 Page de garde > La programmation > J'ai créé une application de vérification du nombre de jetons en utilisant Streamlit dans Snowflake (SiS)
Page de garde > La programmation > J'ai créé une application de vérification du nombre de jetons en utilisant Streamlit dans Snowflake (SiS)
J'ai créé une application de vérification du nombre de jetons en utilisant Streamlit dans Snowflake (SiS)
 Parcourir:864
Parcourir:864
Introduction
Bonjour, je suis ingénieur commercial chez Snowflake. J'aimerais partager certaines de mes expériences et expériences avec vous à travers divers articles. Dans cet article, je vais vous montrer comment créer une application à l'aide de Streamlit dans Snowflake pour vérifier le nombre de jetons et estimer les coûts pour Cortex LLM.
Remarque : cet article représente mes opinions personnelles et non celles de Snowflake.
Qu’est-ce que Streamlit dans Snowflake (SiS) ?
Streamlit est une bibliothèque Python qui vous permet de créer des interfaces utilisateur Web avec du code Python simple, éliminant ainsi le besoin de HTML/CSS/JavaScript. Vous pouvez voir des exemples dans la galerie d'applications.
Streamlit dans Snowflake vous permet de développer et d'exécuter des applications Web Streamlit directement sur Snowflake. Il est facile à utiliser avec un simple compte Snowflake et idéal pour intégrer les données des tables Snowflake dans les applications Web.
À propos de Streamlit dans Snowflake (documentation officielle de Snowflake)
Qu’est-ce que le cortex de flocon de neige ?
Snowflake Cortex est une suite de fonctionnalités d'IA générative dans Snowflake. Cortex LLM vous permet d'appeler de grands modèles de langage exécutés sur Snowflake à l'aide de fonctions simples en SQL ou Python.
Fonctions du grand modèle de langage (LLM) (Snowflake Cortex) (documentation officielle de Snowflake)
Présentation des fonctionnalités
Image
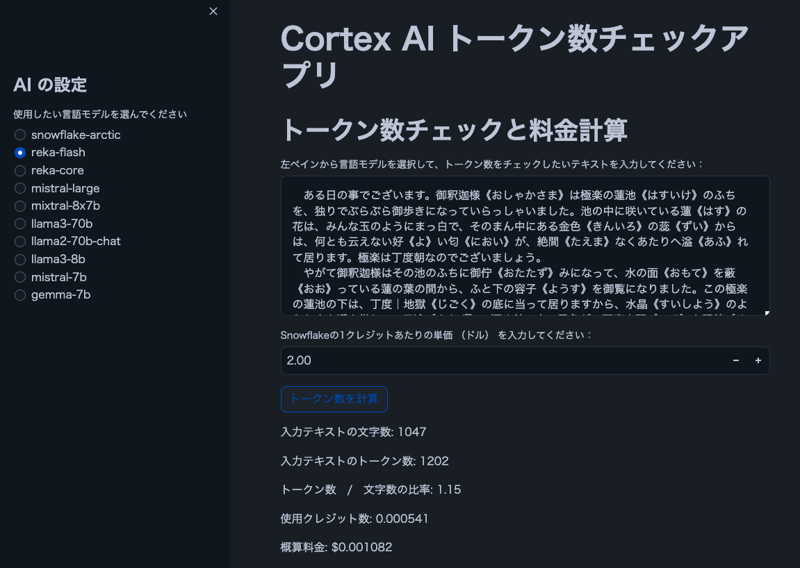
Remarque : le texte dans l'image est tiré de "The Spider's Thread" de Ryunosuke Akutagawa.
Caractéristiques
- Les utilisateurs peuvent sélectionner un modèle Cortex LLM
- Afficher le nombre de caractères et de jetons pour le texte saisi par l'utilisateur
- Afficher le rapport jetons/caractères
- Calculer le coût estimé en fonction du prix du crédit Snowflake
Remarque : Tableau des tarifs Cortex LLM (PDF)
Conditions préalables
- Compte Snowflake avec accès Cortex LLM
- snowflake-ml-python 1.1.2 ou version ultérieure
Remarque : disponibilité de la région Cortex LLM (documentation officielle de Snowflake)
Code source
import streamlit as st
from snowflake.snowpark.context import get_active_session
import snowflake.snowpark.functions as F
# Get current session
session = get_active_session()
# Application title
st.title("Cortex AI Token Count Checker")
# AI settings
st.sidebar.title("AI Settings")
lang_model = st.sidebar.radio("Select the language model you want to use",
("snowflake-arctic", "reka-core", "reka-flash",
"mistral-large2", "mistral-large", "mixtral-8x7b", "mistral-7b",
"llama3.1-405b", "llama3.1-70b", "llama3.1-8b",
"llama3-70b", "llama3-8b", "llama2-70b-chat",
"jamba-instruct", "gemma-7b")
)
# Function to count tokens (using Cortex's token counting function)
def count_tokens(model, text):
result = session.sql(f"SELECT SNOWFLAKE.CORTEX.COUNT_TOKENS('{model}', '{text}') as token_count").collect()
return result[0]['TOKEN_COUNT']
# Token count check and cost calculation
st.header("Token Count Check and Cost Calculation")
input_text = st.text_area("Select a language model from the left pane and enter the text you want to check for token count:", height=200)
# Let user input the price per credit
credit_price = st.number_input("Enter the price per Snowflake credit (in dollars):", min_value=0.0, value=2.0, step=0.01)
# Credits per 1M tokens for each model (as of 2024/8/30, mistral-large2 is not supported)
model_credits = {
"snowflake-arctic": 0.84,
"reka-core": 5.5,
"reka-flash": 0.45,
"mistral-large2": 1.95,
"mistral-large": 5.1,
"mixtral-8x7b": 0.22,
"mistral-7b": 0.12,
"llama3.1-405b": 3,
"llama3.1-70b": 1.21,
"llama3.1-8b": 0.19,
"llama3-70b": 1.21,
"llama3-8b": 0.19,
"llama2-70b-chat": 0.45,
"jamba-instruct": 0.83,
"gemma-7b": 0.12
}
if st.button("Calculate Token Count"):
if input_text:
# Calculate character count
char_count = len(input_text)
st.write(f"Character count of input text: {char_count}")
if lang_model in model_credits:
# Calculate token count
token_count = count_tokens(lang_model, input_text)
st.write(f"Token count of input text: {token_count}")
# Ratio of tokens to characters
ratio = token_count / char_count if char_count > 0 else 0
st.write(f"Token count / Character count ratio: {ratio:.2f}")
# Cost calculation
credits_used = (token_count / 1000000) * model_credits[lang_model]
cost = credits_used * credit_price
st.write(f"Credits used: {credits_used:.6f}")
st.write(f"Estimated cost: ${cost:.6f}")
else:
st.warning("The selected model is not supported by Snowflake's token counting feature.")
else:
st.warning("Please enter some text.")
Conclusion
Cette application facilite l'estimation des coûts des charges de travail LLM, en particulier lorsqu'il s'agit de langues comme le japonais, où il existe souvent un écart entre le nombre de caractères et le nombre de jetons. J'espère que cela vous sera utile !
Annonces
Snowflake Quoi de neuf Mises à jour sur X
Je partage les nouveautés de Snowflake sur X. N'hésitez pas à suivre si vous êtes intéressé !
Version anglaise
Snowflake Quoi de neuf Bot (version anglaise)
https://x.com/snow_new_en
Version japonaise
Snowflake Quoi de neuf Bot (version japonaise)
https://x.com/snow_new_jp
Historique des modifications
(20240914) Message initial
Article japonais original
https://zenn.dev/tsubasa_tech/articles/4dd80c91508ec4
-
 Comment limiter la plage de défilement d'un élément dans un élément parent de taille dynamique?Implémentation de limites de hauteur CSS pour les éléments de défilement vertical dans une interface interactive, le contrôle du comportement ...La programmation Publié le 2025-07-04
Comment limiter la plage de défilement d'un élément dans un élément parent de taille dynamique?Implémentation de limites de hauteur CSS pour les éléments de défilement vertical dans une interface interactive, le contrôle du comportement ...La programmation Publié le 2025-07-04 -
Pourquoi Microsoft Visual C ++ ne parvient pas à implémenter correctement l'instanciation du modèle biphasé?Le mystère de l'instanciation du modèle deux phases "Broken" dans Microsoft Visual C Instruction Problème: Les utilisateurs ex...La programmation Publié le 2025-07-04
-
Guide de création de pages Fastapi Custom 404 PagePage personnalisée 404 non trouvé avec fastapi Pour créer une page 404 personnalisée, Fastapi propose plusieurs approches. La méthode appropri...La programmation Publié le 2025-07-04
-
PHP Future: adaptation et innovationL'avenir de PHP sera réalisé en s'adaptant aux nouvelles tendances technologiques et en introduisant des fonctionnalités innovantes: 1) s'...La programmation Publié le 2025-07-04
-
Résoudre l'erreur \\ "Erreur de valeur de chaîne \\" Exception lorsque MySQL inserte emojiRésolution de la valeur de chaîne incorrecte Exception lors de l'insertion d'Emoji Lorsque vous essayez d'insérer une chaîne contena...La programmation Publié le 2025-07-04
-
L'erreur du compilateur "USR / bin / ld: ne peut pas trouver -l" solutionErreur rencontrée: "usr / bin / ld: impossible de trouver -l " lorsque -l usr/bin/ld: cannot find -l<nameOfTheLibrary> Ajo...La programmation Publié le 2025-07-04
-
Analyse du langage fortement tapé CSSL'une des façons de classer un langage de programmation est de la force ou de la manière faible. Ici, «tapé» signifie si les variables sont connu...La programmation Publié le 2025-07-04
-
Comment transmettre des pointeurs exclusifs en fonction ou paramètres du constructeur en C ++?Gérer les pointeurs uniques en tant que paramètres dans les constructeurs et les fonctions des pointeurs uniques ( UNIQUE_PTR ) Remollissez le p...La programmation Publié le 2025-07-04
-
Le faux réveil se produira-t-il vraiment en Java?des réveils parasites en java: réalité ou mythe? Le concept de faux réveils dans la synchronisation de Java a fait l'objet de discussion dep...La programmation Publié le 2025-07-04
-
Raisons de CodeIgniter à se connecter à la base de données MySQL après le passage à MySQLIImpossible de se connecter à la base de données MySQL: dépannage du message d'erreur Lorsque vous tentez de passer du pilote MySQL vers le...La programmation Publié le 2025-07-04
-
Pourquoi y a-t-il des rayures dans mon fond de dégradé linéaire, et comment puis-je les réparer?bannissant les bandes d'arrière-plan à partir du gradient linéaire Lorsque vous utilisez la propriété linéaire-gradient pour un arrière-pl...La programmation Publié le 2025-07-04
-
Comment empêcher les soumissions en double après la rafraîchissement du formulaire?Empêcher les soumissions en double avec une manipulation de rafraîchissement dans le développement Web, il est courant d'informer le probl...La programmation Publié le 2025-07-04
-
Recherchez la méthode de l'élément de script qui exécute actuellement JavaScriptComment faire référence à l'élément de script qui a chargé le script en cours d'exécution comprendre le problème Dans certains scénari...La programmation Publié le 2025-07-04
-
Causes et solutions pour la défaillance de la détection du visage: erreur -215Gestion des erreurs: résolution "Erreur: (-215)! Vide () Dans la fonction détectMultiSCALE" dans OpenCv lorsque vous pouvez utiliser...La programmation Publié le 2025-07-04
-
Comment convertir une colonne Pandas DataFrame au format DateTime et filtrer par date?Transformer la colonne Pandas DataFrame au format DateTime Scénario: Données dans un Pandas DataFrame existait souvent sous divers formats, ...La programmation Publié le 2025-07-04















Étudier le chinois
- 1 Comment dit-on « marcher » en chinois ? 走路 Prononciation chinoise, 走路 Apprentissage du chinois
- 2 Comment dit-on « prendre l’avion » en chinois ? 坐飞机 Prononciation chinoise, 坐飞机 Apprentissage du chinois
- 3 Comment dit-on « prendre un train » en chinois ? 坐火车 Prononciation chinoise, 坐火车 Apprentissage du chinois
- 4 Comment dit-on « prendre un bus » en chinois ? 坐车 Prononciation chinoise, 坐车 Apprentissage du chinois
- 5 Comment dire conduire en chinois? 开车 Prononciation chinoise, 开车 Apprentissage du chinois
- 6 Comment dit-on nager en chinois ? 游泳 Prononciation chinoise, 游泳 Apprentissage du chinois
- 7 Comment dit-on faire du vélo en chinois ? 骑自行车 Prononciation chinoise, 骑自行车 Apprentissage du chinois
- 8 Comment dit-on bonjour en chinois ? 你好Prononciation chinoise, 你好Apprentissage du chinois
- 9 Comment dit-on merci en chinois ? 谢谢Prononciation chinoise, 谢谢Apprentissage du chinois
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









