
什麼是Google Gemini?您需要了解的有關Google Chatgpt競爭對手的一切
 瀏覽:417
瀏覽:417
Google recently released its new Generative AI model, Gemini. It results from a collaborative effort by a range of teams at Google, including members of Google Research.
The model, which Google refers to as the most capable and general-purpose AI they’ve developed thus far, was designed to be multimodal. This means Gemini can comprehend various data types such as text, audio, images, video, and code.
For the remainder of this article, we’re going to cover:
- What is Gemini?
- What are the versions of Gemini?
- How can you access Gemini?
- Gemini Benchmarks Explored
- Gemini vs. GPT-4
- Use-Cases For Gemini
What is Google Gemini?
On December 6, 2023, Google DeepMind announced Gemini 1.0. Upon release, Google described it as their most advanced set of Large Language Models (LLMs), thus superseding the Pathways Langauge Model (PaLM 2), which debuted in May of the same year.
Gemini defines a family of multimodal LLMs capable of understanding texts, images, videos, and audio. It’s also said to be capable of performing complex tasks in math and physics, as well as being able to generate high-quality code in several programming languages.
Fun fact: Sergey Brin, Google’s co-founder, is credited as one of the contributors to the Gemini model.
Until recently, the standard procedure for developing multimodal models consisted of training individual components for various modalities and then piecing them together to mimic some of the functionality. Such models would occasionally excel at performing certain tasks, like describing images, but they have trouble with more sophisticated and complex reasoning.
Gemini was designed to be natively multimodal; thus, it was pre-trained on several modalities from the beginning. To further refine its efficacy, Google fine-tuned it with additional multimodal data.
Consequently, Gemini is significantly more capable than existing multimodal models in understanding and reasoning about a wide range of inputs from the ground up, according to Sundar Pichai, the CEO of Google and Alphabet, and Demis Hassabis, CEO and Co-Found of Google DeepMind. They also state that Gemini’s capabilities are “state of the art in nearly every domain.”
Google Gemini Key Features
The key features of the Gemini model include:
1. Understanding text, images, audio, and more
Multimodal AI is a new AI paradigm gaining traction in which different data types are merged with multiple algorithms to achieve a higher performance. Gemini leverages this paradigm, meaning it integrates well with various data types. You can input images, audio, text, and other data types, resulting in more natural AI interactions.
2. Reliability, scalability, and efficiency
Gemini leverages Google’s TPUv5 chips, thus reportedly making it five times stronger than GPT-4. Faster processing makes Gemini capable of tackling complex tasks relatively easily and handling multiple requests simultaneously.
3. Sophisticated reasoning
Gemini was trained on an enormous dataset of text and code. This ensures the model can access the most up-to-date information and provide accurate and reliable responses to your queries. According to Google, the model outperforms OpenAI’s GPT-4 and “expert level” humans in various intelligence tests (e.g., MMLU benchmark).
4. Advanced coding
Gemini 1.0 can understand, explain, and generate high-quality code in the most widely used programming languages, such as Python, Java, C , and Go – this makes it one of the leading foundation models for coding globally.
The model also excels in several coding benchmarks, including HumanEval, a highly-regarded industry standard for evaluating performance on coding tasks; it also performed well on Google’s internal, held-out dataset, which leverages author-generated code instead of information from the web.
5. Responsibility and safety
New protections were added to Google’s AI Principles and policies to account for Gemini’s multimodal capabilities. Google says, “Gemini has the most comprehensive safety evaluations of any Google AI model to date, including for bias and toxicity.” They also said they’ve “conducted novel research into potential risk areas like cyber-offense, persuasion, and autonomy, and have applied Google Research’s best-in-class adversarial testing techniques to help identify critical safety issues in advance of Gemini’s deployment.”
What Are The Versions of Gemini?
Google says Gemini, the successor to LaMDA and PaLM 2, is their “most flexible model yet — able to efficiently run on everything from data centers to mobile devices.” They also believe Gemini’s state-of-the-art capabilities will improve how developers and business clients build and scale with AI.
The first version of Gemini, unsurprisingly named Gemini 1.0, was released in three different sizes:
- Gemini Nano — Gemini Nano is the most efficient model for on-device tasks that require efficient AI processing without connecting to external servers. In other words, it’s designed to run on smartphones, specifically the Google Pixel 8.
- Gemini Pro — Gemini Pro is the optimal model for scaling across various tasks. It’s designed to power Bard, Google’s most recent AI chatbot; thus, it can understand complex queries and respond rapidly.
- Gemini Ultra — Gemini Ultra is the largest and most capable model for complex tasks, exceeding the current state-of-the-art results in 30 of the 32 commonly used benchmarks for large language model (LLM) research and development.
How Can You Access Gemini?
Since December 13, 2023, developers and enterprise customers have been able to access Gemini Pro through Gemini’s API in Google AI Studio or Google Cloud Vertex AI.
Note Google AI Studio is a freely available browser-based IDE that developers can use to prototype generative models and easily launch applications using an API key. Google Cloud Vertex, on the other hand, is a fully managed AI platform that offers all of the tools required to build and use generative AI. According to Google, “Vertex AI allows customization of Gemini with full data control and benefits from additional Google Cloud features for enterprise security, safety, privacy and data governance and compliance.”
Through AICore, a new system feature with Android 14, Android developers, starting from Pixel 8 Pro devices, can build with Gemini Nano, the most efficient model for on-device tasks.
Gemini Benchmarks Explored
The Gemini models underwent extensive testing to assess their performance across a broad range of tasks before their release. Google says its Gemini Ultra model outperforms the existing state-of-the-art results on 30 of the 32 commonly used academic benchmarks for Large Language Model (LLM) research and development. Note these tasks range from natural image, audio, and video understanding to mathematical reasoning.
In an Gemini introductory blog post, Google claims Gemini Ultra is the first-ever model to outperform human experts on Massive Multitask Language Understanding (MMLU) with a score of 90.0%. Note that MMLU incorporates 57 different subjects, including math, physics, history, law, medicine, and ethics, to assess one’s ability to solve problems and a general understanding of the world.
The new MMLU benchmark method to MMLU enables Gemini to make significant improvements instead of merely leveraging its first impressions by using its reasoning power to deliberate more thoroughly before responding to challenging questions.
Here’s how Gemini performed on text tasks:
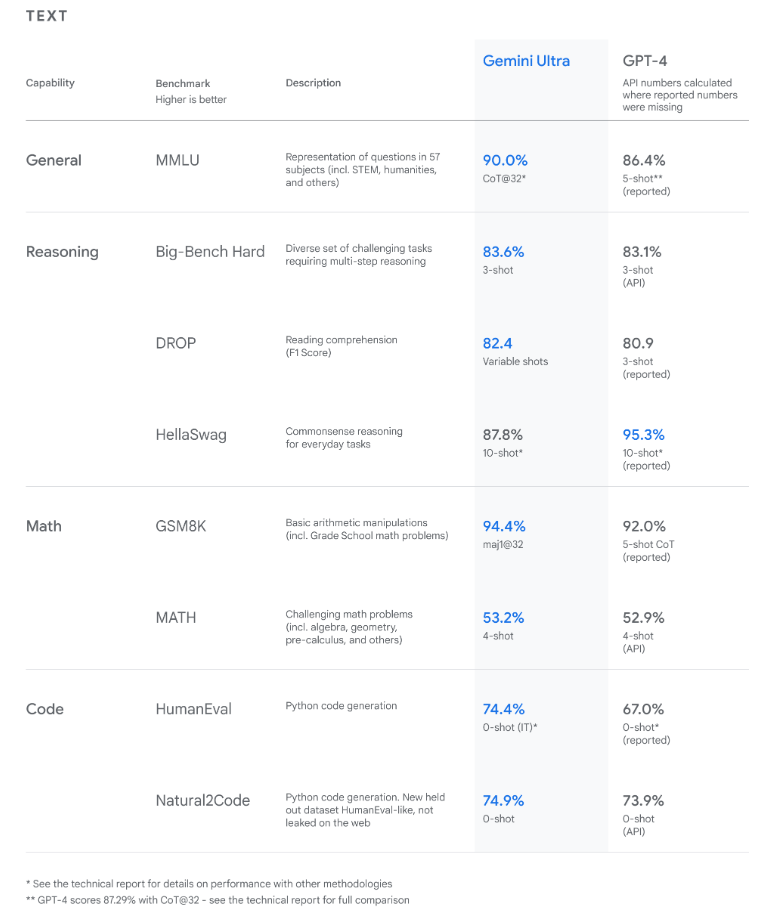
The findings reveal Gemini surpasses state-of-the-art performance on a wide range of benchmarks, including text and coding. [Source]
The Gemini Ultra model also achieved state-of-the-art on the new Massive Multidiscipline Multimodal Understanding (MMMU) benchmark with a score of 59.4%. This assessment consists of multimodal tasks across various domains requiring deliberate reasoning.
Google said, “With the image benchmarks we tested, Gemini Ultra outperformed previous state-of-the-art models without assistance from optical character recognition (OCR) systems that extract text from images for further processing.”
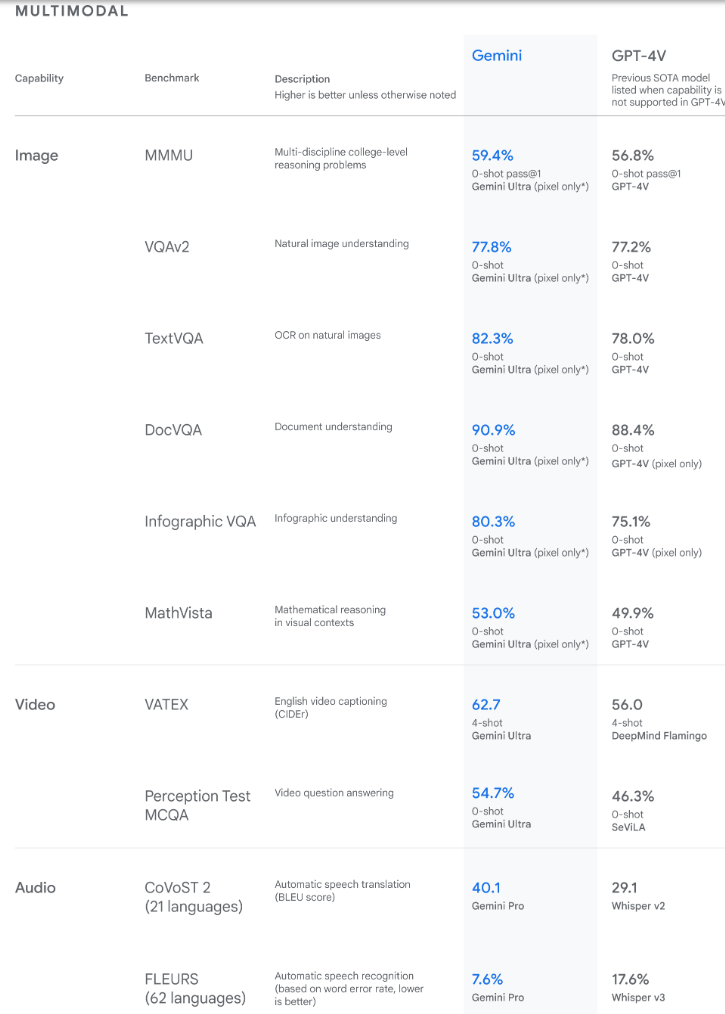
The findings reveal Gemini also surpasses state-of-the-art performance on a wide range of multimodal benchmarks. [Source]
The benchmarks set by Gemini demonstrate the model's innate multimodality and show early evidence of its capacity for more sophisticated reasoning.
Gemini vs. GPT-4
The obvious question that typically arises next is, “How does Gemini compare to GPT-4?”
Both models have similar feature sets and can interact with and interpret text, image, video, audio, and code data, enabling users to apply them to various tasks.
Users of both tools have the option to fact-check, but how they go about providing this functionality is different. Where OpenAI’s GPT-4 provides source links for the claims it makes, Gemini enables users to perform a Google search to confirm the response by clicking a button.
It’s also possible to augment both models with additional extensions, although, at the time of writing, Google’s Gemini model is much more limited.
For example, it’s possible to utilize Google tools such as flights, maps, YouTube, and their range of Workspace applications with Gemini. In contrast, there’s a far larger selection of plug-ins and extensions available for OpenAI's GPT-4, of which most are created by third parties. On-the-fly image creation is also possible with GPT-4; Gemini is designed to be capable of such functionality, but, at the time of writing, it cannot.
On the other hand, Gemini’s response times are faster than that of GPT-4, which can occasionally be slowed down or entirely interrupted due to the sheer volume of users on the platform.
Use-Cases For Gemini
Google’s Gemini models can perform various tasks across several modalities, such as text, audio, image, and video comprehension.
Combining different modalities to understand and generate output is also possible due to Gemini’s multimodal nature.
Examples of use cases for Gemini include:
Text summarization
Gemini models can summarize content from various data types. According to a research paper titled GEMINI: Controlling The Sentence-Level Summary Style in Abstractive Text Summarization, the Gemini model “integrates rewrites and a generator to mimic sentence rewriting and abstracting techniques, respectively.”
Namely, Gemini adaptively selects whether to rewrite a specific document sentence or generate a summary sentence entirely from scratch. The findings of the experiments revealed that the approach used by Gemini outperformed the pure abstractive and rewriting baselines on three benchmark datasets, achieving the best results on WikiHow.
Text generation
Gemini can generate text-based input in response to a user prompt - this text can also be driven by a Q&A-style chatbot interface. Thus, Gemini can be deployed to handle customer inquiries and offer assistance in a natural yet engaging manner, which can free up the responsibilities of human agents to apply themselves more to complex tasks and improve customer satisfaction.
It may also be used for creative writing, such as co-authoring a novel, writing poetry in various styles, or generating scripts for movies and plays. This can significantly boost the productivity of creative writers and reduce the tension caused by writer's block.
Text translation & Audio processing
With their broad multilingual capabilities, the Gemini models can understand and translate over 100 different languages. According to Google, Gemini surpasses Chat GPT-4V’s state-of-the-art performance “on a range of multimodal benchmarks,” such as automatic speech recognition (ASR) and automatic speech translation.
Image & video processing
Gemini can understand and interpret images, making it suitable for image captioning and visual Q&A use cases. The model can also parse complex visuals, including diagrams, figures, and charts, without requiring external OCR tools.
Code analysis and generation
Developers can use Gemini to solve complex coding tasks and debug their code. The model is capable of understanding, explaining, and generating in the most used programming languages, such as Python, Java, C , and Go.
Conclusion
Google’s new set of multimodal Large Language Models (LLMs), Gemini, is the successor to LaMDA and PaLM 2. They describe it as their most advanced set of LLMs capable of understanding texts, images, videos, audio, and complex tasks like math and physics. Gemini is also capable of generating high-quality code in many of the most popular programming languages.
The model has achieved state-of-the-art capability in various tasks, and many at Google believe it represents a significant leap forward in how AI can help improve our daily lives.
Continue your learning with the following resources:
- LlamaIndex: Adding Personal Data to LLMs
- The Top 10 ChatGPT Alternatives You Can Try Today
- Introduction to ChatGPT
And before you go, don't forget to subscribe to our YouTube channel. We have great content for all the most relevant and trending topics, including a tutorial on how to build multimodal apps with Gemini, so do have a look.
-
 印度AI時刻:與中美在生成AI領域競賽印度的AI抱負:2025 Update 與中國和美國在生成AI上進行了大量投資,印度正在加快自己的Genai計劃。 不可否認的是,迫切需要迎合印度各種語言和文化景觀的土著大語模型(LLM)和AI工具。 本文探討了印度新興的Genai生態系統,重點介紹了2025年工會預算,公司參與,技能開發計劃...人工智慧 發佈於2025-04-13
印度AI時刻:與中美在生成AI領域競賽印度的AI抱負:2025 Update 與中國和美國在生成AI上進行了大量投資,印度正在加快自己的Genai計劃。 不可否認的是,迫切需要迎合印度各種語言和文化景觀的土著大語模型(LLM)和AI工具。 本文探討了印度新興的Genai生態系統,重點介紹了2025年工會預算,公司參與,技能開發計劃...人工智慧 發佈於2025-04-13 -
使用Airflow和Docker自動化CSV到PostgreSQL的導入本教程演示了使用Apache氣流,Docker和PostgreSQL構建強大的數據管道,以使數據傳輸從CSV文件自動化到數據庫。 我們將介紹有效工作流程管理的核心氣流概念,例如DAG,任務和操作員。 該項目展示了創建可靠的數據管道,該數據管線讀取CSV數據並將其寫入PostgreSQL數據庫。我們...人工智慧 發佈於2025-04-12
-
群智能算法:三個Python實現Imagine watching a flock of birds in flight. There's no leader, no one giving directions, yet they swoop and glide together in perfect harmony. It may...人工智慧 發佈於2025-03-24
-
如何通過抹布和微調使LLM更準確Imagine studying a module at university for a semester. At the end, after an intensive learning phase, you take an exam – and you can recall th...人工智慧 發佈於2025-03-24
-
什麼是Google Gemini?您需要了解的有關Google Chatgpt競爭對手的一切Google recently released its new Generative AI model, Gemini. It results from a collaborative effort by a range of teams at Google, including members ...人工智慧 發佈於2025-03-23
-
與DSPY提示的指南DSPY(聲明性的自我改善語言程序)通過抽象及時工程的複雜性來徹底改變LLM應用程序的開發。 本教程提供了使用DSPY的聲明方法來構建強大的AI應用程序的綜合指南。 [2 抓取DSPY的聲明方法,用於簡化LLM應用程序開發。 了解DSPY如何自動化提示工程並優化複雜任務的性能。 探索實用的D...人工智慧 發佈於2025-03-22
-
自動化博客到Twitter線程本文详细介绍了使用Google的Gemini-2.0 LLM,Chromadb和Shiplit自动化长效内容的转换(例如博客文章)。 手动线程创建耗时;此应用程序简化了该过程。 [2 [2 使用Gemini-2.0,Chromadb和Shatlit自动化博客到twitter线程转换。 获得实用的经...人工智慧 發佈於2025-03-11
-
人工免疫系統(AIS):python示例的指南本文探討了人造免疫系統(AIS),這是受人類免疫系統識別和中和威脅的非凡能力啟發的計算模型。 我們將深入研究AIS的核心原理,檢查諸如克隆選擇,負面選擇和免疫網絡理論之類的關鍵算法,並用Python代碼示例說明其應用。 [2 抗體:識別並結合特定威脅(抗原)。在AIS中,這些代表了問題的潛在解決方...人工智慧 發佈於2025-03-04
-
試著向 ChatGPT 詢問這些關於您自己的有趣問題有没有想过 ChatGPT 了解您的哪些信息?随着时间的推移,它如何处理您提供给它的信息?我在不同的场景中使用过 ChatGPT 堆,在特定的交互后看看它会说什么总是很有趣。✕ 删除广告 所以,为什么不尝试向 ChatGPT 询问其中一些问题来看看它对你的真实看法是什么? 我理想生活中的...人工智慧 發佈於2024-11-22
-
您仍然可以透過以下方式嘗試神秘的 GPT-2 聊天機器人如果您對人工智慧模型或聊天機器人感興趣,您可能已經看過有關神秘的 GPT-2 聊天機器人及其有效性的討論。 在這裡,我們解釋什麼是 GPT-2 聊天機器人以及如何使用存取它。 什麼是 GPT-2 聊天機器人? 2024年4月下旬,一個名為gpt2-chatbot的神秘AI模型在LLM測試和基準測試...人工智慧 發佈於2024-11-08
-
ChatGPT 的 Canvas 模式很棒:有 4 種使用方法ChatGPT 的新 Canvas 模式為世界領先的生成式 AI 工具中的寫作和編輯增添了額外的維度。自從 ChatGPT Canvas 推出以來,我一直在使用它,並找到了幾種不同的方法來使用這個新的 AI 工具。 ✕ 刪除廣告 1 文本編輯 ChatGPT Canvas 是如果你想編輯...人工智慧 發佈於2024-11-08
-
ChatGPT 的自訂 GPT 如何暴露您的資料以及如何確保其安全ChatGPT 的自訂 GPT 功能允許任何人為幾乎任何你能想到的東西創建自訂 AI 工具;創意、技術、遊戲、自訂 GPT 都可以做到。更好的是,您可以與任何人分享您的自訂 GPT 創建。 但是,透過分享您的自訂 GPT,您可能會犯下一個代價高昂的錯誤,將您的資料暴露給全球數千人。 什麼是自訂...人工智慧 發佈於2024-11-08
-
ChatGPT 可協助您在 LinkedIn 上找到工作的 10 種方式LinkedIn 个人资料的“关于”部分有 2,600 个可用字符,是阐述您的背景、技能、热情和未来目标的绝佳空间。查看您的 LinkedIn 简历,作为您的专业背景、技能和抱负的简明摘要。 向 ChatGPT 提供您所有获胜品质的列表,或将您的简历复制粘贴到其中。要求聊天机器人使用这些信息撰写...人工智慧 發佈於2024-11-08
-
查看這 6 個鮮為人知的 AI 應用程序,它們可提供獨特的體驗目前,大多数人都听说过 ChatGPT 和 Copilot,这两款引领 AI 热潮的开创性生成式 AI 应用程序。但是您知道吗,大量鲜为人知的 AI 工具可以提供精彩的、独特的经历?这里有六个最好的。 1 Ditto Music Ditto 不是您可以用来创建独特歌曲的众多 AI 音乐生成器之一,而...人工智慧 發佈於2024-11-08
-
這 7 個跡象表明我們已經達到人工智慧的巔峰无论您在网上查找什么,都有网站、服务和应用程序宣称他们使用人工智能使其成为最佳选择。我不了解你的情况,但它的持续存在已经让人厌倦了。 因此,虽然人工智能肯定会留在我们的日常生活中,但有几个迹象表明我们已经达到了人工智能炒作的顶峰。 1 公众兴趣有限 虽然人工智能在科技圈受到了广泛关注,但重要的是要...人工智慧 發佈於2024-11-08















學習中文
- 1 走路用中文怎麼說? 走路中文發音,走路中文學習
- 2 坐飛機用中文怎麼說? 坐飞机中文發音,坐飞机中文學習
- 3 坐火車用中文怎麼說? 坐火车中文發音,坐火车中文學習
- 4 坐車用中文怎麼說? 坐车中文發音,坐车中文學習
- 5 開車用中文怎麼說? 开车中文發音,开车中文學習
- 6 游泳用中文怎麼說? 游泳中文發音,游泳中文學習
- 7 騎自行車用中文怎麼說? 骑自行车中文發音,骑自行车中文學習
- 8 你好用中文怎麼說? 你好中文發音,你好中文學習
- 9 謝謝用中文怎麼說? 谢谢中文發音,谢谢中文學習
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









