
ETL:从文本中提取人名
发布于2024-11-07
 浏览:639
浏览:639
假设我们想要抓取chicagomusiccompass.com。
如您所见,它有几张卡片,每张卡片代表一个事件。现在,让我们看看下一篇:
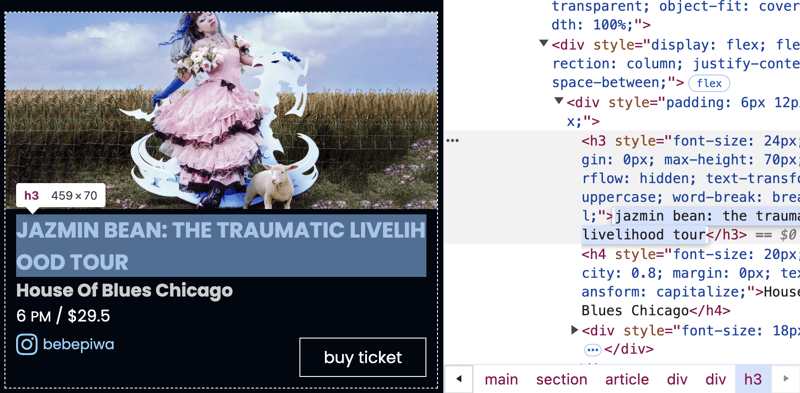
注意事件名称是:
jazmin bean: the traumatic livelihood tour
所以现在的问题是:我们如何从文本中提取艺术家的名字?
作为一个人,我可以“轻松地”看出 jazmin bean 是艺术家——只需查看他们的 wiki 页面即可。但是编写代码来提取该名称可能会很棘手。
我们可以想,“嘿,: 之前的任何内容都应该是艺术家的名字”,这看起来很聪明,对吧?它适用于这种情况,但是这个怎么样:
happy hour on the patio: kathryn & chris
这里,顺序颠倒了。我们可以不断添加逻辑来处理不同的情况,但很快我们就会得到大量脆弱的规则,并且可能无法涵盖所有内容。
这就是命名实体识别(NER)模型派上用场的地方。它们是开源的,可以帮助我们从文本中提取名称。它不会捕获所有案例,但大多数时候,他们会给我们提供我们需要的信息。
通过这种方法,提取变得更加容易。我选择 Python 是因为 Python 机器学习社区是无与伦比的。
from gliner import GLiNER
model = GLiNER.from_pretrained("urchade/gliner_base")
text = "jazmin bean: the traumatic livelihood tour"
labels = ["person", "bands", "projects"]
entities = model.predict_entities(text, labels)
for entity in entities:
print(entity["text"], "=>", entity["label"])
生成输出:
jazmin bean => person
现在,让我们看一下另一种情况:
happy hour on the patio: kathryn & chris
输出:
kathryn => person chris => person
来源-GLiNER
太棒了,对吧?不再需要繁琐的逻辑来提取名称,只需使用模型即可。当然,它不会涵盖所有可能的情况,但对于我的项目来说,这种灵活性就很好了。如果您需要更高的准确性,您可以随时:
- 尝试不同的模型
- 对现有模型做出贡献
- 分叉项目并调整它以满足您的需求
结论
作为软件开发人员,强烈建议随时更新机器学习领域的工具。并非所有问题都可以通过简单的编程和逻辑来解决 - 使用模型和统计数据可以更好地解决一些挑战。
版本声明
本文转载于:https://dev.to/garciadiazjaime/etl-extracting-a-persons-name-from-text-ahl?1如有侵犯,请联系[email protected]删除
最新教程
更多>
-
 如何在Java字符串中有效替换多个子字符串?在java 中有效地替换多个substring,需要在需要替换一个字符串中的多个substring的情况下,很容易求助于重复应用字符串的刺激力量。 However, this can be inefficient for large strings or when working with nu...编程 发布于2025-04-12
如何在Java字符串中有效替换多个子字符串?在java 中有效地替换多个substring,需要在需要替换一个字符串中的多个substring的情况下,很容易求助于重复应用字符串的刺激力量。 However, this can be inefficient for large strings or when working with nu...编程 发布于2025-04-12 -
如何使用不同数量列的联合数据库表?合并列数不同的表 当尝试合并列数不同的数据库表时,可能会遇到挑战。一种直接的方法是在列数较少的表中,为缺失的列追加空值。 例如,考虑两个表,表 A 和表 B,其中表 A 的列数多于表 B。为了合并这些表,同时处理表 B 中缺失的列,请按照以下步骤操作: 确定表 B 中缺失的列,并将它们添加到表的末...编程 发布于2025-04-12
-
如何同步迭代并从PHP中的两个等级阵列打印值?同步的迭代和打印值来自相同大小的两个数组使用两个数组相等大小的selectbox时,一个包含country代码的数组,另一个包含乡村代码,另一个包含其相应名称的数组,可能会因不当提供了exply for for for the uncore for the forsion for for ytry...编程 发布于2025-04-12
-
为什么PHP的DateTime :: Modify('+1个月')会产生意外的结果?使用php dateTime修改月份:发现预期的行为在使用PHP的DateTime类时,添加或减去几个月可能并不总是会产生预期的结果。正如文档所警告的那样,“当心”这些操作的“不像看起来那样直观。 ; $ date->修改('1个月'); //前进1个月 echo $ date->...编程 发布于2025-04-12
-
如何修复\“常规错误:2006 MySQL Server在插入数据时已经消失\”?How to Resolve "General error: 2006 MySQL server has gone away" While Inserting RecordsIntroduction:Inserting data into a MySQL database can...编程 发布于2025-04-12
-
如何在Java中执行命令提示命令,包括目录更改,包括目录更改?在java 通过Java通过Java运行命令命令可能很具有挑战性。尽管您可能会找到打开命令提示符的代码段,但他们通常缺乏更改目录并执行其他命令的能力。 solution:使用Java使用Java,使用processBuilder。这种方法允许您:启动一个过程,然后将其标准错误重定向到其标准输出。...编程 发布于2025-04-12
-
Python读取CSV文件UnicodeDecodeError终极解决方法在试图使用已内置的CSV模块读取Python中时,CSV文件中的Unicode Decode Decode Decode Decode decode Error读取,您可能会遇到错误的错误:无法解码字节 在位置2-3中:截断\ uxxxxxxxx逃脱当CSV文件包含特殊字符或Unicode的路径逃...编程 发布于2025-04-12
-
在GO中构造SQL查询时,如何安全地加入文本和值?在go中构造文本sql查询时,在go sql queries 中,在使用conting and contement和contement consem per时,尤其是在使用integer per当per当per时,per per per当per. [&&&&&&&&&&&&&&&&默元组方法在...编程 发布于2025-04-12
-
如何从PHP中的数组中提取随机元素?从阵列中的随机选择,可以轻松从数组中获取随机项目。考虑以下数组:; 从此数组中检索一个随机项目,利用array_rand( array_rand()函数从数组返回一个随机键。通过将$项目数组索引使用此键,我们可以从数组中访问一个随机元素。这种方法为选择随机项目提供了一种直接且可靠的方法。编程 发布于2025-04-12
-
如何在无序集合中为元组实现通用哈希功能?在未订购的集合中的元素要纠正此问题,一种方法是手动为特定元组类型定义哈希函数,例如: template template template 。 struct std :: hash { size_t operator()(std :: tuple const&tuple)const {...编程 发布于2025-04-12
-
如何干净地删除匿名JavaScript事件处理程序?删除匿名事件侦听器将匿名事件侦听器添加到元素中会提供灵活性和简单性,但是当要删除它们时,可以构成挑战,而无需替换元素本身就可以替换一个问题。 element? element.addeventlistener(event,function(){/在这里工作/},false); 要解决此问题,请考虑...编程 发布于2025-04-12
-
为什么不使用CSS`content'属性显示图像?在Firefox extemers属性为某些图像很大,&& && && &&华倍华倍[华氏华倍华氏度]很少见,却是某些浏览属性很少,尤其是特定于Firefox的某些浏览器未能在使用内容属性引用时未能显示图像的情况。这可以在提供的CSS类中看到:。googlepic { 内容:url(&#...编程 发布于2025-04-12
-
如何为PostgreSQL中的每个唯一标识符有效地检索最后一行?postgresql:为每个唯一标识符提取最后一行,在Postgresql中,您可能需要遇到与在数据库中的每个不同标识相关的信息中提取信息的情况。考虑以下数据:[ 1 2014-02-01 kjkj 在数据集中的每个唯一ID中检索最后一行的信息,您可以在操作员上使用Postgres的有效效率: ...编程 发布于2025-04-12
-
为什么尽管有效代码,为什么在PHP中捕获输入?在php ;?>" method="post">The intention is to capture the input from the text box and display it when the submit button is clicked.但是,输出...编程 发布于2025-04-12
-
如何使用“ JSON”软件包解析JSON阵列?parsing JSON与JSON软件包 QUALDALS:考虑以下go代码:字符串 } func main(){ datajson:=`[“ 1”,“ 2”,“ 3”]`` arr:= jsontype {} 摘要:= = json.unmarshal([] byte(...编程 发布于2025-04-12















学习中文
- 1 走路用中文怎么说?走路中文发音,走路中文学习
- 2 坐飞机用中文怎么说?坐飞机中文发音,坐飞机中文学习
- 3 坐火车用中文怎么说?坐火车中文发音,坐火车中文学习
- 4 坐车用中文怎么说?坐车中文发音,坐车中文学习
- 5 开车用中文怎么说?开车中文发音,开车中文学习
- 6 游泳用中文怎么说?游泳中文发音,游泳中文学习
- 7 骑自行车用中文怎么说?骑自行车中文发音,骑自行车中文学习
- 8 你好用中文怎么说?你好中文发音,你好中文学习
- 9 谢谢用中文怎么说?谢谢中文发音,谢谢中文学习
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









