
機械学習分類モデルの評価
 ブラウズ:623
ブラウズ:623
概要
- モデル評価の目的は何ですか?
- モデル評価の目的とそのいくつか 一般的な評価手順?
- 分類精度の用途とその精度は何ですか 制限?
- 混同行列はパフォーマンスをどのように説明しますか 分類子?
- 混同行列から計算できる指標は何ですか?
Tモデル評価の目標は、質問に答えることです。
さまざまなモデルを選択するにはどうすればよいですか?
機械学習を評価するプロセスは、モデルがそのアプリケーションに対してどの程度信頼性があり効果的であるかを判断するのに役立ちます。これには、パフォーマンス、指標、予測や意思決定の精度などのさまざまな要素を評価することが含まれます。
どのモデルを使用する場合でも、さまざまなモデル タイプ、チューニング パラメーター、機能など、モデル間で選択する方法が必要です。また、モデルが目に見えないデータに対してどの程度一般化されるかを推定するには、モデル評価手順も必要です。最後に、モデルのパフォーマンスを定量化するために、他の手順と組み合わせる評価手順が必要です。
先に進む前に、さまざまなモデルの評価手順とその動作方法をいくつか確認してみましょう。
モデルの評価手順とその運用方法。
-
同じデータでのトレーニングとテスト
- トレーニング データを「過剰適合」し、必ずしも一般化できない、過度に複雑なモデルに報酬を与えます
-
トレーニング/テストの分割
- データセットを 2 つの部分に分割し、異なるデータでモデルをトレーニングおよびテストできるようにします
- サンプル外のパフォーマンスの推定値は改善されましたが、依然として「ばらつきが大きい」推定値です
- スピード、シンプルさ、柔軟性のおかげで便利
-
K 分割相互検証
- 体系的に「K」個のトレーニング/テスト分割を作成し、結果をまとめて平均します
- サンプル外のパフォーマンスのさらに正確な推定
- トレーニング/テストの分割よりも「K」倍遅く実行されます。
上記のことから、次のことが推測できます:
同じデータに対するトレーニングとテストは、新しいデータに一般化されず、実際には役に立たない過度に複雑なモデルを構築する過学習の典型的な原因です。
Train_Test_Split は、サンプル外のパフォーマンスをより正確に推定します。
K 分割相互検証は、体系的に K トレーニング テストを分割し、結果をまとめて平均することでより効果的に実行されます。
要約すると、train_tests_split はその速度とシンプルさのおかげで相互検証に依然として有益であり、それをこのチュートリアル ガイドで使用します。
モデルの評価指標:
選択した手順に沿って評価指標が常に必要になります。指標の選択は、対処している問題によって異なります。分類問題の場合は、分類精度を使用できます。ただし、このガイドでは他の重要な分類評価指標に焦点を当てます。
新しい評価指標を学ぶ前に、分類精度を確認し、その長所と短所について話しましょう。
分類精度
このチュートリアルでは、768 人の患者の健康データと糖尿病の状態が含まれるピマ インディアン糖尿病データセットを選択しました。
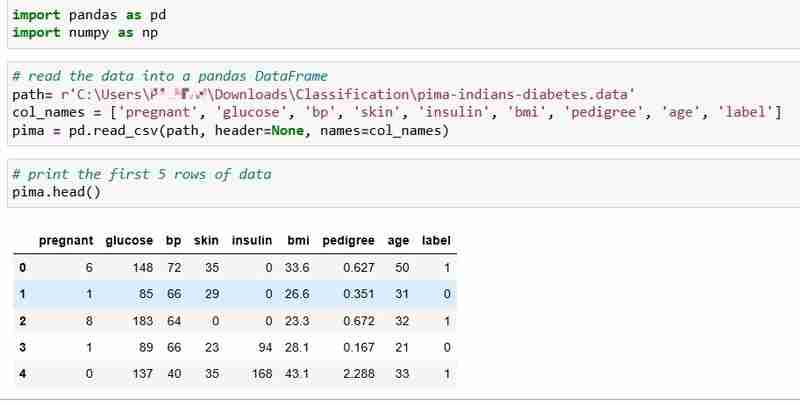
データを読み取り、データの最初の 5 行を出力しましょう。ラベル列は、患者が糖尿病を患っている場合は 1、糖尿病を患っていない場合は 0 を示し、次の質問に答えるつもりです。
質問: 健康測定結果から患者の糖尿病の状態を予測できますか?
特徴メトリック X と応答ベクトル Y を定義します。train_test_split を使用して、X と Y をトレーニング セットとテスト セットに分割します。
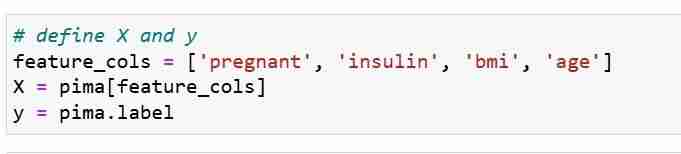
次に、トレーニング セットでロジスティック回帰モデルをトレーニングします。その後の当てはめステップ中に、logreg モデル オブジェクトは X_train と Y_train の間の関係を学習します。最後に、テスト セットのクラス予測を行います。

これで、テスト セットの予測が完了しました。分類精度を計算できます。これは、単純に正しい予測の割合です。
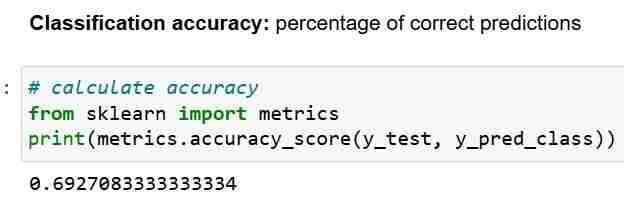
ただし、分類精度を評価指標として使用する場合は常に、それを ヌル精度 と比較することが重要です。これは、最も頻度の高いクラスを常に予測することで達成できる精度です。

ヌル精度が質問に答えます。私のモデルが支配的なクラスを 100% の確率で予測するとしたら、それはどれくらいの頻度で正しいでしょうか?上記のシナリオでは、y_test の 32% は 1 です。言い換えれば、患者が糖尿病であると予測する愚かなモデルは、68%の確率で正しくなります (これはゼロです)。これは、ロジスティック回帰を測定する際のベースラインとなります。モデル。
ヌル精度 68% とモデル精度 69% を比較すると、モデルはあまり良くないようです。これは、モデル評価指標としての分類精度の 1 つの弱点を示しています。分類精度からは、テストの基礎となる分布については何もわかりません。
要約すれば:
- 分類精度は、最も理解しやすい分類指標です
- しかし、応答値の基礎となる分布はわかりません
- そして、分類子がどのような エラーの「タイプ」 を起こしているかはわかりません。
混同行列を見てみましょう。
混同行列
混同行列は、分類モデルのパフォーマンスを説明する表です。
これは分類器のパフォーマンスを理解するのに役立ちますが、モデルの評価指標ではありません。したがって、scikit learn に最適な混同行列を持つモデルを選択するように指示することはできません。ただし、混同行列から計算できるメトリックは多数あり、それらを直接使用してモデルを選択できます。
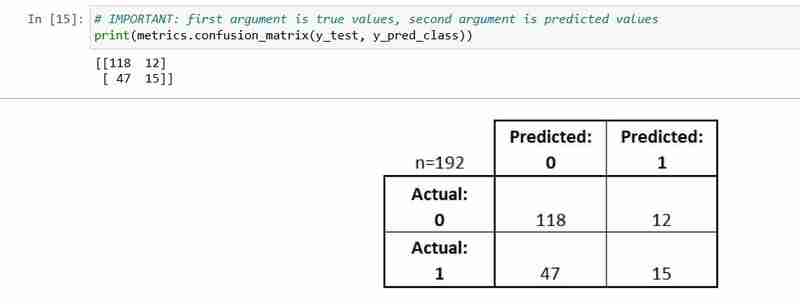
- テストセット内のすべての観測値は、正確に 1 つのボックス内で表されます
- 2 つの応答クラスがあるため、これは 2x2 行列です
- ここに示されている形式は汎用ではありません
基本的な用語をいくつか説明しましょう。
- 真陽性者 (TP): 私たちは正しく、彼らが糖尿病を持っていると予測しました
- 真陰性者 (TN): 私たちは正しく、彼らは糖尿病にかかっていないと予測しました
- 偽陽性 (FP): 私たちは、彼らが糖尿病であると 実際 予測しました(「タイプ I エラー」) 偽陰性 (FN):
- 私たちは、彼らが糖尿病にかかっていないと誤って予測しました(「タイプIIエラー」) 指標を計算する方法を見てみましょう
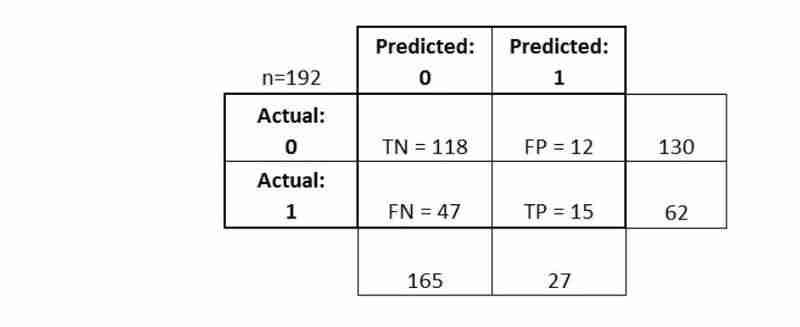


混同行列により、分類器のパフォーマンスの
- より完全な全体像
- が得られます さまざまな 分類メトリクス
- を計算することもでき、これらのメトリクスはモデルの選択に役立ちます
-
 Encore.ts — ElysiaJS や Hono よりも高速数か月前、私たちは TypeScript 用のオープンソース バックエンド フレームワークである Encore.ts をリリースしました。 すでに多くのフレームワークが存在するため、私たちが行った珍しい設計上の決定のいくつかと、それがどのようにして驚くべきパフォーマンス数値につながるのかを共有したい...プログラミング 2024 年 11 月 5 日に公開
Encore.ts — ElysiaJS や Hono よりも高速数か月前、私たちは TypeScript 用のオープンソース バックエンド フレームワークである Encore.ts をリリースしました。 すでに多くのフレームワークが存在するため、私たちが行った珍しい設計上の決定のいくつかと、それがどのようにして驚くべきパフォーマンス数値につながるのかを共有したい...プログラミング 2024 年 11 月 5 日に公開 -
+ を使用した文字列連結が文字列リテラルで失敗するのはなぜですか?文字列リテラルと文字列の連結C では、演算子を使用して文字列と文字列リテラルを連結できます。ただし、この機能には混乱を招く可能性のある制限があります。質問の中で、作成者は文字列リテラル「Hello」、「,world」、および「!」を連結しようとしています。 2つの異なる方法で。最初の例:const ...プログラミング 2024 年 11 月 5 日に公開
-
React の再レンダリング: 最適なパフォーマンスのためのベスト プラクティスReact の効率的なレンダリング メカニズムは、その人気の主な理由の 1 つです。ただし、アプリケーションが複雑になるにつれて、コンポーネントの再レンダリングの管理がパフォーマンスを最適化するために重要になります。 React のレンダリング動作を最適化し、不必要な再レンダリングを回避するためのベ...プログラミング 2024 年 11 月 5 日に公開
-
条件付き列の作成を実現する方法: Pandas DataFrame で If-Elif-Else を探索する?条件付き列の作成: Pandas の If-Elif-Else指定された問題では、新しい列を DataFrame に追加することが求められます一連の条件付き基準に基づいて決定されます。課題は、コードの効率性と可読性を維持しながらこれらの条件を実装することにあります。関数アプリケーションを使用したソリ...プログラミング 2024 年 11 月 5 日に公開
-
秋さんのご紹介です!Qiu のリリースを発表できることを嬉しく思います。これは、生の SQL を再び楽しくするために設計された、実用的な SQL クエリ ランナーです。正直に言うと、ORM にはその役割がありますが、単純な SQL を書きたいだけの場合は、少し圧倒されてしまう可能性があります。私は生の SQL クエリ...プログラミング 2024 年 11 月 5 日に公開
-
CSS でコンテナの幅に基づいてマージントップのパーセンテージが計算されるのはなぜですか?CSS でのマージントップ パーセンテージの計算要素にマージントップ パーセンテージを適用する場合、その計算方法を理解することが重要です。実行されました。一般的な考えに反して、マージントップのパーセンテージは、ブロックを含むブロックの高さではなく、幅に基づいて決定されます。W3C 仕様の説明: W3...プログラミング 2024 年 11 月 5 日に公開
-
CSS 移行中の Webkit テキストのレンダリングの不一致を解決するにはどうすればよいですか?CSS 遷移中の Webkit テキスト レンダリングの不一致を解決するCSS 遷移中、特に要素をスケーリングするときに、Webkit 内でテキスト レンダリングの不一致が発生する可能性があります。ブラウザ。この問題は、ブラウザがレンダリング パフォーマンスを最適化しようとすることが原因で発生します...プログラミング 2024 年 11 月 5 日に公開
-
Reactables で簡素化された RxJS導入 RxJS は強力なライブラリですが、学習曲線が急であることが知られています。 ライブラリの大規模な API サーフェスは、リアクティブ プログラミングへのパラダイム シフトと相まって、初心者にとっては圧倒される可能性があります。 RxJS の使用法を簡素化し、開発者がリアクテ...プログラミング 2024 年 11 月 5 日に公開
-
Pandas の複数の列にわたる最大値を見つける方法?Pandas の複数の列にわたる最大値の検索Pandas DataFrame の複数の列にわたる最大値を決定するには、さまざまなアプローチを使用できます。 。これを実現する方法は次のとおりです。指定された列で max() 関数を使用するこの方法では、目的の列を明示的に選択し、max() 関数を適用し...プログラミング 2024 年 11 月 5 日に公開
-
CI/CD 入門: 最初のパイプラインを自動化するための初心者ガイド (Jenkins を使用)目次 導入 CI/CD とは何ですか? 継続的インテグレーション (CI) 継続的デリバリー (CD) 継続的展開 CI/CDの利点 市場投入までの時間の短縮 コード品質の向上 効率的なコラボレーション 自動化と一貫性の向上 最初の CI/CD パイプラインを作成する方法 ステップ...プログラミング 2024 年 11 月 5 日に公開
-
TypeScript が大規模プロジェクトにおける JavaScript の信頼性を高める方法。導入 JavaScript は Web 開発で広く使用されており、現在ではさまざまな業界の大規模プロジェクトに適用されています。ただし、これらのプロジェクトが成長するにつれて、JavaScript コードの管理が難しくなります。データ型の不一致、実行時の予期しないエラー、不明確なコ...プログラミング 2024 年 11 月 5 日に公開
-
PHPのpassword_verify関数を使用してユーザーのパスワードを安全に検証するにはどうすればよいですか?PHP を使用した暗号化されたパスワードの復号化多くのアプリケーションは、password_hash などの暗号化アルゴリズムを使用してユーザー パスワードを安全に保存します。ただし、ログイン試行を検証するときは、入力されたパスワードを暗号化されて保存されたバージョンと比較することが重要です。暗号化...プログラミング 2024 年 11 月 5 日に公開
-
Vue の学習パート 天気アプリの構築Vue.js に飛び込むのは、直感的で柔軟性があり、驚くほど強力な、DIY キットの新しいお気に入りツールを発見するようなものです。 Vue を実際に使ってみた最初のサイド プロジェクトは天気予報アプリでした。このアプリは、フレームワークの機能や Web 開発全般について多くのことを教えてくれました...プログラミング 2024 年 11 月 5 日に公開
-
NFTプレビューカードコンポーネント?私の最新プロジェクト、HTML と CSS を使用した「NFT プレビュー カード コンポーネント」が完成しました。 ? GitHub でコードを確認して探索してください。フィードバックは大歓迎です! ? GitHub: [https://github.com/khanimran17/NFT-pr...プログラミング 2024 年 11 月 5 日に公開
-
Android アプリケーションはどのようにして Microsoft SQL Server 2008 に接続できますか?Android アプリケーションの Microsoft SQL Server 2008 への接続Android アプリケーションは、Microsoft SQL Server 2008 などの中央データベース サーバーにシームレスに接続できます。開発者は、モバイル アプリケーションからリモート サーバ...プログラミング 2024 年 11 月 5 日に公開















中国語を勉強する
- 1 「歩く」は中国語で何と言いますか? 走路 中国語の発音、走路 中国語学習
- 2 「飛行機に乗る」は中国語で何と言いますか? 坐飞机 中国語の発音、坐飞机 中国語学習
- 3 「電車に乗る」は中国語で何と言いますか? 坐火车 中国語の発音、坐火车 中国語学習
- 4 「バスに乗る」は中国語で何と言いますか? 坐车 中国語の発音、坐车 中国語学習
- 5 中国語でドライブは何と言うでしょう? 开车 中国語の発音、开车 中国語学習
- 6 水泳は中国語で何と言うでしょう? 游泳 中国語の発音、游泳 中国語学習
- 7 中国語で自転車に乗るってなんて言うの? 骑自行车 中国語の発音、骑自行车 中国語学習
- 8 中国語で挨拶はなんて言うの? 你好中国語の発音、你好中国語学習
- 9 中国語でありがとうってなんて言うの? 谢谢中国語の発音、谢谢中国語学習
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









