 الصفحة الأمامية > برمجة > لقد قمت بإنشاء تطبيق للتحقق من عدد الرموز باستخدام Streamlit في Snowflake (SiS)
الصفحة الأمامية > برمجة > لقد قمت بإنشاء تطبيق للتحقق من عدد الرموز باستخدام Streamlit في Snowflake (SiS)
لقد قمت بإنشاء تطبيق للتحقق من عدد الرموز باستخدام Streamlit في Snowflake (SiS)
 تصفح:557
تصفح:557
مقدمة
مرحبًا، أنا مهندس مبيعات في Snowflake. أود أن أشارككم بعض تجاربي وتجاربي من خلال منشورات متنوعة. في هذه المقالة، سأوضح لك كيفية إنشاء تطبيق باستخدام Streamlit في Snowflake للتحقق من عدد الرموز المميزة وتقدير التكاليف لـ Cortex LLM.
ملاحظة: هذا المنشور يمثل وجهات نظري الشخصية وليس آراء Snowflake.
ما هو Streamlit في ندفة الثلج (SiS)؟
Streamlit هي مكتبة Python تتيح لك إنشاء واجهات مستخدم ويب باستخدام كود Python البسيط، مما يلغي الحاجة إلى HTML/CSS/JavaScript. يمكنك مشاهدة الأمثلة في معرض التطبيقات.
يمكّنك Streamlit in Snowflake من تطوير تطبيقات الويب Streamlit وتشغيلها مباشرةً على Snowflake. إنه سهل الاستخدام من خلال حساب Snowflake فقط وهو رائع لدمج بيانات جدول Snowflake في تطبيقات الويب.
حول Streamlit in Snowflake (التوثيق الرسمي لـ Snowflake)
ما هي قشرة ندفة الثلج؟
Snowflake Cortex عبارة عن مجموعة من ميزات الذكاء الاصطناعي التوليدية في Snowflake. يتيح لك Cortex LLM استدعاء نماذج اللغات الكبيرة التي تعمل على Snowflake باستخدام وظائف بسيطة في SQL أو Python.
وظائف نموذج اللغة الكبيرة (LLM) (قشرة ندفة الثلج) (التوثيق الرسمي لندفة الثلج)
نظرة عامة على الميزات
صورة
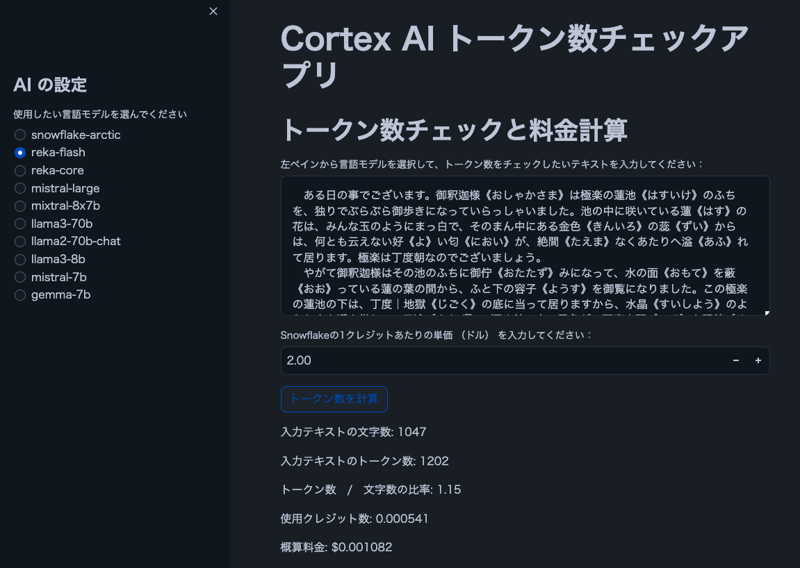
ملاحظة: النص الموجود في الصورة مأخوذ من "The Spider's Thread" بقلم ريونوسوكي أكوتاجاوا.
سمات
- يمكن للمستخدمين تحديد نموذج Cortex LLM
- عرض عدد الأحرف والرموز المميزة للنص الذي يدخله المستخدم
- إظهار نسبة الرموز المميزة إلى الأحرف
- حساب التكلفة المقدرة بناءً على تسعير رصيد Snowflake
ملاحظة: جدول تسعير Cortex LLM (PDF)
المتطلبات الأساسية
- حساب Snowflake مع إمكانية الوصول إلى Cortex LLM
- Snowflake-ml-python 1.1.2 أو الأحدث
ملاحظة: توفر منطقة Cortex LLM (التوثيق الرسمي لندفة الثلج)
كود المصدر
import streamlit as st
from snowflake.snowpark.context import get_active_session
import snowflake.snowpark.functions as F
# Get current session
session = get_active_session()
# Application title
st.title("Cortex AI Token Count Checker")
# AI settings
st.sidebar.title("AI Settings")
lang_model = st.sidebar.radio("Select the language model you want to use",
("snowflake-arctic", "reka-core", "reka-flash",
"mistral-large2", "mistral-large", "mixtral-8x7b", "mistral-7b",
"llama3.1-405b", "llama3.1-70b", "llama3.1-8b",
"llama3-70b", "llama3-8b", "llama2-70b-chat",
"jamba-instruct", "gemma-7b")
)
# Function to count tokens (using Cortex's token counting function)
def count_tokens(model, text):
result = session.sql(f"SELECT SNOWFLAKE.CORTEX.COUNT_TOKENS('{model}', '{text}') as token_count").collect()
return result[0]['TOKEN_COUNT']
# Token count check and cost calculation
st.header("Token Count Check and Cost Calculation")
input_text = st.text_area("Select a language model from the left pane and enter the text you want to check for token count:", height=200)
# Let user input the price per credit
credit_price = st.number_input("Enter the price per Snowflake credit (in dollars):", min_value=0.0, value=2.0, step=0.01)
# Credits per 1M tokens for each model (as of 2024/8/30, mistral-large2 is not supported)
model_credits = {
"snowflake-arctic": 0.84,
"reka-core": 5.5,
"reka-flash": 0.45,
"mistral-large2": 1.95,
"mistral-large": 5.1,
"mixtral-8x7b": 0.22,
"mistral-7b": 0.12,
"llama3.1-405b": 3,
"llama3.1-70b": 1.21,
"llama3.1-8b": 0.19,
"llama3-70b": 1.21,
"llama3-8b": 0.19,
"llama2-70b-chat": 0.45,
"jamba-instruct": 0.83,
"gemma-7b": 0.12
}
if st.button("Calculate Token Count"):
if input_text:
# Calculate character count
char_count = len(input_text)
st.write(f"Character count of input text: {char_count}")
if lang_model in model_credits:
# Calculate token count
token_count = count_tokens(lang_model, input_text)
st.write(f"Token count of input text: {token_count}")
# Ratio of tokens to characters
ratio = token_count / char_count if char_count > 0 else 0
st.write(f"Token count / Character count ratio: {ratio:.2f}")
# Cost calculation
credits_used = (token_count / 1000000) * model_credits[lang_model]
cost = credits_used * credit_price
st.write(f"Credits used: {credits_used:.6f}")
st.write(f"Estimated cost: ${cost:.6f}")
else:
st.warning("The selected model is not supported by Snowflake's token counting feature.")
else:
st.warning("Please enter some text.")
خاتمة
يسهل هذا التطبيق تقدير تكاليف أعباء عمل LLM، خاصة عند التعامل مع لغات مثل اليابانية حيث توجد غالبًا فجوة بين عدد الأحرف وعدد الرموز المميزة. أتمنى أن تجدها مفيدة!
إعلانات
Snowflake ما الجديد في التحديثات على X
أنا أشارك تحديثات Snowflake الجديدة على X. فلا تتردد في المتابعة إذا كنت مهتمًا!
النسخة الانجليزية
الروبوت الجديد لندفة الثلج (النسخة الإنجليزية)
https://x.com/snow_new_en
النسخة اليابانية
الروبوت الجديد لندفة الثلج (النسخة اليابانية)
https://x.com/snow_new_jp
تغيير التاريخ
(20240914) المشاركة الأولية
المادة اليابانية الأصلية
https://zenn.dev/tsubasa_tech/articles/4dd80c91508ec4
-
 لماذا تفشل Microsoft Visual C ++ في تنفيذ إنشاء مثيل للقالب ثنائي المراحل بشكل صحيح؟] ما هي الجوانب المحددة للآلية تفشل في العمل كما هو متوقع؟ ومع ذلك ، تنشأ الشكوك فيما يتعلق بما إذا كان هذا الشيك يتحقق مما إذا كان يتم الإعلان عن الأ...برمجة نشر في 2025-03-12
لماذا تفشل Microsoft Visual C ++ في تنفيذ إنشاء مثيل للقالب ثنائي المراحل بشكل صحيح؟] ما هي الجوانب المحددة للآلية تفشل في العمل كما هو متوقع؟ ومع ذلك ، تنشأ الشكوك فيما يتعلق بما إذا كان هذا الشيك يتحقق مما إذا كان يتم الإعلان عن الأ...برمجة نشر في 2025-03-12 -
UTF-8 مقابل Latin-1: سر ترميز الشخصية!في خضم تطبيقاتهم ، ينشأ سؤال أساسي: ما هي الخصائص المميزة التي تميز هذين الترميزين؟ في حين أن Latin1 يلبي احتياجات الشخصيات اللاتينية على وجه التحد...برمجة نشر في 2025-03-12
-
كيف يمكنني استبدال سلاسل متعددة بكفاءة في سلسلة Java؟ومع ذلك ، يمكن أن يكون هذا غير فعال بالنسبة للسلاسل الكبيرة أو عند العمل مع العديد من الأوتار. تتيح لك التعبيرات العادية تحديد أنماط البحث المعقدة ...برمجة نشر في 2025-03-12
-
سلسلة حقن SQL: شرح مفصل لتقنيات حقن SQL المتقدمةأداة Waymap Pentesting: انقر هنا Trixsec Github: انقر هنا Trixsec Telegram: انقر هنا مستغلات حقن SQL المتقدمة-الجزء 7: التقنيات المتط...برمجة نشر في 2025-03-12
-
كيف يمكننا تأمين تحميل الملفات مقابل المحتوى الضار؟تتعلق الأمان مع تحميل الملفات يعد فهم هذه التهديدات وتنفيذ استراتيجيات التخفيف الفعالة أمرًا بالغ الأهمية للحفاظ على أمان التطبيق الخاص بك. لذل...برمجة نشر في 2025-03-12
-
كيفية إزالة فواصل الخط من الأوتار باستخدام تعبيرات منتظمة في JavaScript؟إزالة خطوط الخط من الأوتار في سيناريو الكود هذا ، يتمثل الهدف في إزالتها من سلسلة من سلسلة نصية من نص باستخدام سمة .value. ينشأ السؤال: كيف يمكن...برمجة نشر في 2025-03-12
-
لماذا يتوقف تنفيذ JavaScript عند استخدام زر عودة Firefox؟مشكلة السجل الملحي: قد يتوقف JavaScript عن التنفيذ بعد استخدام زر عودة Firefox قد يواجه مستخدمو Firefox مشكلة حيث فشل JavaScriptts في الركض عن...برمجة نشر في 2025-03-12
-
كيفية إدراج النقط (الصور) بشكل صحيح في MySQL باستخدام PHP؟مشكلة. سيوفر هذا الدليل حلولًا لتخزين بيانات الصور الخاصة بك بنجاح. إصدار ImageId ، صورة) القيم ('$ this- & gt ؛ image_id' ، 'fi...برمجة نشر في 2025-03-12
-
هل يمكنني ترحيل التشفير الخاص بي من Mcrypt إلى OpenSSL ، وفك تشفير البيانات المشفرة Mcrypt باستخدام OpenSSL؟ترقية مكتبة التشفير الخاصة بي من mcrypt إلى openssl هل يمكنني ترقية مكتبة التشفير الخاصة بي من mcrypt إلى openssl؟ في OpenSSL ، هل من الممكن ف...برمجة نشر في 2025-03-12
-
هل هناك اختلاف في الأداء بين استخدام حلقة EACH وتكرار لجمع اجتماعي في Java؟تستكشف هذه المقالة اختلافات الكفاءة بين هذين النهجين. يستخدم ITerator داخليًا: قائمة a = new ArrayList () ؛ ل (عدد صحيح عدد صحيح: أ) { intege...برمجة نشر في 2025-03-12
-
كيفية التحقق مما إذا كان كائن لديه سمة محددة في بيثون؟فكر في المثال التالي حيث تثير محاولة الوصول إلى خاصية غير محددة خطأً: >>> a = someclass () >>> A.Property Traceback (أحدث مكالمة أخيرة): ملف &...برمجة نشر في 2025-03-12
-
شرح مفصل لطريقة الحصول على العناصر العشوائية Java Hashset/LinkedHashsetالعثور على عنصر عشوائي في مجموعة في البرمجة ، قد يكون من المفيد تحديد عنصر عشوائي من مجموعة ، مثل مجموعة. توفر Java أنواعًا متعددة من المجموعات ...برمجة نشر في 2025-03-12
-
متى يعزو CSS إلى الوراء إلى وحدات البكسل (PX) بدون وحدات؟سمات CSS بدون وحدات: دراسة حالة غالبًا ما تتطلب سمات CSS وحدات (على سبيل المثال ، px ، em ، ٪) لتحديد قيمها. ومع ذلك ، في بعض السيناريوهات ، ق...برمجة نشر في 2025-03-12
-
كيف تسترجع أحدث مكتبة jQuery من Google APIs؟لاسترداد أحدث إصدار ، كان هناك سابقًا بديلًا لاستخدام رقم إصدار معين ، والذي كان لاستخدام بناء الجملة التالي: /latest/jquery.js Budaps &&. للحصول...برمجة نشر في 2025-03-12















دراسة اللغة الصينية
- 1 كيف تقول "المشي" باللغة الصينية؟ 走路 نطق الصينية، 走路 تعلم اللغة الصينية
- 2 كيف تقول "استقل طائرة" بالصينية؟ 坐飞机 نطق الصينية، 坐飞机 تعلم اللغة الصينية
- 3 كيف تقول "استقل القطار" بالصينية؟ 坐火车 نطق الصينية، 坐火车 تعلم اللغة الصينية
- 4 كيف تقول "استقل الحافلة" باللغة الصينية؟ 坐车 نطق الصينية، 坐车 تعلم اللغة الصينية
- 5 كيف أقول القيادة باللغة الصينية؟ 开车 نطق الصينية، 开车 تعلم اللغة الصينية
- 6 كيف تقول السباحة باللغة الصينية؟ 游泳 نطق الصينية، 游泳 تعلم اللغة الصينية
- 7 كيف يمكنك أن تقول ركوب الدراجة باللغة الصينية؟ 骑自行车 نطق الصينية، 骑自行车 تعلم اللغة الصينية
- 8 كيف تقول مرحبا باللغة الصينية؟ # نطق اللغة الصينية، # تعلّم اللغة الصينية
- 9 كيف تقول شكرا باللغة الصينية؟ # نطق اللغة الصينية، # تعلّم اللغة الصينية
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









