 Page de garde > La programmation > Comment convertir des PDF en Markdown à l'aide de PyMuPDFM et de son évaluation
Page de garde > La programmation > Comment convertir des PDF en Markdown à l'aide de PyMuPDFM et de son évaluation
Comment convertir des PDF en Markdown à l'aide de PyMuPDFM et de son évaluation
 Parcourir:809
Parcourir:809
PyMuPDF4LLM est une bibliothèque conçue pour convertir des PDF au format Markdown. Ici, je vais partager mon expérience en testant cette bibliothèque.
Installation
Commencez par installer la bibliothèque à l'aide de la commande suivante :
pip install pymupdf4llm
Usage
L'utilisation de base est assez simple, ne nécessitant que trois lignes de code pour convertir un PDF en Markdown :
import pymupdf4llm
md_text = pymupdf4llm.to_markdown("input.pdf")
print(md_text)
Vous pouvez spécifier des arguments pour ajuster la façon dont le contenu est extrait.
Extraire du texte par page
Par défaut, l'intégralité du PDF est convertie en une seule sortie texte. Cependant, vous pouvez extraire le texte page par page en spécifiant page_chunks=True.
md_text = pymupdf4llm.to_markdown("input.pdf", page_chunks=True)
Extraction d'images
Pour extraire des images sous forme de fichiers, utilisez l'option write_images=True :
md_text = pymupdf4llm.to_markdown("input.pdf", write_images=True)
Il est également possible d'intégrer des images directement dans le Markdown en utilisant l'encodage base64 :
md_text = pymupdf4llm.to_markdown("input.pdf", embed_images=True)
Évaluation des résultats de conversion
Pour les tests, divers PDF avec différents éléments Markdown ont été utilisés.

Conversion d'en-tête
Les en-têtes sont correctement convertis au format Markdown. Voici une partie du résultat :
# Sample Markdown Guide This is a sample markdown file that includes various features for quick reference. ## 1. Headers ... ## 3. Lists
Texte en gras et italique
Le format gras et italique est également correctement converti :
**Bold: **Bold Text**** _Italic: *Italic Text*_ **_Bold and Italic: ***Bold and Italic***_**
Conversion de liste
Les listes ordonnées du premier niveau sont converties sans problème, mais les listes imbriquées et les listes non ordonnées ne sont pas converties avec précision.
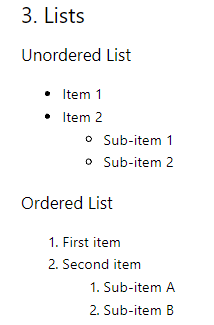
## 3. Lists ### Unordered List Item 1 Item 2 Sub-item 1 Sub-item 2 ### Ordered List 1. First item 2. Second item 1. Sub-item A 2. Sub-item B
Conversion de lien
Les URL des liens sont extraites, mais la ligne entière contenant le lien devient un lien hypertexte, s'écartant du format d'origine.
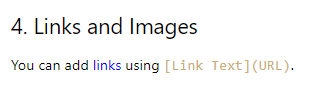
## 4. Links and Images [You can add links using [Link Text](URL).](https://www.example.com/)
Extraction d'images
Les images ne sont pas extraites par défaut mais peuvent être enregistrées localement avec write_images=True.
md_text = pymupdf4llm.to_markdown("input.pdf", write_images=True)
Les images enregistrées sont ensuite référencées dans le Markdown comme suit :
### Image Example

Conversion de table
Les tableaux simples sans bordures verticales ne sont pas convertis avec précision (probablement parce que les limites de colonnes ambiguës entraînent le traitement des tableaux comme du texte brut).

## 5. Tables
**Column 1** **Column 2** **Column 3**
Row 1 Data A Data B
Row 2 Data C Data D
Conversion de codes
Les blocs de code sont correctement convertis, mais la spécification du langage (par exemple, python) n'est pas conservée. La conversion de code en ligne présente également des problèmes.

## 6. Code
### Inline Code
Use backticks for inline code: print("Hello, world!")
### Code Block
Use triple backticks for code blocks:
```
def greet(name):
return f"Hello, {name}!"
print(greet("Markdown"))
```
Texte multiligne
Pour le texte multiligne, les sauts de ligne sont conservés tels qu'ils apparaissent dans le PDF d'origine.

Markdown is a lightweight and versatile markup language favored by developers, writers, and bloggers alike
due to its simplicity in formatting text, enabling users to create readable and well-structured documents—
whether for documentation, blog posts, or articles—without the complexity of HTML, while also offering the
ability to convert content seamlessly into other formats like HTML, PDF, and even slideshows, making it an
ideal choice for projects that require both clarity and flexibility in presentation.
Conclusion
Malgré les difficultés liées à la conversion précise des listes et des liens, PyMuPDF4LLM est un outil utile pour convertir des PDF en Markdown. Il peut fonctionner localement sans avoir besoin de modèles de langage externes, ce qui le rend adapté aux environnements où l'accès à Internet n'est pas disponible.
-
 \ "tandis que (1) vs pour (;;): L'optimisation du compilateur élimine-t-elle les différences de performances? \"while (1) vs pour (;;): y a-t-il une différence de vitesse? Question: LOOPS? Réponse: Dans la plupart des compilateurs modernes, il ...La programmation Publié le 2025-04-09
\ "tandis que (1) vs pour (;;): L'optimisation du compilateur élimine-t-elle les différences de performances? \"while (1) vs pour (;;): y a-t-il une différence de vitesse? Question: LOOPS? Réponse: Dans la plupart des compilateurs modernes, il ...La programmation Publié le 2025-04-09 -
Pourquoi Microsoft Visual C ++ ne parvient pas à implémenter correctement l'instanciation du modèle biphasé?Le mystère de l'instanciation du modèle deux phases "Broken" dans Microsoft Visual C Instruction Problème: Les utilisateurs ex...La programmation Publié le 2025-04-09
-
Comment réparer « Erreur générale : le serveur MySQL 2006 a disparu » lors de l'insertion de données ?Comment résoudre « Erreur générale : le serveur MySQL 2006 a disparu » lors de l'insertion d'enregistrementsIntroduction :L'insertion de d...La programmation Publié le 2025-04-09
-
Comment télécharger des fichiers avec des paramètres supplémentaires à l'aide de java.net.urlconnection et de codage multipart / formulaire de formulaire?Téléchargement des fichiers avec les demandes http pour télécharger des fichiers sur un serveur http tout en soumettant des paramètres supplém...La programmation Publié le 2025-04-09
-
Comment puis-je styliser la première instance d'un type d'élément spécifique sur un document HTML entier?correspondant au premier élément d'un certain type dans tout le document Styling Le premier élément d'un type spécifique à travers un...La programmation Publié le 2025-04-09
-
Pourquoi les comparaisons booléennes «Flake8» sont-elles dans les clauses de filtre Sqlalchemy?flake8 Flagging Boolean Comparison in Filter ClauseWhen attempting to filter query results based on a boolean comparison in SQL, developers may encoun...La programmation Publié le 2025-04-09
-
Comment puis-je créer efficacement des dictionnaires en utilisant la compréhension Python?Python Dictionary Comprehension Dans Python, les compréhensions du dictionnaire offrent un moyen concis de générer de nouveaux dictionnaires. Bi...La programmation Publié le 2025-04-09
-
Pourquoi les images affichent-elles des images à l'aide de la propriété CSS «Content»?Affichage des images avec URL de contenu dans Firefox Un problème a été rencontré lorsque certains navigateurs, spécifiquement Firefox, n'...La programmation Publié le 2025-04-09
-
Comment puis-je configurer Pytesseract pour une reconnaissance à un chiffre avec une sortie numéro uniquement?Pytesseract OCR avec une reconnaissance à un chiffre unique et des contraintes de numéro uniquement dans le contexte de Pytesseract, la config...La programmation Publié le 2025-04-09
-
Comment convertir efficacement les fuseaux horaires en PHP?Conversion efficace du fuseau horaire en php Dans PHP, la gestion des fuseaux horaires peut être une tâche simple. Ce guide fournira une méthode...La programmation Publié le 2025-04-09
-
Comment résoudre \ "Refusé de charger le script ... \" Erreurs dues à la stratégie de sécurité du contenu d'Android?dévoiler le mystère: contenu des erreurs de directive de stratégie de sécurité rencontrant l'erreur énigmatique "refusé de charger le...La programmation Publié le 2025-04-09
-
Comment puis-je générer efficacement des limaces adaptées à l'URL des chaînes Unicode en PHP?Créant une fonction pour la génération efficace des limaces Création de limaces, des représentations simplifiées des chaînes Unicode utilisées...La programmation Publié le 2025-04-09
-
Comment puis-je maintenir le rendu de cellules JTable personnalisé après l'édition de cellules?En maintenant le rendu de cellules JTable après la modification de cellule dans un JTable, implémentant les capacités de rendu et d'éditio...La programmation Publié le 2025-04-09
-
Y a-t-il une différence de performance entre l'utilisation d'une boucle for-out et un itérateur pour la traversée de collecte en Java?pour chaque boucle vs iterator: efficacité dans la collection Traversal introduction Lorsque vous traversez une collection dans Java, le c...La programmation Publié le 2025-04-09
-
Pourquoi l'exécution de JavaScript cesse-t-elle lors de l'utilisation du bouton Firefox Retour?Problème d'histoire de la navigation: JavaScript cesse d'exécuter après avoir utilisé le bouton de retour de Firefox Les utilisateurs ...La programmation Publié le 2025-04-09















Étudier le chinois
- 1 Comment dit-on « marcher » en chinois ? 走路 Prononciation chinoise, 走路 Apprentissage du chinois
- 2 Comment dit-on « prendre l’avion » en chinois ? 坐飞机 Prononciation chinoise, 坐飞机 Apprentissage du chinois
- 3 Comment dit-on « prendre un train » en chinois ? 坐火车 Prononciation chinoise, 坐火车 Apprentissage du chinois
- 4 Comment dit-on « prendre un bus » en chinois ? 坐车 Prononciation chinoise, 坐车 Apprentissage du chinois
- 5 Comment dire conduire en chinois? 开车 Prononciation chinoise, 开车 Apprentissage du chinois
- 6 Comment dit-on nager en chinois ? 游泳 Prononciation chinoise, 游泳 Apprentissage du chinois
- 7 Comment dit-on faire du vélo en chinois ? 骑自行车 Prononciation chinoise, 骑自行车 Apprentissage du chinois
- 8 Comment dit-on bonjour en chinois ? 你好Prononciation chinoise, 你好Apprentissage du chinois
- 9 Comment dit-on merci en chinois ? 谢谢Prononciation chinoise, 谢谢Apprentissage du chinois
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









