
如何通過抹布和微調使LLM更準確
 瀏覽:717
瀏覽:717
Imagine studying a module at university for a semester. At the end, after an intensive learning phase, you take an exam – and you can recall the most important concepts without looking them up.
Now imagine the second situation: You are asked a question about a new topic. You don’t know the answer straight away, so you pick up a book or browse a wiki to find the right information for the answer.
These two analogies represent two of the most important methods for improving the basic model of an Llm or adapting it to specific tasks and areas: Retrieval Augmented Generation (RAG) and Fine-Tuning.
But which example belongs to which method?
That’s exactly what I’ll explain in this article: After that, you’ll know what RAG and fine-tuning are, the most important differences and which method is suitable for which application.
Let’s dive in!
Table of contents
- 1. Basics: What is RAG? What is fine-tuning?
- 2. Differences between RAG and fine-tuning
- 3. Ways to build a RAG model
- 4. Options for fine-tuning a model
- 5. When is RAG recommended? When is fine-tuning recommended?
- Final Thoughts
- Where can you continue learning?
1. Basics: What is RAG? What is fine-tuning?
Large Language Models (LLMs) such as ChatGPT from OpenAI, Gemini from Google, Claude from Anthropics or Deepseek are incredibly powerful and have established themselves in everyday work over an extremely short time.
One of their biggest limitations is that their knowledge is limited to training. A model that was trained in 2024 does not know events from 2025. If we ask the 4o model from ChatGPT who the current US President is and give the clear instruction that the Internet should not be used, we see that it cannot answer this question with certainty:
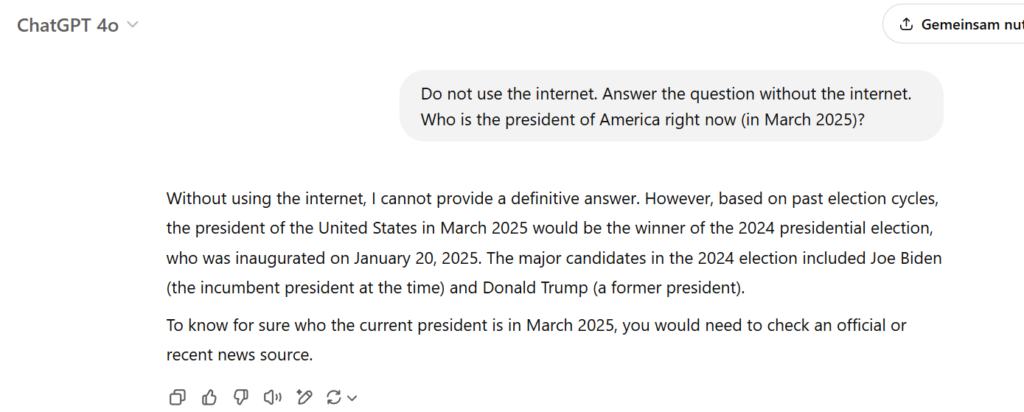
In addition, the models cannot easily access company-specific information, such as internal guidelines or current technical documentation.
This is exactly where RAG and fine-tuning come into play.
Both methods make it possible to adapt an LLM to specific requirements:
RAG — The model remains the same, the input is improved
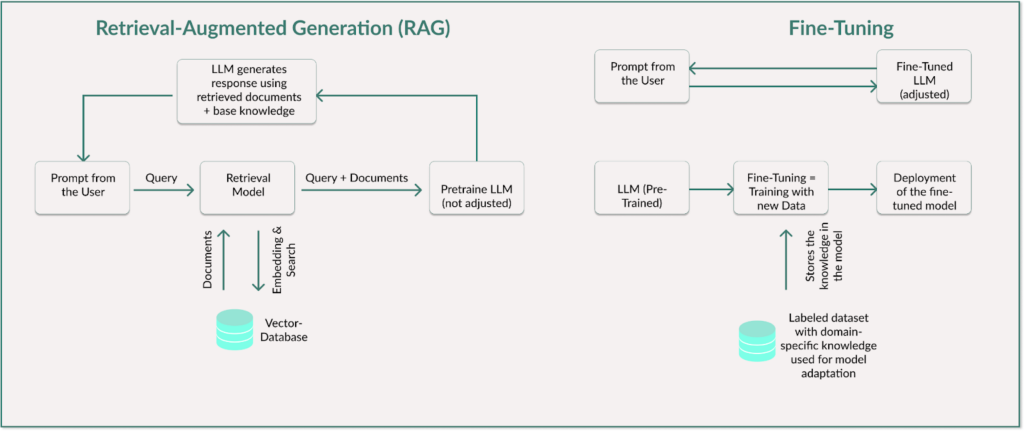
An LLM with Retrieval Augmented Generation (RAG) remains unchanged.
However, it gains access to an external knowledge source and can therefore retrieve information that is not stored in its model parameters. RAG extends the model in the inference phase by using external data sources to provide the latest or specific information. The inference phase is the moment when the model generates an answer.
This allows the model to stay up to date without retraining.
How does it work?
- A user question is asked.
- The query is converted into a vector representation.
- A retriever searches for relevant text sections or data records in an external data source. The documents or FAQS are often stored in a vector database.
- The content found is transferred to the model as additional context.
- The LLM generates its answer on the basis of the retrieved and current information.
The key point is that the LLM itself remains unchanged and the internal weights of the LLM remain the same.
Let’s assume a company uses an internal AI-powered support chatbot.
The chatbot helps employees to answer questions about company policies, IT processes or HR topics. If you would ask ChatGPT a question about your company (e.g. How many vacation days do I have left?), the model would logically not give you back a meaningful answer. A classic LLM without RAG would know nothing about the company – it has never been trained with this data.
This changes with RAG: The chatbot can search an external database of current company policies for the most relevant documents (e.g. PDF files, wiki pages or internal FAQs) and provide specific answers.
RAG works similarly as when we humans look up specific information in a library or Google search – but in real-time.
A student who is asked about the meaning of CRUD quickly looks up the Wikipedia article and answers Create, Read, Update and Delete – just like a RAG model retrieves relevant documents. This process allows both humans and AI to provide informed answers without memorizing everything.
And this makes RAG a powerful tool for keeping responses accurate and current.
Fine-tuning — The model is trained and stores knowledge permanently
Instead of looking up external information, an LLM can also be directly updated with new knowledge through fine-tuning.
Fine-tuning is used during the training phase to provide the model with additional domain-specific knowledge. An existing base model is further trained with specific new data. As a result, it “learns” specific content and internalizes technical terms, style or certain content, but retains its general understanding of language.
This makes fine-tuning an effective tool for customizing LLMs to specific needs, data or tasks.
How does this work?
- The LLM is trained with a specialized data set. This data set contains specific knowledge about a domain or a task.
- The model weights are adjusted so that the model stores the new knowledge directly in its parameters.
- After training, the model can generate answers without the need for external sources.
Let’s now assume we want to use an LLM that provides us with expert answers to legal questions.
To do this, this LLM is trained with legal texts so that it can provide precise answers after fine-tuning. For example, it learns complex terms such as “intentional tort” and can name the appropriate legal basis in the context of the relevant country. Instead of just giving a general definition, it can cite relevant laws and precedents.
This means that you no longer just have a general LLM like GPT-4o at your disposal, but a useful tool for legal decision-making.
If we look again at the analogy with humans, fine-tuning is comparable to having internalized knowledge after an intensive learning phase.
After this learning phase, a computer science student knows that the term CRUD stands for Create, Read, Update, Delete. He or she can explain the concept without needing to look it up. The general vocabulary has been expanded.
This internalization allows for faster, more confident responses—just like a fine-tuned LLM.
2. Differences between RAG and fine-tuning
Both methods improve the performance of an LLM for specific tasks.
Both methods require well-prepared data to work effectively.
And both methods help to reduce hallucinations – the generation of false or fabricated information.
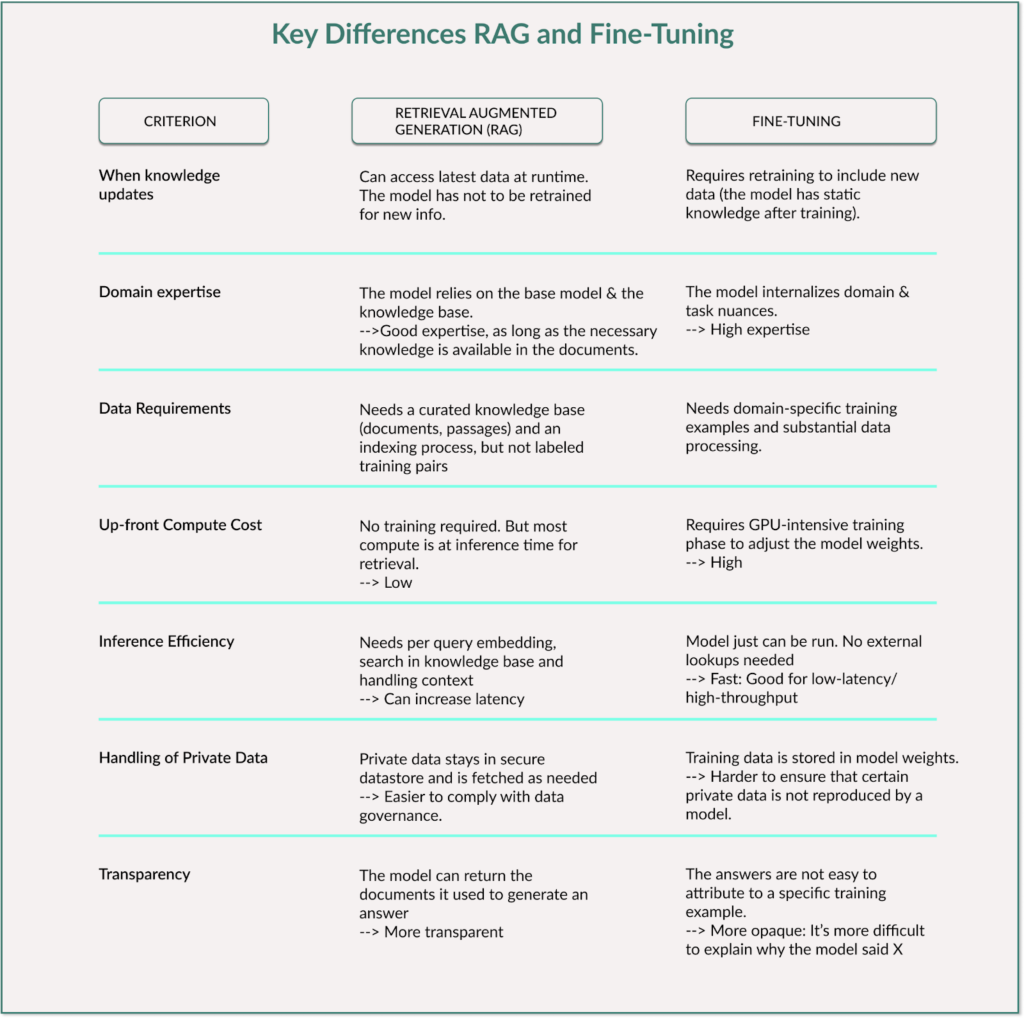
But if we look at the table below, we can see the differences between these two methods:
RAG is particularly flexible because the model can always access up-to-date data without having to be retrained. It requires less computational effort in advance, but needs more resources while answering a question (inference). The latency can also be higher.
Fine-tuning, on the other hand, offers faster inference times because the knowledge is stored directly in the model weights and no external search is necessary. The major disadvantage is that training is time-consuming and expensive and requires large amounts of high-quality training data.
RAG provides the model with tools to look up knowledge when needed without changing the model itself, whereas fine-tuning stores the additional knowledge in the model with adjusted parameters and weights.
3. Ways to build a RAG model
A popular framework for building a Retrieval Augmented Generation (RAG) pipeline is LangChain. This framework facilitates the linking of LLM calls with a retrieval system and makes it possible to retrieve information from external sources in a targeted manner.
How does RAG work technically?
1. Query embedding
In the first step, the user request is converted into a vector using an embedding model. This is done, for example, with text-embedding-ada-002 from OpenAI or all-MiniLM-L6-v2 from Hugging Face.
This is necessary because vector databases do not search through conventional texts, but instead calculate semantic similarities between numerical representations (embeddings). By converting the user query into a vector, the system can not only search for exactly matching terms, but also recognize concepts that are similar in content.
2. Search in the vector database
The resulting query vector is then compared with a vector database. The aim is to find the most relevant information to answer the question.
This similarity search is carried out using Approximate Nearest Neighbors (ANN) algorithms. Well-known open source tools for this task are, for example, FAISS from Meta for high-performance similarity searches in large data sets or ChromaDB for small to medium-sized retrieval tasks.
3. Insertion into the LLM context
In the third step, the retrieved documents or text sections are integrated into the prompt so that the LLM generates its response based on this information.
4. Generation of the response
The LLM now combines the information received with its general language vocabulary and generates a context-specific response.
An alternative to LangChain is the Hugging Face Transformer Library, which provides specially developed RAG classes:
- ‘RagTokenizer’ tokenizes the input and the retrieval result. The class processes the text entered by the user and the retrieved documents.
- The ‘RagRetriever’ class performs the semantic search and retrieval of relevant documents from the predefined knowledge base.
- The ‘RagSequenceForGeneration’ class takes the documents provided, integrates them into the context and transfers them to the actual language model for answer generation.
4. Options for fine-tuning a model
While an LLM with RAG uses external information for the query, with fine-tuning we change the model weights so that the model permanently stores the new knowledge.
How does fine-tuning work technically?
1. Preparation of the training data
Fine-tuning requires a high-quality collection of data. This collection consists of inputs and the desired model responses. For a chatbot, for example, these can be question-answer pairs. For medical models, this could be clinical reports or diagnostic data. For a legal AI, these could be legal texts and judgments.
Let’s take a look at an example: If we look at the documentation of OpenAI, we see that these models use a standardized chat format with roles (system, user, assistant) during fine-tuning. The data format of these question-answer pairs is JSONL and looks like this, for example:
{"messages": [{"role": "system", "content": "Du bist ein medizinischer Assistent."}, {"role": "user", "content": "Was sind Symptome einer Grippe?"}, {"role": "assistant", "content": "Die häufigsten Symptome einer Grippe sind Fieber, Husten, Muskel- und Gelenkschmerzen."}]}
Other models use other data formats such as CSV, JSON or PyTorch datasets.
2. Selection of the base model
We can use a pre-trained LLM as a starting point. These can be closed-source models such as GPT-3.5 or GPT-4 via OpenAI API or open-source models such as DeepSeek, LLaMA, Mistral or Falcon or T5 or FLAN-T5 for NLP tasks.
3. Training of the model
Fine-tuning requires a lot of computing power, as the model is trained with new data to update its weights. Especially large models such as GPT-4 or LLaMA 65B require powerful GPUs or TPUs.
To reduce the computational effort, there are optimized methods such as LoRA (Low-Rank Adaption), where only a small number of additional parameters are trained, or QLoRA (Quantized LoRA), where quantized model weights (e.g. 4-bit) are used.
4. Model deployment & use
Once the model has been trained, we can deploy it locally or on a cloud platform such as Hugging Face Model Hub, AWS or Azure.
5. When is RAG recommended? When is fine-tuning recommended?
RAG and fine-tuning have different advantages and disadvantages and are therefore suitable for different use cases:
RAG is particularly suitable when content is updated dynamically or frequently.
For example, in FAQ chatbots where information needs to be retrieved from a knowledge database that is constantly expanding. Technical documentation that is regularly updated can also be efficiently integrated using RAG – without the model having to be constantly retrained.
Another point is resources: If limited computing power or a smaller budget is available, RAG makes more sense as no complex training processes are required.
Fine-tuning, on the other hand, is suitable when a model needs to be tailored to a specific company or industry.
The response quality and style can be improved through targeted training. For example, the LLM can then generate medical reports with precise terminology.
The basic rule is: RAG is used when the knowledge is too extensive or too dynamic to be fully integrated into the model, while fine-tuning is the better choice when consistent, task-specific behavior is required.
And then there’s RAFT — the magic of combination
What if we combine the two?
That’s exactly what happens with Retrieval Augmented Fine-Tuning (RAFT).
The model is first enriched with domain-specific knowledge through fine-tuning so that it understands the correct terminology and structure. The model is then extended with RAG so that it can integrate specific and up-to-date information from external data sources. This combination ensures both deep expertise and real-time adaptability.
Companies use the advantages of both methods.
Final thoughts
Both methods—RAG and fine-tuning—extend the capabilities of a basic LLM in different ways.
Fine-tuning specializes the model for a specific domain, while RAG equips it with external knowledge. The two methods are not mutually exclusive and can be combined in hybrid approaches. Looking at computational costs, fine-tuning is resource-intensive upfront but efficient during operation, whereas RAG requires fewer initial resources but consumes more during use.
RAG is ideal when knowledge is too vast or dynamic to be integrated directly into the model. Fine-tuning is the better choice when stability and consistent optimization for a specific task are required. Both approaches serve distinct but complementary purposes, making them valuable tools in AI applications.
On my Substack, I regularly write summaries about the published articles in the fields of Tech, Python, Data Science, Machine Learning and AI. If you’re interested, take a look or subscribe.
Where can you continue learning?
- OpenAI Documentation – Fine-tuning
- Hugging Face Blog QLoRA
- Microsoft Learn – Augment LLMs with RAG or fine-tuning
- IBM Technology YouTube – RAG vs. Fine Tuning
- DataCamp Blog – What is RAFT?
- DataCamp Blog – RAG vs. Fine-Tuning
-
 Excel SUMPRODUCT函數詳解 - 數據分析學院Excel的SumProduct函數:數據分析PowerHouse 解鎖Excel的Sumproduct函數的功能,以用於簡化數據分析。這種多功能功能毫不費力地結合了求和功能,擴展到跨相應範圍或數組的加法,減法和分裂。 無論您是分析趨勢還是解決複雜的計算,Sumproduct都會將數字轉換為可...人工智慧 發佈於2025-04-16
Excel SUMPRODUCT函數詳解 - 數據分析學院Excel的SumProduct函數:數據分析PowerHouse 解鎖Excel的Sumproduct函數的功能,以用於簡化數據分析。這種多功能功能毫不費力地結合了求和功能,擴展到跨相應範圍或數組的加法,減法和分裂。 無論您是分析趨勢還是解決複雜的計算,Sumproduct都會將數字轉換為可...人工智慧 發佈於2025-04-16 -
深度研究全面開放,ChatGPT Plus用戶福利Openai的深入研究:改變遊戲的AI研究 Openai已為所有Chatgpt加上訂戶釋放了深入的研究,並承諾在研究效率方面具有重大提高。 在測試了雙子座,Grok 3和困惑等競爭對手的類似功能之後,我可以自信地將Openai的深入研究宣佈為出色的選擇。此博客深入研究了它的功能。 目錄 什麼是...人工智慧 發佈於2025-04-16
-
亞馬遜Nova Today真實體驗與評測 - Analytics Vidhya亚马逊最近的回复:Invent 2024活动展示了Nova,这是其最先进的基础模型套件,旨在彻底改变AI和内容创建。本文深入研究了Nova的架构,通过动手实例探索其功能,并检查基准结果。 我们将介绍功能,评论,基准和对AI应用程序的影响。 [2 此探索将涵盖Amazon Nova的功能,详细的评论...人工智慧 發佈於2025-04-16
-
ChatGPT定時任務功能的5種使用方法Chatgpt的新計劃任務:使用AI 自動化您的一天 Chatgpt最近引入了一個改變遊戲規則的功能:計劃的任務。 這允許用戶自動化重複提示,即使在離線時,也可以在預定時間接收通知或響應。想像一下每天策劃的新聞通訊,自動化工作時間表或及時的習慣提醒 - 所有這些都是由Chatgpt自動處理的。...人工智慧 發佈於2025-04-16
-
三款AI聊機器人對同一提示的反應,哪個最佳?這是我發現的。 在精心策劃且詳細的提示中扮演著質量良好的提示,在輸出的質量中扮演任何cathbot生產的質量。與所有工具一樣,輸出僅與使用該工具的人的技能一樣好。 AI聊天機器人沒有什麼不同。 有了這種理解,我指示每個模型創建一個針對個人理財的基本指南。這種方法使我能夠評估多個相互聯繫的主題(特...人工智慧 發佈於2025-04-15
-
ChatGPT足矣,無需專用AI聊機在一個新的AI聊天機器人每天啟動的世界中,決定哪一個是正確的“一個”。但是,以我的經驗,chatgpt處理了我所丟下的幾乎所有內容,而無需在平台之間切換,只需稍有及時的工程。 在許多實踐應用程序中可能會讓您感到驚訝。它的範圍令人印象深刻,使用戶可以生成代碼段,草稿求職信,甚至翻譯語言。這種多功能性...人工智慧 發佈於2025-04-14
-
印度AI時刻:與中美在生成AI領域競賽印度的AI抱負:2025 Update 與中國和美國在生成AI上進行了大量投資,印度正在加快自己的Genai計劃。 不可否認的是,迫切需要迎合印度各種語言和文化景觀的土著大語模型(LLM)和AI工具。 本文探討了印度新興的Genai生態系統,重點介紹了2025年工會預算,公司參與,技能開發計劃...人工智慧 發佈於2025-04-13
-
使用Airflow和Docker自動化CSV到PostgreSQL的導入本教程演示了使用Apache氣流,Docker和PostgreSQL構建強大的數據管道,以使數據傳輸從CSV文件自動化到數據庫。 我們將介紹有效工作流程管理的核心氣流概念,例如DAG,任務和操作員。 該項目展示了創建可靠的數據管道,該數據管線讀取CSV數據並將其寫入PostgreSQL數據庫。我們...人工智慧 發佈於2025-04-12
-
群智能算法:三個Python實現Imagine watching a flock of birds in flight. There's no leader, no one giving directions, yet they swoop and glide together in perfect harmony. It may...人工智慧 發佈於2025-03-24
-
如何通過抹布和微調使LLM更準確Imagine studying a module at university for a semester. At the end, after an intensive learning phase, you take an exam – and you can recall th...人工智慧 發佈於2025-03-24
-
什麼是Google Gemini?您需要了解的有關Google Chatgpt競爭對手的一切Google recently released its new Generative AI model, Gemini. It results from a collaborative effort by a range of teams at Google, including members ...人工智慧 發佈於2025-03-23
-
與DSPY提示的指南DSPY(聲明性的自我改善語言程序)通過抽象及時工程的複雜性來徹底改變LLM應用程序的開發。 本教程提供了使用DSPY的聲明方法來構建強大的AI應用程序的綜合指南。 [2 抓取DSPY的聲明方法,用於簡化LLM應用程序開發。 了解DSPY如何自動化提示工程並優化複雜任務的性能。 探索實用的D...人工智慧 發佈於2025-03-22
-
自動化博客到Twitter線程本文详细介绍了使用Google的Gemini-2.0 LLM,Chromadb和Shiplit自动化长效内容的转换(例如博客文章)。 手动线程创建耗时;此应用程序简化了该过程。 [2 [2 使用Gemini-2.0,Chromadb和Shatlit自动化博客到twitter线程转换。 获得实用的经...人工智慧 發佈於2025-03-11
-
人工免疫系統(AIS):python示例的指南本文探討了人造免疫系統(AIS),這是受人類免疫系統識別和中和威脅的非凡能力啟發的計算模型。 我們將深入研究AIS的核心原理,檢查諸如克隆選擇,負面選擇和免疫網絡理論之類的關鍵算法,並用Python代碼示例說明其應用。 [2 抗體:識別並結合特定威脅(抗原)。在AIS中,這些代表了問題的潛在解決方...人工智慧 發佈於2025-03-04
-
試著向 ChatGPT 詢問這些關於您自己的有趣問題有没有想过 ChatGPT 了解您的哪些信息?随着时间的推移,它如何处理您提供给它的信息?我在不同的场景中使用过 ChatGPT 堆,在特定的交互后看看它会说什么总是很有趣。✕ 删除广告 所以,为什么不尝试向 ChatGPT 询问其中一些问题来看看它对你的真实看法是什么? 我理想生活中的...人工智慧 發佈於2024-11-22















學習中文
- 1 走路用中文怎麼說? 走路中文發音,走路中文學習
- 2 坐飛機用中文怎麼說? 坐飞机中文發音,坐飞机中文學習
- 3 坐火車用中文怎麼說? 坐火车中文發音,坐火车中文學習
- 4 坐車用中文怎麼說? 坐车中文發音,坐车中文學習
- 5 開車用中文怎麼說? 开车中文發音,开车中文學習
- 6 游泳用中文怎麼說? 游泳中文發音,游泳中文學習
- 7 騎自行車用中文怎麼說? 骑自行车中文發音,骑自行车中文學習
- 8 你好用中文怎麼說? 你好中文發音,你好中文學習
- 9 謝謝用中文怎麼說? 谢谢中文發音,谢谢中文學習
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









