
Como converter PDFs em Markdown usando PyMuPDFM e sua avaliação
 Navegar:290
Navegar:290
PyMuPDF4LLM é uma biblioteca projetada para converter PDFs no formato Markdown. Aqui, compartilharei minha experiência testando esta biblioteca.
Instalação
Comece instalando a biblioteca usando o seguinte comando:
pip install pymupdf4llm
Uso
O uso básico é bastante simples, exigindo apenas três linhas de código para converter um PDF em Markdown:
import pymupdf4llm
md_text = pymupdf4llm.to_markdown("input.pdf")
print(md_text)
Você pode especificar argumentos para ajustar como o conteúdo é extraído.
Extraindo texto por página
Por padrão, todo o PDF é convertido em uma única saída de texto. No entanto, você pode extrair texto página por página especificando page_chunks=True.
md_text = pymupdf4llm.to_markdown("input.pdf", page_chunks=True)
Extraindo Imagens
Para extrair imagens como arquivos, use a opção write_images=True:
md_text = pymupdf4llm.to_markdown("input.pdf", write_images=True)
Também é possível incorporar imagens diretamente no Markdown usando codificação base64:
md_text = pymupdf4llm.to_markdown("input.pdf", embed_images=True)
Avaliação dos resultados da conversão
Para testes, vários PDFs com diferentes elementos Markdown foram usados.

Conversão de cabeçalho
Os cabeçalhos são convertidos corretamente no formato Markdown. Aqui está uma parte do resultado:
# Sample Markdown Guide This is a sample markdown file that includes various features for quick reference. ## 1. Headers ... ## 3. Lists
Texto em negrito e itálico
A formatação em negrito e itálico também é convertida corretamente:
**Bold: **Bold Text**** _Italic: *Italic Text*_ **_Bold and Italic: ***Bold and Italic***_**
Conversão de lista
As listas ordenadas no primeiro nível são convertidas sem problemas, mas as listas aninhadas e as listas não ordenadas não são convertidas com precisão.
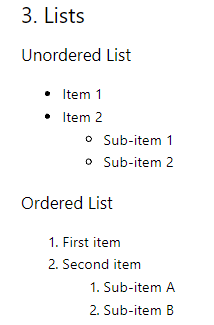
## 3. Lists ### Unordered List Item 1 Item 2 Sub-item 1 Sub-item 2 ### Ordered List 1. First item 2. Second item 1. Sub-item A 2. Sub-item B
Conversão de links
As URLs dos links são extraídas, mas toda a linha que contém o link se torna um hiperlink, desviando-se do formato original.
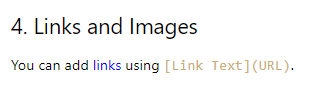
## 4. Links and Images [You can add links using [Link Text](URL).](https://www.example.com/)
Extração de imagem
As imagens não são extraídas por padrão, mas podem ser salvas localmente com write_images=True.
md_text = pymupdf4llm.to_markdown("input.pdf", write_images=True)
As imagens salvas são então referenciadas no Markdown da seguinte forma:
### Image Example

Conversão de tabela
Tabelas simples sem bordas verticais não são convertidas com precisão (provavelmente porque limites de colunas ambíguos fazem com que as tabelas sejam tratadas como texto simples).

## 5. Tables
**Column 1** **Column 2** **Column 3**
Row 1 Data A Data B
Row 2 Data C Data D
Conversão de código
Os blocos de código são convertidos corretamente, mas a especificação da linguagem (por exemplo, python) não é mantida. A conversão de código embutido também apresenta problemas.

## 6. Code
### Inline Code
Use backticks for inline code: print("Hello, world!")
### Code Block
Use triple backticks for code blocks:
```
def greet(name):
return f"Hello, {name}!"
print(greet("Markdown"))
```
Texto multilinha
Para texto com várias linhas, as quebras de linha são preservadas conforme aparecem no PDF original.

Markdown is a lightweight and versatile markup language favored by developers, writers, and bloggers alike
due to its simplicity in formatting text, enabling users to create readable and well-structured documents—
whether for documentation, blog posts, or articles—without the complexity of HTML, while also offering the
ability to convert content seamlessly into other formats like HTML, PDF, and even slideshows, making it an
ideal choice for projects that require both clarity and flexibility in presentation.
Conclusão
Apesar dos desafios na conversão precisa de listas e links, PyMuPDF4LLM é uma ferramenta útil para converter PDFs em Markdown. Pode funcionar localmente sem a necessidade de modelos de linguagem externos, tornando-o adequado para ambientes onde o acesso à Internet não está disponível.
-
 Como posso reorganizar colunas no MySQL para melhorar a visibilidade dos dados e a eficiência das consultas?Reorganizando colunas MySQL com eficiência para maior visibilidadeConsultar bancos de dados grandes pode ser complicado quando as colunas não estão or...Programação Publicado em 2024-11-08
Como posso reorganizar colunas no MySQL para melhorar a visibilidade dos dados e a eficiência das consultas?Reorganizando colunas MySQL com eficiência para maior visibilidadeConsultar bancos de dados grandes pode ser complicado quando as colunas não estão or...Programação Publicado em 2024-11-08 -
Como usar getElementsByClassName corretamente e alterar estilos de elementos com base em eventos?Alterando estilos de elemento usando getElementsByClassNamegetElementsByClassName permite selecionar vários elementos com o mesmo nome de classe. No e...Programação Publicado em 2024-11-08
-
Por que minha imagem em tela não desenha? A importância do carregamento assíncrono de imagens.Aguardando o carregamento da imagem antes de desenharAo tentar adicionar uma imagem a uma tela, é crucial garantir que a imagem seja carregada antes t...Programação Publicado em 2024-11-08
-
LeetCode em Golang: analisando uma expressão booleanaEste é um dos problemas do LeetCode que gostei de resolver. Resolvi em Golang e já sou um novato em Go, que comecei a aprender nele há apenas uma sema...Programação Publicado em 2024-11-08
-
maneiras de prevenir ataques XSS: um guia abrangente1. O que é XSS? XSS, ou Cross-Site Scripting, é um tipo de vulnerabilidade de segurança encontrada em aplicativos da web. Ele permite que inv...Programação Publicado em 2024-11-08
-
O novo Cache::flexible() do LaravelEsperar que um grande conjunto de dados seja computado toda vez que você atinge uma rota é uma droga! E os usuários não querem esperar, todo mundo tem...Programação Publicado em 2024-11-08
-
Aplicações Web em montagem!MOS 6502 foi um grande passo na computação acessível. Graças a esse amiguinho, fomos apresentados ao Commodore64, Apple II, Atari2600 e NES. Ainda hoj...Programação Publicado em 2024-11-08
-
Torne seu CSS melhor com mixins e funções SCSSSCSS é uma extensão de CSS que torna seu código mais fácil de gerenciar. Com SCSS, você pode usar mixins e funções para evitar escrever o mesmo código...Programação Publicado em 2024-11-08
-
## Erro Scopelint: Usando variável no escopo do intervalo - Como consultar com segurança variáveis de loop em literais de função?Erro Scopelint: usando variável no escopo do intervaloEm uma função de teste TestGetUID, o código encontra um erro relatado pelo scopelint, que avisa ...Programação Publicado em 2024-11-08
-
Implementando rolagem suave para uma melhor experiência do usuário.A rolagem suave é um recurso moderno de microanimação que aprimora a experiência do usuário, permitindo uma navegação fácil entre as seções de uma pág...Programação Publicado em 2024-11-08
-
## Por que Curl retorna \"18: transferência fechada com dados de leitura pendentes restantes\" ao usar CURLOPT_RETURNTRANSFER?Resolvendo o erro de transferência fechada com dados de leitura pendentesExecutar uma recuperação de dados com curl pode ocasionalmente gerar uma mens...Programação Publicado em 2024-11-08
-
Listas de programas pythoncriação de minha lista minhalista=["singam","cabra","rayyan","leo"] imprimir(minhalista) imprimir(minhalista[2...Programação Publicado em 2024-11-08
-
Host Virtual Apache: Adicionando proxy reversoO que é um proxy reverso? Um proxy reverso atua como um intermediário que encaminha solicitações de clientes para outros servidores. É freque...Programação Publicado em 2024-11-08
-
[Resolvido] Função de usuário Appwrite ausente ou erros de escopo ausentesAppwrite é uma ferramenta incrível para usar se você deseja construir aplicativos rapidamente, mas às vezes você pode encontrar erros que podem ser fr...Programação Publicado em 2024-11-08
-
Como corrigir o erro pd.io.parsers.ExcelFile.parse ao ler arquivos Excel em Python com PandasLendo um arquivo Excel em Python usando PandasBackgroundAo trabalhar com dados em Python, os arquivos Excel são uma fonte comum de informações. Pandas...Programação Publicado em 2024-11-08













![[Resolvido] Função de usuário Appwrite ausente ou erros de escopo ausentes](http://www.luping.net/uploads/20241014/1728906493670d04fd3f118.jpg)

Estude chinês
- 1 Como se diz “andar” em chinês? 走路 Pronúncia chinesa, 走路 aprendizagem chinesa
- 2 Como se diz “pegar um avião” em chinês? 坐飞机 Pronúncia chinesa, 坐飞机 aprendizagem chinesa
- 3 Como se diz “pegar um trem” em chinês? 坐火车 Pronúncia chinesa, 坐火车 aprendizagem chinesa
- 4 Como se diz “pegar um ônibus” em chinês? 坐车 Pronúncia chinesa, 坐车 aprendizagem chinesa
- 5 Como se diz dirigir em chinês? 开车 Pronúncia chinesa, 开车 aprendizagem chinesa
- 6 Como se diz nadar em chinês? 游泳 Pronúncia chinesa, 游泳 aprendizagem chinesa
- 7 Como se diz andar de bicicleta em chinês? 骑自行车 Pronúncia chinesa, 骑自行车 aprendizagem chinesa
- 8 Como você diz olá em chinês? 你好Pronúncia chinesa, 你好Aprendizagem chinesa
- 9 Como você agradece em chinês? 谢谢Pronúncia chinesa, 谢谢Aprendizagem chinesa
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









