content URL in FirefoxAn issue has been encountered where certain browsers, specifically Firefox, fail to display images when r...Programming Posted on 2025-03-12















Study Chinese
- 1 How do you say "walk" in Chinese? 走路 Chinese pronunciation, 走路 Chinese learning
- 2 How do you say "take a plane" in Chinese? 坐飞机 Chinese pronunciation, 坐飞机 Chinese learning
- 3 How do you say "take a train" in Chinese? 坐火车 Chinese pronunciation, 坐火车 Chinese learning
- 4 How do you say "take a bus" in Chinese? 坐车 Chinese pronunciation, 坐车 Chinese learning
- 5 How to say drive in Chinese? 开车 Chinese pronunciation, 开车 Chinese learning
- 6 How do you say swimming in Chinese? 游泳 Chinese pronunciation, 游泳 Chinese learning
- 7 How do you say ride a bicycle in Chinese? 骑自行车 Chinese pronunciation, 骑自行车 Chinese learning
- 8 How do you say hello in Chinese? 你好Chinese pronunciation, 你好Chinese learning
- 9 How do you say thank you in Chinese? 谢谢Chinese pronunciation, 谢谢Chinese learning
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









