
是时候离开了吗?重建的时间到了!制作推特
 浏览:663
浏览:663
The most critical features of a new social network for users fed up with Musk and Twitter, are as follows;
- Import Twitter's archive.zip file
- Easy as possible to sign up
- Similar if not identical user features
Less critical but definitely helpful features of the platform;
- Ethically monetised and moderated
- Make use of AI to help identify problematic content
- Blue tick with the use of Onfido or SMART identity services
In this post, we'll focus on the first feature. Importing Twitter's archive.zip file.
The file
Twitter haven't made your data all that easy to obtain. It's great that they give you access to it (legally, they have to). The format is crap.
It actually comes as a mini web archive and all your data is stuck in JavaScript files. It is more of a web app than convenient storage of data.
When you open up the Your archive.html file you get something like this;
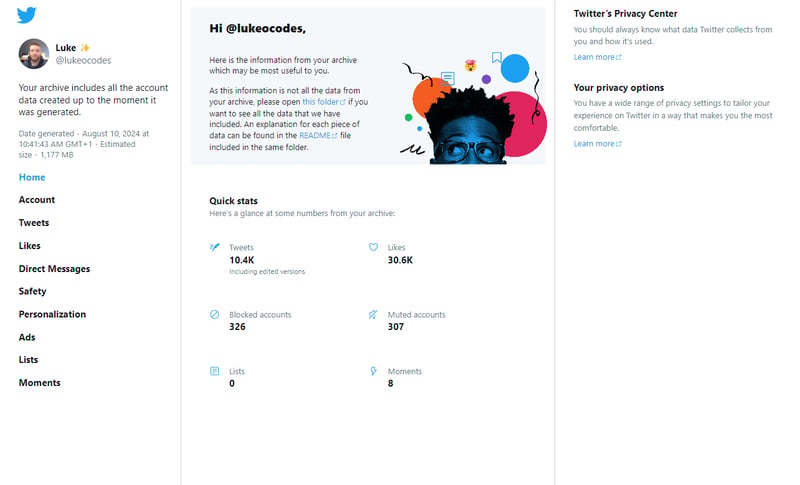
Note: I made the descision pretty early on to build using Next.js for the site, Go and GraphQL for the backend.
So, what do you do when your data isn't structured data?
Well, you parse it.
Creating a basic Go script
Head on over to the official docs on how to get started with Go, and set up your project directory.
We're going to hack this process together. It seems one of the most important features to attract people who feel too attached to TwitterX.
First step is to create a main.go file. In this file we'll GO (hah) and do some STUFF;
- os.Args: This is a slice that holds command-line arguments.
- os.Args[0] is the program's name, and os.Args[1] is the first argument passed to the program.
- Argument Check: The function checks if at least one argument is provided. If not, it prints a message asking for a path.
- run function: This function simply prints the path passed to it, for now.
package main
import (
"fmt"
"os"
)
func run(path string) {
fmt.Println("Path:", path)
}
func main() {
if len(os.Args)
At every step, we'll run the file like so;
go run main.go twitter.zip
If you don't have a Twitter archive export, create a simple manifest.js file and give it the following JavaScript.
window.__THAR_CONFIG = {
"userInfo" : {
"accountId" : "1234567890",
"userName" : "lukeocodes",
"displayName" : "Luke ✨"
},
};
Compress that into your twitter.zip file that we'll use throughout.
Read a Zip file
The next step is to read the contents of the zip file. We want to do this as efficiently as possible, and reduce time data is extracted on the disk.
There are many files in the zip that don't need to be extracted, too.
We'll edit the main.go file;
- Opening the ZIP file: The zip.OpenReader() function is used to open the ZIP file specified by path.
- Iterating through the files: The function loops over each file in the ZIP archive using r.File, which is a slice of zip.File. The Name property of each file is printed.
package main
import (
"archive/zip"
"fmt"
"log"
"os"
)
func run(path string) {
// Open the zip file
r, err := zip.OpenReader(path)
if err != nil {
log.Fatal(err)
}
defer r.Close()
// Iterate through the files in the zip archive
fmt.Println("Files in the zip archive:")
for _, f := range r.File {
fmt.Println(f.Name)
}
}
func main() {
// Example usage
if len(os.Args)
JS only! We're hunting structured data
This archive file is seriously unhelpful. We want to check for just .js files, and only in the /data directory.
- Opening the ZIP file: The ZIP file is opened using zip.OpenReader().
- Checking the /data directory: The program iterates through the files in the ZIP archive. It uses strings.HasPrefix(f.Name, "data/") to check if the file resides in the /data directory.
- Finding .js files: The program also checks if the file has a .js extension using filepath.Ext(f.Name).
- Reading and printing contents: If a .js file is found in the /data directory, the program reads and prints its contents.
package main
import (
"archive/zip"
"fmt"
"io/ioutil"
"log"
"os"
"path/filepath"
"strings"
)
func readFile(file *zip.File) {
// Open the file inside the zip
rc, err := file.Open()
if err != nil {
log.Fatal(err)
}
defer rc.Close()
// Read the contents of the file
contents, err := ioutil.ReadAll(rc) // deprecated? :/
if err != nil {
log.Fatal(err)
}
// Print the contents
fmt.Printf("Contents of %s:\n", file.Name)
fmt.Println(string(contents))
}
func run(path string) {
// Open the zip file
r, err := zip.OpenReader(path)
if err != nil {
log.Fatal(err)
}
defer r.Close()
// Iterate through the files in the zip archive
fmt.Println("JavaScript files in the zip archive:")
for _, f := range r.File {
// Use filepath.Ext to check the file extension
if strings.HasPrefix(f.Name, "data/") && strings.ToLower(filepath.Ext(f.Name)) == ".js" {
readFile(f)
return // Exit after processing the first .js file so we don't end up printing a gazillion lines when testing
}
}
}
func main() {
// Example usage
if len(os.Args)
Parse the JS! We want that data
We've found the structured data. Now we need to parse it. The good news is there are existing packages for using JavaScript inside Go. We'll be using goja.
If you're on this section, familiar with Goja, and you've seen the output of the file, you may see we're going to have errors in our future.
Install goja:
go get github.com/dop251/goja
Now we're going to edit the main.go file to do the following;
- Parsing with goja: The goja.New() function creates a new JavaScript runtime, and vm.RunString(processedContents) runs the processed JavaScript code within that runtime.
- Handle errors in parsing
package main
import (
"archive/zip"
"fmt"
"io/ioutil"
"log"
"os"
"path/filepath"
"strings"
)
func readFile(file *zip.File) {
// Open the file inside the zip
rc, err := file.Open()
if err != nil {
log.Fatal(err)
}
defer rc.Close()
// Read the contents of the file
contents, err := ioutil.ReadAll(rc) // deprecated? :/
if err != nil {
log.Fatal(err)
}
// Parse the JavaScript file using goja
vm := goja.New()
_, err = vm.RunString(contents)
if err != nil {
log.Fatalf("Error parsing JS file: %v", err)
}
fmt.Printf("Parsed JavaScript file: %s\n", file.Name)
}
func run(path string) {
// Open the zip file
r, err := zip.OpenReader(path)
if err != nil {
log.Fatal(err)
}
defer r.Close()
// Iterate through the files in the zip archive
fmt.Println("JavaScript files in the zip archive:")
for _, f := range r.File {
// Use filepath.Ext to check the file extension
if strings.HasPrefix(f.Name, "data/") && strings.ToLower(filepath.Ext(f.Name)) == ".js" {
readFile(f)
return // Exit after processing the first .js file so we don't end up printing a gazillion lines when testing
}
}
}
func main() {
// Example usage
if len(os.Args)
SUPRISE. window is not defined might be a familiar error. Basically goja runs an EMCA runtime. window is browser context and sadly unavailable.
ACTUALLY Parse the JS
I went through a few issues at this point. Including not being able to return data because it's a top level JS file.
Long story short, we need to modify the contents of the files before loading them into the runtime.
Let's modify the main.go file;
- reConfig: A regex that matches any assignment of the form window.someVariable = { and replaces it with var data = {.
- reArray: A regex that matches any assignment of the form window.someObject.someArray = [ and replaces it with var data = [
- Extracting data: Running the script, we use vm.Get("data") to retrieve the value of the data variable from the JavaScript context.
package main
import (
"archive/zip"
"fmt"
"io/ioutil"
"log"
"os"
"path/filepath"
"regexp"
"strings"
"github.com/dop251/goja"
)
func readFile(file *zip.File) {
// Open the file inside the zip
rc, err := file.Open()
if err != nil {
log.Fatal(err)
}
defer rc.Close()
// Read the contents of the file
contents, err := ioutil.ReadAll(rc)
if err != nil {
log.Fatal(err)
}
// Regular expressions to replace specific patterns
reConfig := regexp.MustCompile(`window\.\w \s*=\s*{`)
reArray := regexp.MustCompile(`window\.\w \.\w \.\w \s*=\s*\[`)
// Replace patterns in the content
processedContents := reConfig.ReplaceAllStringFunc(string(contents), func(s string) string {
return "var data = {"
})
processedContents = reArray.ReplaceAllStringFunc(processedContents, func(s string) string {
return "var data = ["
})
// Parse the JavaScript file using goja
vm := goja.New()
_, err = vm.RunString(processedContents)
if err != nil {
log.Fatalf("Error parsing JS file: %v", err)
}
// Retrieve the value of the 'data' variable from the JavaScript context
value := vm.Get("data")
if value == nil {
log.Fatalf("No data variable found in the JS file")
}
// Output the parsed data
fmt.Printf("Processed JavaScript file: %s\n", file.Name)
fmt.Printf("Data extracted: %v\n", value.Export())
}
func run(path string) {
// Open the zip file
r, err := zip.OpenReader(path)
if err != nil {
log.Fatal(err)
}
defer r.Close()
// Iterate through the files in the zip archive
for _, f := range r.File {
// Check if the file is in the /data directory and has a .js extension
if strings.HasPrefix(f.Name, "data/") && strings.ToLower(filepath.Ext(f.Name)) == ".js" {
readFile(f)
return // Exit after processing the first .js file so we don't end up printing a gazillion lines when testing
}
}
}
func main() {
// Example usage
if len(os.Args)
Hurrah. Assuming I didn't muck up the copypaste into this post, you should now see a rather ugly print of the struct data from Go.
JSON would be nice
Edit the main.go file to marshall the JSON output.
- Use value.Export() to get the data from the struct
- Use json.MarshallIndent() for pretty printed JSON (use json.Marshall if you want to minify the output).
package main
import (
"archive/zip"
"encoding/json"
"fmt"
"io/ioutil"
"log"
"os"
"path/filepath"
"regexp"
"strings"
"github.com/dop251/goja"
)
func readFile(file *zip.File) {
// Open the file inside the zip
rc, err := file.Open()
if err != nil {
log.Fatal(err)
}
defer rc.Close()
// Read the contents of the file
contents, err := ioutil.ReadAll(rc) // deprecated :/
if err != nil {
log.Fatal(err)
}
// Regular expressions to replace specific patterns
reConfig := regexp.MustCompile(`window\.\w \s*=\s*{`)
reArray := regexp.MustCompile(`window\.\w \.\w \.\w \s*=\s*\[`)
// Replace patterns in the content
processedContents := reConfig.ReplaceAllStringFunc(string(contents), func(s string) string {
return "var data = {"
})
processedContents = reArray.ReplaceAllStringFunc(processedContents, func(s string) string {
return "var data = ["
})
// Parse the JavaScript file using goja
vm := goja.New()
_, err = vm.RunString(processedContents)
if err != nil {
log.Fatalf("Error parsing JS file: %v", err)
}
// Retrieve the value of the 'data' variable from the JavaScript context
value := vm.Get("data")
if value == nil {
log.Fatalf("No data variable found in the JS file")
}
// Convert the data to a Go-native type
data := value.Export()
// Marshal the Go-native type to JSON
jsonData, err := json.MarshalIndent(data, "", " ")
if err != nil {
log.Fatalf("Error marshalling data to JSON: %v", err)
}
// Output the JSON data
fmt.Println(string(jsonData))
}
func run(zipFilePath string) {
// Open the zip file
r, err := zip.OpenReader(zipFilePath)
if err != nil {
log.Fatal(err)
}
defer r.Close()
// Iterate through the files in the zip archive
for _, f := range r.File {
// Check if the file is in the /data directory and has a .js extension
if strings.HasPrefix(f.Name, "data/") && strings.ToLower(filepath.Ext(f.Name)) == ".js" {
readFile(f)
return // Exit after processing the first .js file
}
}
}
func main() {
// Example usage
if len(os.Args)
That's it!
go run main.go twitter.zip
}
"userInfo": {
"accountId": "1234567890",
"displayName": "Luke ✨",
"userName": "lukeocodes"
}
}
Open source
I'll be open sourcing a lot of this work so that others who want to parse the data from the archive, can store it how they like.
-
 如何在 PHP 中使用 array_push() 处理多维数组?使用 PHP 的 array_push 添加元素到多维数组使用多维数组可能会令人困惑,特别是在尝试添加新元素时。当任务是将存储在 $newdata 中的循环中的数据附加到给定 $md_array 内的子数组“recipe_type”和“cuisine”时,就会出现此问题。要实现此目的,您可以利用ar...编程 发布于2024-11-06
如何在 PHP 中使用 array_push() 处理多维数组?使用 PHP 的 array_push 添加元素到多维数组使用多维数组可能会令人困惑,特别是在尝试添加新元素时。当任务是将存储在 $newdata 中的循环中的数据附加到给定 $md_array 内的子数组“recipe_type”和“cuisine”时,就会出现此问题。要实现此目的,您可以利用ar...编程 发布于2024-11-06 -
Python 第 00 天今天,我开始了我的个人挑战,#100DaysOfCode。为了这个挑战,我选择学习Python,因为我的目标是成为一名数据分析师。 第 2 章: 变量和字符串 我用来学习 Python 的材料是 Eric Matthes 写的一本名为《Python Crash Course》的书。它对学习非常有帮...编程 发布于2024-11-06
-
PDO、准备好的语句或 MySQLi:哪一个最适合您的 PHP 项目?揭秘 PDO、Prepared statements 和 MySQLi在 PHP 数据库交互领域,初学者经常会遇到从遗留 mysql_ 过渡的建议* 函数适用于更现代的选项,如 PDO、准备好的语句或 MySQLi。虽然访问和操作数据库的基本目标仍然存在,但每种技术都提供了独特的优势和细微差别。PD...编程 发布于2024-11-06
-
WordPress 主题开发:终极文件夹结构指南WordPress 是构建网站时的灵活框架。您可以构建任何类型的网站,例如 CMS、电子商务、单一登陆页面等。这里我将讨论 WordPress 项目的结构,以便您可以制作自定义主题。当您为自己或客户制作网站时,流行的主题(例如 divi、Astra、Neve、oceanwp 等)是一些不错的选择。但...编程 发布于2024-11-06
-
工具和资源 [实时文档]CSS https://unsplash.com = 示例图像 https://uifaces.co = 示例用户面部图像 https://extract.pics/ = 从网站提取所有图像 https://color.adobe.com/ = 上传渐变图像并获取十六进制颜色代码 ...编程 发布于2024-11-06
-
如何在 JavaScript 中检查字符串是否包含数组中的任何子字符串?使用 JavaScript 数组查找字符串中的子字符串为了确定字符串是否包含数组中的任何子字符串,JavaScript 提供了灵活的方法.Array Some Methodsome 方法迭代数组,提供回调函数来测试每个元素。要检查子字符串,请使用 indexOf() 方法搜索字符串中的每个数组元素:...编程 发布于2024-11-06
-
Laravel Livewire:它是什么以及如何在您的 Web 应用程序中使用它Livewire 是 Laravel 生态系统中最重要的项目之一,专门针对前端开发。 Livewire v3 最近发布了,让我们来探讨一下 Livewire 是什么,以及什么样的项目适合其架构。 Livewire 的独特之处在于它允许开发“现代”Web 应用程序,而无需使用专用的 JavaScrip...编程 发布于2024-11-06
-
C++中通过空指针调用方法可以不崩溃吗?C 中通过空指针调用方法的意外行为 在提供的代码片段中,通过空指针调用方法,但是令人惊讶的是,该方法调用似乎执行时没有崩溃。这种不寻常的行为提出了一个问题:这是 C 标准允许的还是仅仅是实现优化?解释在于 C 中方法调用的本质。当调用对象的方法时,编译器知道该对象的类型,因此知道要执行的方法的地址。...编程 发布于2024-11-06
-
如何在Python中对列表进行减法?列表相减:计算差值Python 中的列表可以包含各种元素。为了对列表执行数学运算(例如减法),我们采用特定的方法或技术。让我们探讨如何从一个列表中减去另一个列表。使用列表理解进行逐元素减法一种方法是利用列表理解,它会迭代第一个列表并计算差异,同时保留原始顺序:[item for item in x ...编程 发布于2024-11-06
-
如何在 Python 中检查生成器是否为空?检测空生成器初始化在Python中,生成器是一次产生一个值的迭代器。因此,从一开始就确定发电机是否为空可能是一个挑战。与列表或元组不同,生成器没有固有的长度或 isEmpty 方法。解决挑战为了解决这个问题,一种常见的方法是使用辅助函数查看生成器中的第一个值而不消耗它。如果 peek 函数返回 No...编程 发布于2024-11-06
-
## 想从Python高效调用Java?探索 Py4J 作为 JPype 的替代品!从 Python 调用 Java:Py4J 作为 JPype 的替代品从 Python 调用 Java 代码有几个潜在的解决方案。其中一个选项 JPype 可能难以编译,并且由于缺乏最新版本而显得不活跃。然而,另一种解决方案是 Py4J,这是一个简单的库,提供了一个方便的接口,用于从 Python ...编程 发布于2024-11-06
-
小Swoole数据库Small Swoole Db 2.3引入左连接: $selector = (new TableSelector('user')) ->leftJoin('post', 'messageOwner', 'message') ; $selector->where() -&g...编程 发布于2024-11-06
-
如何使用汇编指令优化 __mm_add_epi32_inplace_purego 函数,以在位置总体计数操作中获得更好的性能?使用程序集优化 __mm_add_epi32_inplace_purego此问题旨在优化 __mm_add_epi32_inplace_purego 函数的内部循环,该函数对字节数组执行位置填充计数。目标是通过利用汇编指令来提高性能。内部循环的原始 Go 实现: __mm_add_epi32_...编程 发布于2024-11-06
-
使用 React Router 进行导航 React Js 第一部分 React 应用程序中的路由指南欢迎回到我们的 React 系列!在之前的文章中,我们介绍了组件、状态、道具和事件处理等基本概念。现在,是时候使用 React Router 探索 React 应用程序中的路由了。路由允许您在应用程序内的不同视图或组件之间导航,从而创建无缝的用户体验?. 什么是 React 路由器?...编程 发布于2024-11-06
-
file_get_contents() 可以用于 HTTP 文件上传吗?使用 HTTP Stream Context 通过 file_get_contents() 上传文件使用 cURL 扩展可以无缝地实现通过 Web 表单上传文件。不过,也可以使用 PHP 的 file_get_contents() 函数结合 HTTP 流上下文来执行文件上传。Multipart Co...编程 发布于2024-11-06




![工具和资源 [实时文档]](http://www.luping.net/uploads/20240902/172528812266d5ceba59983.jpg)










学习中文
- 1 走路用中文怎么说?走路中文发音,走路中文学习
- 2 坐飞机用中文怎么说?坐飞机中文发音,坐飞机中文学习
- 3 坐火车用中文怎么说?坐火车中文发音,坐火车中文学习
- 4 坐车用中文怎么说?坐车中文发音,坐车中文学习
- 5 开车用中文怎么说?开车中文发音,开车中文学习
- 6 游泳用中文怎么说?游泳中文发音,游泳中文学习
- 7 骑自行车用中文怎么说?骑自行车中文发音,骑自行车中文学习
- 8 你好用中文怎么说?你好中文发音,你好中文学习
- 9 谢谢用中文怎么说?谢谢中文发音,谢谢中文学习
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









