
الفطر السحري: استكشاف ومعالجة البيانات الفارغة باستخدام Mage
 تصفح:187
تصفح:187
Mage هي أداة قوية لمهام ETL، مع ميزات تتيح استكشاف البيانات واستخراجها، وتصورات سريعة من خلال قوالب الرسوم البيانية والعديد من الميزات الأخرى التي تحول عملك بالبيانات إلى شيء سحري.
في معالجة البيانات، أثناء عملية ETL، من الشائع العثور على البيانات المفقودة التي يمكن أن تولد مشاكل في المستقبل، اعتمادًا على النشاط الذي سننفذه مع مجموعة البيانات، يمكن أن تكون البيانات الفارغة مدمرة تمامًا.
لتحديد عدم وجود بيانات في مجموعة البيانات الخاصة بنا، يمكننا استخدام Python ومكتبة Pandas للتحقق من البيانات التي تقدم قيمًا فارغة، بالإضافة إلى أنه يمكننا إنشاء رسوم بيانية توضح بشكل أكثر وضوحًا تأثير هذه القيم الخالية في مجموعة البيانات لدينا.
يتكون مسارنا من 4 خطوات: البدء بتحميل البيانات وخطوتين للمعالجة وتصدير البيانات.
محمل البيانات
سنستخدم في هذه المقالة مجموعة البيانات: التنبؤ الثنائي بالفطر السام والمتاح على Kaggle كجزء من المنافسة. دعونا نستخدم مجموعة بيانات التدريب المتاحة على الموقع.
فلنقم بإنشاء خطوة أداة تحميل البيانات باستخدام لغة بايثون حتى نتمكن من تحميل البيانات التي سنستخدمها. قبل هذه الخطوة، قمت بإنشاء جدول في قاعدة بيانات Postgres، وهو موجود محليًا على جهازي، حتى أتمكن من تحميل البيانات. نظرًا لأن البيانات موجودة في Postgres، فسوف نستخدم قالب تحميل Postgres المحدد بالفعل داخل Mage.
from mage_ai.settings.repo import get_repo_path from mage_ai.io.config import ConfigFileLoader from mage_ai.io.postgres import Postgres from os import path if 'data_loader' not in globals(): from mage_ai.data_preparation.decorators import data_loader if 'test' not in globals(): from mage_ai.data_preparation.decorators import test @data_loader def load_data_from_postgres(*args, **kwargs): """ Template for loading data from a PostgreSQL database. Specify your configuration settings in 'io_config.yaml'. Docs: https://docs.mage.ai/design/data-loading#postgresql """ query = 'SELECT * FROM mushroom' # Specify your SQL query here config_path = path.join(get_repo_path(), 'io_config.yaml') config_profile = 'default' with Postgres.with_config(ConfigFileLoader(config_path, config_profile)) as loader: return loader.load(query) @test def test_output(output, *args) -> None: """ Template code for testing the output of the block. """ assert output is not None, 'The output is undefined'
ضمن الدالة load_data_from_postgres() سنقوم بتحديد الاستعلام الذي سنستخدمه لتحميل الجدول في قاعدة البيانات. في حالتي، قمت بتكوين معلومات البنك في الملف io_config.yaml حيث تم تعريفها على أنها التكوين الافتراضي، لذلك نحتاج فقط إلى تمرير الاسم الافتراضي إلى المتغير config_profile.
بعد تنفيذ الكتلة، سنستخدم ميزة إضافة مخطط، والتي ستوفر معلومات حول بياناتنا من خلال قوالب محددة بالفعل. ما عليك سوى النقر على الأيقونة الموجودة بجوار زر التشغيل، والمميزة في الصورة بخط أصفر.

سنختار خيارين لاستكشاف مجموعة البيانات الخاصة بنا بشكل أكبر، خياري summay_overview وfeature_profiles. من خلال Summary_overview، نحصل على معلومات حول عدد الأعمدة والصفوف في مجموعة البيانات. يمكننا أيضًا عرض إجمالي عدد الأعمدة حسب النوع، على سبيل المثال إجمالي عدد الأعمدة الفئوية والرقمية والبوليانية. من ناحية أخرى، تقدم ميزة Features_profiles معلومات وصفية أكثر حول البيانات، مثل: النوع، الحد الأدنى للقيمة، الحد الأقصى للقيمة، من بين معلومات أخرى، يمكننا حتى تصور القيم المفقودة، والتي هي محور معالجتنا.
لكي نتمكن من التركيز بشكل أكبر على البيانات المفقودة، فلنستخدم القالب: % من القيم المفقودة، ورسم بياني شريطي مع النسبة المئوية للبيانات المفقودة، في كل عمود.
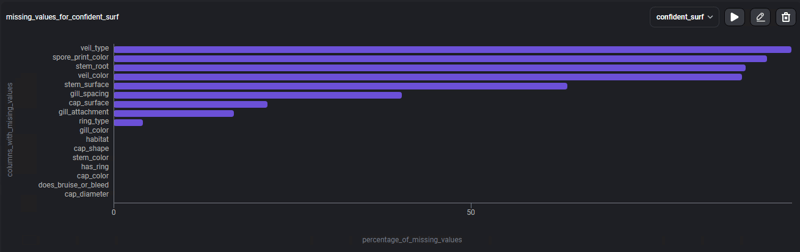
يعرض الرسم البياني 4 أعمدة حيث تقابل القيم المفقودة أكثر من 80% من محتواه، وأعمدة أخرى تمثل القيم المفقودة ولكن بكميات أقل، تتيح لنا هذه المعلومات الآن البحث عن استراتيجيات مختلفة للتعامل مع هذا بيانات فارغة
أعمدة إسقاط المحولات
بالنسبة للأعمدة التي تحتوي على أكثر من 80% من القيم الخالية، ستكون الإستراتيجية التي سنتبعها هي تنفيذ أعمدة إسقاط في إطار البيانات، وتحديد الأعمدة التي سنقوم باستبعادها من إطار البيانات. باستخدام كتلة TRANSFORMER في لغة بايثون، سنختار خيار إزالة العمود .
from mage_ai.data_cleaner.transformer_actions.base import BaseAction from mage_ai.data_cleaner.transformer_actions.constants import ActionType, Axis from mage_ai.data_cleaner.transformer_actions.utils import build_transformer_action from pandas import DataFrame if 'transformer' not in globals(): from mage_ai.data_preparation.decorators import transformer if 'test' not in globals(): from mage_ai.data_preparation.decorators import test @transformer def execute_transformer_action(df: DataFrame, *args, **kwargs) -> DataFrame: """ Execute Transformer Action: ActionType.REMOVE Docs: https://docs.mage.ai/guides/transformer-blocks#remove-columns """ action = build_transformer_action( df, action_type=ActionType.REMOVE, arguments=['veil_type', 'spore_print_color', 'stem_root', 'veil_color'], axis=Axis.COLUMN, ) return BaseAction(action).execute(df) @test def test_output(output, *args) -> None: """ Template code for testing the output of the block. """ assert output is not None, 'The output is undefined'
ضمن الوظيفة execute_transformer_action() سنقوم بإدراج قائمة بأسماء الأعمدة التي نريد استبعادها من مجموعة البيانات، في متغير الوسائط، بعد هذه الخطوة، فقط قم بتنفيذ الكتلة.
تعبئة المحولات بالقيم المفقودة
الآن بالنسبة للأعمدة التي تحتوي على أقل من 80% من القيم الخالية، سنستخدم استراتيجية ملء القيم المفقودة، كما هو الحال في بعض الحالات على الرغم من وجود بيانات مفقودة، واستبدالها بقيم مثل متوسطًا أو عصريًا، فقد يكون قادرًا على تلبية احتياجات البيانات دون التسبب في العديد من التغييرات في مجموعة البيانات، اعتمادًا على هدفك النهائي.
هناك بعض المهام، مثل التصنيف، حيث يمكن أن يساهم استبدال البيانات المفقودة بقيمة ذات صلة (الوضع، المتوسط، الوسيط) لمجموعة البيانات، في خوارزمية التصنيف، والتي يمكن أن تصل إلى استنتاجات أخرى إذا تم حذف البيانات كما في الإستراتيجية الأخرى التي استخدمناها.
لاتخاذ قرار بشأن القياس الذي سنستخدمه، سوف نستخدم وظيفة Mage إضافة مخطط مرة أخرى. باستخدام القالب القيم الأكثر شيوعًا يمكننا تصور وضع وتكرار هذه القيمة في كل عمود.
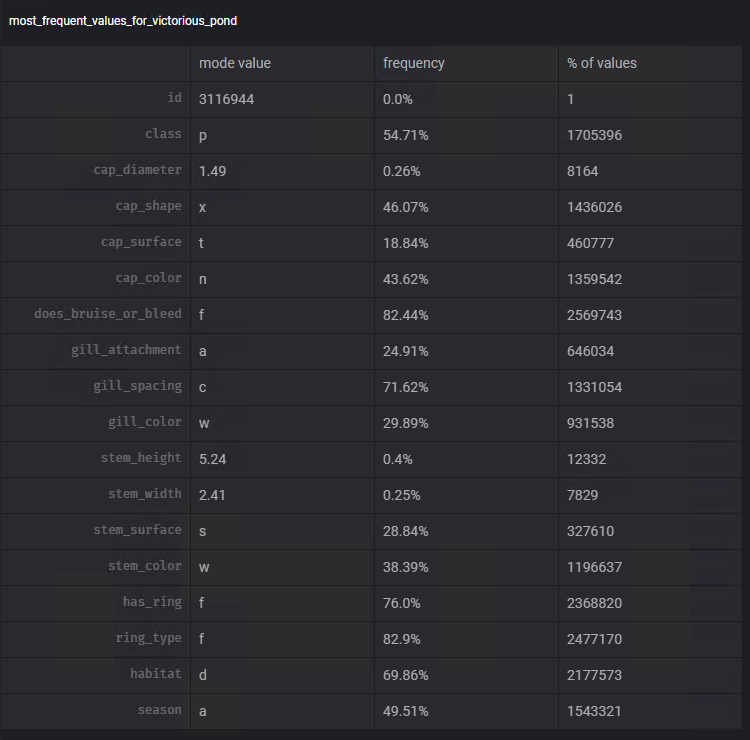
باتباع الخطوات المشابهة للخطوات السابقة، سنستخدم المحول ملء القيم المفقودة، للقيام بمهمة طرح البيانات المفقودة باستخدام الوضع الخاص بكل عمود: steam_surface، gill_spacing، cap_surface ، مرفق الخياشيم، نوع الحلقة.
from mage_ai.data_cleaner.transformer_actions.constants import ImputationStrategy
from mage_ai.data_cleaner.transformer_actions.base import BaseAction
from mage_ai.data_cleaner.transformer_actions.constants import ActionType, Axis
from mage_ai.data_cleaner.transformer_actions.utils import build_transformer_action
from pandas import DataFrame
if 'transformer' not in globals():
from mage_ai.data_preparation.decorators import transformer
if 'test' not in globals():
from mage_ai.data_preparation.decorators import test
@transformer
def execute_transformer_action(df: DataFrame, *args, **kwargs) -> DataFrame:
"""
Execute Transformer Action: ActionType.IMPUTE
Docs: https://docs.mage.ai/guides/transformer-blocks#fill-in-missing-values
"""
action = build_transformer_action(
df,
action_type=ActionType.IMPUTE,
arguments=df.columns, # Specify columns to impute
axis=Axis.COLUMN,
options={'strategy': ImputationStrategy.MODE}, # Specify imputation strategy
)
return BaseAction(action).execute(df)
@test
def test_output(output, *args) -> None:
"""
Template code for testing the output of the block.
"""
assert output is not None, 'The output is undefined'
في الدالة execute_transformer_action()، نحدد استراتيجية استبدال البيانات في قاموس بايثون. لمزيد من خيارات الاستبدال، ما عليك سوى الوصول إلى وثائق المحول: https://docs.mage.ai/guides/transformer-blocks#fill-in-missing-values.
مصدر البيانات
عند تنفيذ جميع التحويلات، سنحفظ مجموعة البيانات التي تمت معالجتها الآن، في نفس قاعدة بيانات Postgres ولكن الآن باسم مختلف حتى نتمكن من التمييز. باستخدام كتلة Data Exporter واختيار Postgres، سنحدد الشيما والجدول الذي نريد حفظه، مع تذكر أن تكوينات قاعدة البيانات قد تم حفظها مسبقًا في الملف io_config.yaml.
from mage_ai.settings.repo import get_repo_path from mage_ai.io.config import ConfigFileLoader from mage_ai.io.postgres import Postgres from pandas import DataFrame from os import path if 'data_exporter' not in globals(): from mage_ai.data_preparation.decorators import data_exporter @data_exporter def export_data_to_postgres(df: DataFrame, **kwargs) -> None: """ Template for exporting data to a PostgreSQL database. Specify your configuration settings in 'io_config.yaml'. Docs: https://docs.mage.ai/design/data-loading#postgresql """ schema_name = 'public' # Specify the name of the schema to export data to table_name = 'mushroom_clean' # Specify the name of the table to export data to config_path = path.join(get_repo_path(), 'io_config.yaml') config_profile = 'default' with Postgres.with_config(ConfigFileLoader(config_path, config_profile)) as loader: loader.export( df, schema_name, table_name, index=False, # Specifies whether to include index in exported table if_exists='replace', #Specify resolution policy if table name already exists )
شكرا لك ونراكم في المرة القادمة؟
الريبو -> https://github.com/DeadPunnk/Mushrooms/tree/main
-
 PHP: الكشف عن الصلصة السرية وراء المواقع الديناميكيةPHP (المعالج المسبق للنص التشعبي) هي لغة برمجة من جانب الخادم تُستخدم على نطاق واسع لإنشاء مواقع ويب ديناميكية وتفاعلية. وهو معروف بتركيبه البسيط، وق...برمجة تم النشر بتاريخ 2024-11-06
PHP: الكشف عن الصلصة السرية وراء المواقع الديناميكيةPHP (المعالج المسبق للنص التشعبي) هي لغة برمجة من جانب الخادم تُستخدم على نطاق واسع لإنشاء مواقع ويب ديناميكية وتفاعلية. وهو معروف بتركيبه البسيط، وق...برمجة تم النشر بتاريخ 2024-11-06 -
أفضل ممارسات التسمية المتغيرة في JavaScript للحصول على تعليمات برمجية نظيفة وقابلة للصيانةمقدمة: تعزيز وضوح الكود وصيانته تعد كتابة تعليمات برمجية نظيفة ومفهومة وقابلة للصيانة أمرًا بالغ الأهمية لأي مطور JavaScript. أحد الجوانب الرئ...برمجة تم النشر بتاريخ 2024-11-06
-
الكشف عن الأعمال الداخلية لـ Spring AOPفي هذا المنشور، سنقوم بإزالة الغموض عن الآليات الداخلية للبرمجة الموجهة نحو الجوانب (AOP) في الربيع. سيكون التركيز على فهم كيفية تحقيق AOP لوظائف ...برمجة تم النشر بتاريخ 2024-11-06
-
ملاحظات جافا سكريبت الإلكترونية: إطلاق العنان لقوة جافا سكريبت الحديثةقدم JavaScript ES6، المعروف رسميًا باسم ECMAScript 2015، تحسينات كبيرة وميزات جديدة غيرت الطريقة التي يكتب بها المطورون JavaScript. فيما يلي أهم 2...برمجة تم النشر بتاريخ 2024-11-06
-
فهم طلبات POST في جافا سكريبتfunction newPlayer(newForm) { fetch("http://localhost:3000/Players", { method: "POST", headers: { 'Content-Type': 'application...برمجة تم النشر بتاريخ 2024-11-06
-
كيفية سلاسة المنحنيات الصاخبة باستخدام تصفية Savitzky-Golay؟منحنيات تجانس للبيانات الصاخبة: استكشاف تصفية Savitzky-Golay في السعي لتحليل مجموعات البيانات، ينشأ التحدي المتمثل في تجانس المنحنيات الصاخبة ...برمجة تم النشر بتاريخ 2024-11-06
-
التحميل الزائد لأساليب varargsالتحميل الزائد على طرق varargs يمكننا زيادة تحميل الطريقة التي تأخذ وسيطة ذات طول متغير. يوضح البرنامج طريقتين لزيادة التحميل على طرق varargs: 1 مجموع...برمجة تم النشر بتاريخ 2024-11-06
-
كيفية الاستفادة من خطافات التفاعل ضمن مكونات الفئة الكلاسيكية؟دمج خطافات React مع مكونات الفئة الكلاسيكية بينما توفر خطافات React بديلاً لتصميم المكونات القائمة على الفصل، فمن الممكن اعتمادها تدريجيًا من خلا...برمجة تم النشر بتاريخ 2024-11-06
-
كيفية إنشاء تطبيق أسرع للصفحة الواحدة (SPA) باستخدام Vite وReactفي عالم تطوير الويب الحديث، أصبحت تطبيقات الصفحة الواحدة (SPA) خيارًا شائعًا لإنشاء مواقع ويب ديناميكية وسريعة التحميل. تعتبر React إحدى مكتبات JavaS...برمجة تم النشر بتاريخ 2024-11-06
-
دليل خطوة بخطوة لتسلسل السلاسل في JavaScriptسلسلة السلسلة في جافا سكريبت هي عملية ضم سلسلتين أو أكثر لتكوين سلسلة واحدة. يستكشف هذا الدليل طرقًا مختلفة لتحقيق ذلك، بما في ذلك استخدام عامل ...برمجة تم النشر بتاريخ 2024-11-06
-
Web UX: إظهار الأخطاء ذات المعنى للمستخدمينقد يكون امتلاك موقع ويب سهل الاستخدام وسهل الاستخدام أمرًا صعبًا في بعض الأحيان لأنه سيسمح لفريق التطوير بأكمله بقضاء المزيد من الوقت في الأشياء التي...برمجة تم النشر بتاريخ 2024-11-06
-
مناور فئة صغيرةالإصدار الرئيسي الجديد من مناور الفئة الصغيرة تمت إعادة هيكلة الكود بالكامل وترميزه لدعم جديد لمعالجة السمات هذا مثال على التلاعب: $classFile...برمجة تم النشر بتاريخ 2024-11-06
-
الإدارة الفعالة لإصدار النموذج في مشاريع التعلم الآليفي مشاريع التعلم الآلي (ML)، أحد المكونات الأكثر أهمية هو إدارة الإصدار. على عكس تطوير البرامج التقليدية، فإن إدارة مشروع تعلم الآلة لا تتضمن كود ...برمجة تم النشر بتاريخ 2024-11-06
-
كيفية تجميع المصفوفات الترابطية حسب قيمة العمود مع الحفاظ على المفاتيح في PHP؟تجميع المصفوفات الترابطية حسب قيمة العمود مع الحفاظ على المفاتيح ضع في اعتبارك مجموعة من المصفوفات الترابطية، يمثل كل منها كيانًا بسمات مثل &q...برمجة تم النشر بتاريخ 2024-11-06
-
كيفية استبعاد تبعيات متعدية محددة في Gradle؟استبعاد التبعيات المتعدية مع Gradle في Gradle، عند استخدام البرنامج الإضافي للتطبيق لإنشاء ملف jar، من الممكن مواجهة تبعيات متعدية قد ترغب في ا...برمجة تم النشر بتاريخ 2024-11-06















دراسة اللغة الصينية
- 1 كيف تقول "المشي" باللغة الصينية؟ 走路 نطق الصينية، 走路 تعلم اللغة الصينية
- 2 كيف تقول "استقل طائرة" بالصينية؟ 坐飞机 نطق الصينية، 坐飞机 تعلم اللغة الصينية
- 3 كيف تقول "استقل القطار" بالصينية؟ 坐火车 نطق الصينية، 坐火车 تعلم اللغة الصينية
- 4 كيف تقول "استقل الحافلة" باللغة الصينية؟ 坐车 نطق الصينية، 坐车 تعلم اللغة الصينية
- 5 كيف أقول القيادة باللغة الصينية؟ 开车 نطق الصينية، 开车 تعلم اللغة الصينية
- 6 كيف تقول السباحة باللغة الصينية؟ 游泳 نطق الصينية، 游泳 تعلم اللغة الصينية
- 7 كيف يمكنك أن تقول ركوب الدراجة باللغة الصينية؟ 骑自行车 نطق الصينية، 骑自行车 تعلم اللغة الصينية
- 8 كيف تقول مرحبا باللغة الصينية؟ # نطق اللغة الصينية، # تعلّم اللغة الصينية
- 9 كيف تقول شكرا باللغة الصينية؟ # نطق اللغة الصينية، # تعلّم اللغة الصينية
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









