
FireDucks: احصل على أداء يفوق أداء الباندا بدون تكلفة تعليمية!
 تصفح:429
تصفح:429
تعد Pandas إحدى المكتبات الأكثر شهرة، وعندما كنت أبحث عن طريقة أسهل لتسريع أدائها، اكتشفت FireDucks وأصبحت مهتمًا بها!
المقارنة مع الباندا: لماذا FireDucks؟
قد يواجه برنامج Pandas مشكلة خطيرة في الأداء اعتمادًا على كيفية كتابته. ومع ذلك، كوني عالم بيانات، أرغب في قضاء المزيد والمزيد من الوقت في تحليل البيانات بدلاً من تحسين أداء التعليمات البرمجية الخاصة بي. لذا، سيكون أمرًا رائعًا لو تمكن من القيام بشيء مثل تبادل ترتيب العمليات وتسريع أداء البرنامج تلقائيًا. على سبيل المثال، العملية أ => العملية ب ستكون أبطأ، لذلك سنستبدلها بالعملية ب => العملية أ. (بالطبع، النتيجة مضمونة أن تكون هي نفسها.) يقال إن علماء البيانات ينفقون حوالي 45% من الوقت الذي قضوه في إعداد البيانات، وعندما كنت أفكر في القيام بشيء ما لتسريع العملية، عثرت على وحدة تسمى FireDucks.
من وثائق FireDucks، يبدو أنه مدعوم لمنصات Linux فقط. نظرًا لأنني أستخدم Windows على جهازي الرئيسي، فأنا أرغب في تجربته من WSL2 (نظام Windows الفرعي لنظام Linux)، وهي بيئة يمكنها تشغيل Linux على Windows.
البيئة التي جربتها هي كما يلي.
- نظام التشغيل مايكروسوفت ويندوز 11 برو
- الإصدار 10.0.22631 النسخة 22631
- طراز النظام Z690 Pro RS
- نوع النظام المستند إلى x64
- معالج الكمبيوتر الشخصي من الجيل الثاني عشر Intel(R) Core(TM) i3–12100، 3300 ميجاهرتز، 4 مراكز، 8 معالجات منطقية
- منتج اللوحة الأساسية Z690 Pro RS
- سطح المكتب لدور النظام الأساسي
- الذاكرة الفعلية المثبتة (RAM)64.0 جيجابايت
تثبيت وتكوين FireDucks
قم بتثبيت WSL
تم تثبيت WSL بمساعدة وثائق Microsoft التالية؛ توزيعة Linux هي Ubuntu 22.04.1 LTS.
قم بتثبيت FireDucks
ثم قم بالفعل بتثبيت FireDucks. ومع ذلك، فمن السهل جدًا تثبيته.
تثبيت النقطة Fireucks
سيستغرق تثبيت FireDucks بضع دقائق (جنبًا إلى جنب مع pyarrow وpandas والمكتبات الأخرى).
لقد حاولت تنفيذ التعليمات البرمجية أدناه، وكانت سرعة التحميل سريعة جدًا، واستغرق الباندا 4 ثوانٍ، واستغرق FireDucks 74.5 نانو ثانية فقط.
# 1. analysis based on time period and creative duration # convert timestamp to date/time object df['timestamp_converted'] = pd.to_datetime(df['timestamp'], unit='s ') # define time period def get_part_of_day(hour): if 5استغرقت كل هذه المعالجة المسبقة للبيانات وتحليلها حوالي 8 ثوانٍ في الباندا، بينما يمكن إكمالها في غضون 4 ثوانٍ عند استخدام FireDucks. يمكن تحقيق سرعة مضاعفة تقريبًا.
تحسين الأداء
أحد أكثر الأشياء إرهاقًا في استخدام الباندا هو الانتظار عند تحميل مجموعات كبيرة من البيانات، ثم يتعين علي الانتظار حتى يتم إجراء عملية معقدة مثل التجميع. من ناحية أخرى، نظرًا لأن FireDucks يقوم بالتقييم البطيء، فإن التحميل نفسه لا يستغرق وقتًا على الإطلاق، لذا تتم المعالجة حيثما تكون هناك حاجة إليها، وشعرت أنها كانت مهمة جدًا مع انخفاض كبير في إجمالي وقت الانتظار.
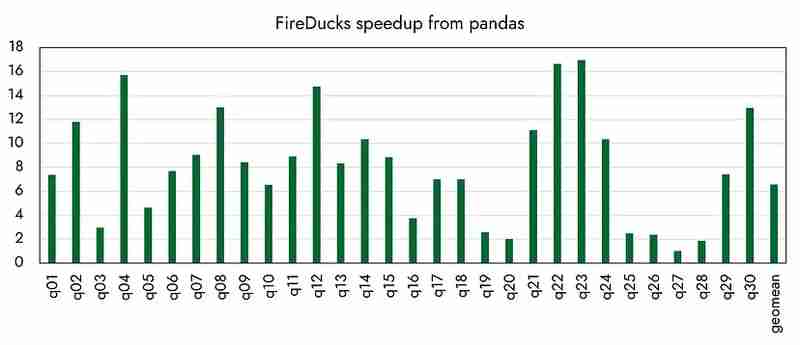
أما بالنسبة للأداء الآخر، فيبدو أنه تم تحقيق أسرع بما يصل إلى 16 مرة مقارنة بالباندا، كما أعلنت المنظمة رسميًا. (سأقارن الأداء مع مختلف المكتبات المنافسة في المرة القادمة.)
تكلفة التعلم صفر
تعد القدرة على اتباع تدوين الباندا الدقيق دون الحاجة إلى التفكير في أي شيء ميزة كبيرة. وبصرف النظر عن FireDucks، هناك مكتبات أخرى لتسريع إطارات البيانات، ولكنها مكلفة للغاية للتعلم ومن السهل جدًا نسيانها.
على سبيل المثال، إذا كنت تريد إضافة أعمدة ذات أقطاب، عليك كتابة شيء مثل هذا.
# pandas df["new_col"] = df["A"] 1 # polars df = df.with_columns((pl.col("A") 1).alias("new_col"))لا حاجة تقريبًا لتغيير الكود الموجود
لدي العديد من ETLs والمشاريع الأخرى التي تستخدم الباندا، وسيكون من الجيد رؤية تحسن في الأداء فقط عن طريق تثبيت بيان الاستيراد واستبداله بـ FireDucks.
إذا كنت تريد إضافتها بشكل أكبر، فلا تتردد في التعليق أدناه.
-
 لماذا تفشل Microsoft Visual C ++ في تنفيذ إنشاء مثيل للقالب ثنائي المراحل بشكل صحيح؟] ما هي الجوانب المحددة للآلية تفشل في العمل كما هو متوقع؟ ومع ذلك ، تنشأ الشكوك فيما يتعلق بما إذا كان هذا الشيك يتحقق مما إذا كان يتم الإعلان عن الأ...برمجة نشر في 2025-03-12
لماذا تفشل Microsoft Visual C ++ في تنفيذ إنشاء مثيل للقالب ثنائي المراحل بشكل صحيح؟] ما هي الجوانب المحددة للآلية تفشل في العمل كما هو متوقع؟ ومع ذلك ، تنشأ الشكوك فيما يتعلق بما إذا كان هذا الشيك يتحقق مما إذا كان يتم الإعلان عن الأ...برمجة نشر في 2025-03-12 -
UTF-8 مقابل Latin-1: سر ترميز الشخصية!في خضم تطبيقاتهم ، ينشأ سؤال أساسي: ما هي الخصائص المميزة التي تميز هذين الترميزين؟ في حين أن Latin1 يلبي احتياجات الشخصيات اللاتينية على وجه التحد...برمجة نشر في 2025-03-12
-
كيف يمكنني استبدال سلاسل متعددة بكفاءة في سلسلة Java؟ومع ذلك ، يمكن أن يكون هذا غير فعال بالنسبة للسلاسل الكبيرة أو عند العمل مع العديد من الأوتار. تتيح لك التعبيرات العادية تحديد أنماط البحث المعقدة ...برمجة نشر في 2025-03-12
-
سلسلة حقن SQL: شرح مفصل لتقنيات حقن SQL المتقدمةأداة Waymap Pentesting: انقر هنا Trixsec Github: انقر هنا Trixsec Telegram: انقر هنا مستغلات حقن SQL المتقدمة-الجزء 7: التقنيات المتط...برمجة نشر في 2025-03-12
-
كيف يمكننا تأمين تحميل الملفات مقابل المحتوى الضار؟تتعلق الأمان مع تحميل الملفات يعد فهم هذه التهديدات وتنفيذ استراتيجيات التخفيف الفعالة أمرًا بالغ الأهمية للحفاظ على أمان التطبيق الخاص بك. لذل...برمجة نشر في 2025-03-12
-
كيفية إزالة فواصل الخط من الأوتار باستخدام تعبيرات منتظمة في JavaScript؟إزالة خطوط الخط من الأوتار في سيناريو الكود هذا ، يتمثل الهدف في إزالتها من سلسلة من سلسلة نصية من نص باستخدام سمة .value. ينشأ السؤال: كيف يمكن...برمجة نشر في 2025-03-12
-
لماذا يتوقف تنفيذ JavaScript عند استخدام زر عودة Firefox؟مشكلة السجل الملحي: قد يتوقف JavaScript عن التنفيذ بعد استخدام زر عودة Firefox قد يواجه مستخدمو Firefox مشكلة حيث فشل JavaScriptts في الركض عن...برمجة نشر في 2025-03-12
-
كيفية إدراج النقط (الصور) بشكل صحيح في MySQL باستخدام PHP؟مشكلة. سيوفر هذا الدليل حلولًا لتخزين بيانات الصور الخاصة بك بنجاح. إصدار ImageId ، صورة) القيم ('$ this- & gt ؛ image_id' ، 'fi...برمجة نشر في 2025-03-12
-
هل يمكنني ترحيل التشفير الخاص بي من Mcrypt إلى OpenSSL ، وفك تشفير البيانات المشفرة Mcrypt باستخدام OpenSSL؟ترقية مكتبة التشفير الخاصة بي من mcrypt إلى openssl هل يمكنني ترقية مكتبة التشفير الخاصة بي من mcrypt إلى openssl؟ في OpenSSL ، هل من الممكن ف...برمجة نشر في 2025-03-12
-
هل هناك اختلاف في الأداء بين استخدام حلقة EACH وتكرار لجمع اجتماعي في Java؟تستكشف هذه المقالة اختلافات الكفاءة بين هذين النهجين. يستخدم ITerator داخليًا: قائمة a = new ArrayList () ؛ ل (عدد صحيح عدد صحيح: أ) { intege...برمجة نشر في 2025-03-12
-
كيفية التحقق مما إذا كان كائن لديه سمة محددة في بيثون؟فكر في المثال التالي حيث تثير محاولة الوصول إلى خاصية غير محددة خطأً: >>> a = someclass () >>> A.Property Traceback (أحدث مكالمة أخيرة): ملف &...برمجة نشر في 2025-03-12
-
شرح مفصل لطريقة الحصول على العناصر العشوائية Java Hashset/LinkedHashsetالعثور على عنصر عشوائي في مجموعة في البرمجة ، قد يكون من المفيد تحديد عنصر عشوائي من مجموعة ، مثل مجموعة. توفر Java أنواعًا متعددة من المجموعات ...برمجة نشر في 2025-03-12
-
متى يعزو CSS إلى الوراء إلى وحدات البكسل (PX) بدون وحدات؟سمات CSS بدون وحدات: دراسة حالة غالبًا ما تتطلب سمات CSS وحدات (على سبيل المثال ، px ، em ، ٪) لتحديد قيمها. ومع ذلك ، في بعض السيناريوهات ، ق...برمجة نشر في 2025-03-12
-
كيف تسترجع أحدث مكتبة jQuery من Google APIs؟لاسترداد أحدث إصدار ، كان هناك سابقًا بديلًا لاستخدام رقم إصدار معين ، والذي كان لاستخدام بناء الجملة التالي: /latest/jquery.js Budaps &&. للحصول...برمجة نشر في 2025-03-12















دراسة اللغة الصينية
- 1 كيف تقول "المشي" باللغة الصينية؟ 走路 نطق الصينية، 走路 تعلم اللغة الصينية
- 2 كيف تقول "استقل طائرة" بالصينية؟ 坐飞机 نطق الصينية، 坐飞机 تعلم اللغة الصينية
- 3 كيف تقول "استقل القطار" بالصينية؟ 坐火车 نطق الصينية، 坐火车 تعلم اللغة الصينية
- 4 كيف تقول "استقل الحافلة" باللغة الصينية؟ 坐车 نطق الصينية، 坐车 تعلم اللغة الصينية
- 5 كيف أقول القيادة باللغة الصينية؟ 开车 نطق الصينية، 开车 تعلم اللغة الصينية
- 6 كيف تقول السباحة باللغة الصينية؟ 游泳 نطق الصينية، 游泳 تعلم اللغة الصينية
- 7 كيف يمكنك أن تقول ركوب الدراجة باللغة الصينية؟ 骑自行车 نطق الصينية، 骑自行车 تعلم اللغة الصينية
- 8 كيف تقول مرحبا باللغة الصينية؟ # نطق اللغة الصينية، # تعلّم اللغة الصينية
- 9 كيف تقول شكرا باللغة الصينية؟ # نطق اللغة الصينية، # تعلّم اللغة الصينية
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









