
Go 数组如何工作以及如何使用 For-Range
 浏览:976
浏览:976
这是帖子的摘录;完整的帖子可以在这里找到:Go 数组如何工作并使用 For-Range 进行技巧。
经典的 Golang 数组和切片非常简单。数组是固定大小的,而切片是动态的。但我必须告诉你,Go 表面上看起来很简单,但它背后却发生了很多事情。
一如既往,我们将从基础知识开始,然后进行更深入的研究。别担心,当你从不同的角度观察数组时,它们会变得非常有趣。
我们将在下一部分中介绍切片,一旦准备好我就会把它放在这里。
什么是数组?
Go 中的数组与其他编程语言中的数组非常相似。它们有固定的大小,并将相同类型的元素存储在连续的内存位置中。
这意味着Go可以快速访问每个元素,因为它们的地址是根据数组的起始地址和元素的索引计算的。
func main() {
arr := [5]byte{0, 1, 2, 3, 4}
println("arr", &arr)
for i := range arr {
println(i, &arr[i])
}
}
// Output:
// arr 0x1400005072b
// 0 0x1400005072b
// 1 0x1400005072c
// 2 0x1400005072d
// 3 0x1400005072e
// 4 0x1400005072f
这里有几件事需要注意:
- 数组arr的地址与第一个元素的地址相同。
- 每个元素的地址彼此相距1字节,因为我们的元素类型是byte。

仔细看图。
我们的堆栈是从较高的地址向下增长到较低的地址,对吧?这张图准确地展示了数组在栈中的样子,从 arr[4] 到 arr[0].
那么,这是否意味着我们可以通过知道第一个元素(或数组)的地址和元素的大小来访问数组的任何元素?让我们用 int 数组和不安全的包来尝试一下:
func main() {
a := [3]int{99, 100, 101}
p := unsafe.Pointer(&a[0])
a1 := unsafe.Pointer(uintptr(p) 8)
a2 := unsafe.Pointer(uintptr(p) 16)
fmt.Println(*(*int)(p))
fmt.Println(*(*int)(a1))
fmt.Println(*(*int)(a2))
}
// Output:
// 99
// 100
// 101
好吧,我们获取指向第一个元素的指针,然后通过将 int 大小的倍数相加来计算指向下一个元素的指针,在 64 位体系结构中,int 大小为 8 个字节。然后我们使用这些指针来访问并将它们转换回 int 值。
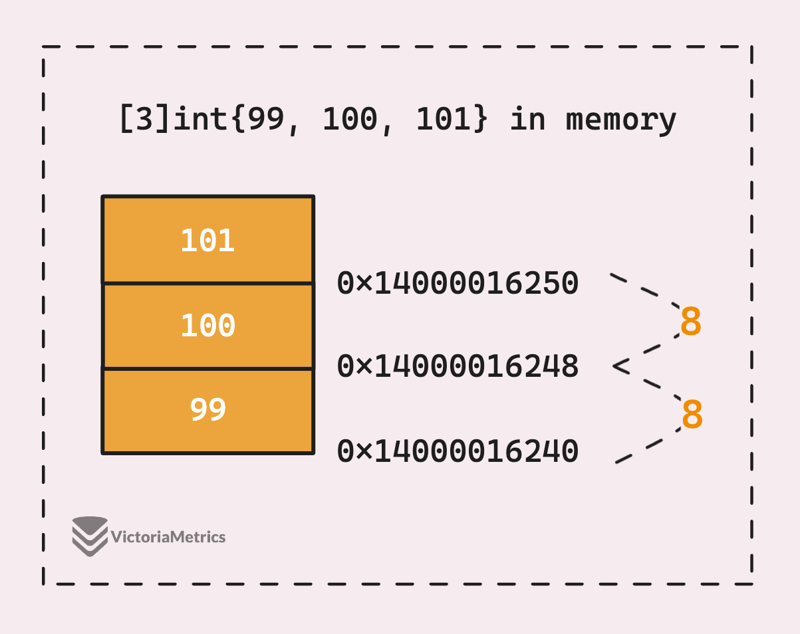
该示例只是为了教育目的而使用 unsafe 包直接访问内存。在不了解后果的情况下,不要在生产中这样做。
现在,类型 T 的数组本身并不是类型,但具有 特定大小和类型 T 的数组被视为类型。这就是我的意思:
func main() {
a := [5]byte{}
b := [4]byte{}
fmt.Printf("%T\n", a) // [5]uint8
fmt.Printf("%T\n", b) // [4]uint8
// cannot use b (variable of type [4]byte) as [5]byte value in assignment
a = b
}
尽管 a 和 b 都是字节数组,Go 编译器将它们视为完全不同的类型,%T 格式清楚地表明了这一点。
Go编译器内部是这样看待它的(src/cmd/compile/internal/types2/array.go):
// An Array represents an array type.
type Array struct {
len int64
elem Type
}
// NewArray returns a new array type for the given element type and length.
// A negative length indicates an unknown length.
func NewArray(elem Type, len int64) *Array { return &Array{len: len, elem: elem} }
数组的长度在类型本身中“编码”,因此编译器从其类型知道数组的长度。尝试将一种大小的数组分配给另一种大小的数组或比较它们,将导致类型不匹配错误。
数组文字
Go中初始化数组的方法有很多种,有些在实际项目中可能很少用到:
var arr1 [10]int // [0 0 0 0 0 0 0 0 0 0]
// With value, infer-length
arr2 := [...]int{1, 2, 3, 4, 5} // [1 2 3 4 5]
// With index, infer-length
arr3 := [...]int{11: 3} // [0 0 0 0 0 0 0 0 0 0 0 3]
// Combined index and value
arr4 := [5]int{1, 4: 5} // [1 0 0 0 5]
arr5 := [5]int{2: 3, 4, 4: 5} // [0 0 3 4 5]
我们上面所做的(除了第一个)是定义和初始化它们的值,这称为“复合文字”。该术语也用于切片、映射和结构。
现在,有一件有趣的事情:当我们创建一个少于 4 个元素的数组时,Go 会生成指令将值逐个放入数组中。
所以当我们执行 arr := [3]int{1, 2, 3, 4} 时,实际发生的是:
arr := [4]int{}
arr[0] = 1
arr[1] = 2
arr[2] = 3
arr[3] = 4
这种策略称为本地代码初始化。这意味着初始化代码是在特定函数的范围内生成和执行的,而不是全局或静态初始化代码的一部分。
当你阅读下面的另一个初始化策略时,它会变得更清楚,其中值不是像那样一个一个地放入数组中。
“超过 4 个元素的数组怎么样?”
编译器在二进制文件中创建数组的静态表示,这称为“静态初始化”策略。
这意味着数组元素的值存储在二进制文件的只读部分中。该静态数据是在编译时创建的,因此这些值直接嵌入到二进制文件中。如果你好奇 [5]int{1,2,3,4,5} 在 Go 汇编中的样子:
main..stmp_1 SRODATA static size=40
0x0000 01 00 00 00 00 00 00 00 02 00 00 00 00 00 00 00 ................
0x0010 03 00 00 00 00 00 00 00 04 00 00 00 00 00 00 00 ................
0x0020 05 00 00 00 00 00 00 00 ........
要看到数组的值并不容易,但我们还是可以从中得到一些关键信息。
我们的数据存储在stmp_1中,它是只读静态数据,大小为40字节(每个元素8字节),并且该数据的地址被硬编码在二进制中。
编译器生成代码来引用此静态数据。当我们的应用程序运行时,它可以直接使用这个预先初始化的数据,而不需要额外的代码来设置数组。
const readonly = [5]int{1, 2, 3, 4, 5}
arr := readonly
“如果数组有 5 个元素,但只初始化了 3 个元素呢?”
好问题,这个字面量 [5]int{1,2,3} 属于第一类,Go 将值逐个放入数组中。
在讨论定义和初始化数组时,我们应该提到并非每个数组都在堆栈上分配。如果它太大,它就会被移动到堆中。
但是您可能会问,“太大”有多大。
从 Go 1.23 开始,如果变量(而不仅仅是数组)的大小超过常量值 MaxStackVarSize(当前为 10 MB),它将被认为对于堆栈分配来说太大,并将逃逸到堆。
func main() {
a := [10 * 1024 * 1024]byte{}
println(&a)
b := [10*1024*1024 1]byte{}
println(&b)
}
在这种情况下,b 将移动到堆,而 a 不会。
数组运算
数组的长度在类型本身中进行编码。即使数组没有 cap 属性,我们仍然可以获得它:
func main() {
a := [5]int{1, 2, 3}
println(len(a)) // 5
println(cap(a)) // 5
}
毫无疑问,容量等于长度,但最重要的是我们在编译时就知道这一点,对吧?
因此 len(a) 对编译器没有意义,因为它不是运行时属性,Go 编译器在编译时就知道该值。
...
这是帖子的摘录;完整的帖子可以在这里找到:Go 数组如何工作并使用 For-Range 进行技巧。
-
 如何修复 Matplotlib 中的“无显示名称且无 $DISPLAY 环境变量”错误?"_tkinter.TclError: no display name and no $DISPLAY 环境变量"使用 Matplotlib 运行 Python 脚本时通常会发生此错误在没有图形显示的服务器上。 Matplotlib 依赖后端来渲染绘图,默认情况下,它选择 Xwi...编程 发布于2024-11-05
如何修复 Matplotlib 中的“无显示名称且无 $DISPLAY 环境变量”错误?"_tkinter.TclError: no display name and no $DISPLAY 环境变量"使用 Matplotlib 运行 Python 脚本时通常会发生此错误在没有图形显示的服务器上。 Matplotlib 依赖后端来渲染绘图,默认情况下,它选择 Xwi...编程 发布于2024-11-05 -
您的第一个使用 Node.js 的后端应用程序您是否正在学习 Web 开发并对如何启动 Node.js 项目感到困惑?别担心,我有你!我将指导您只需 5 个步骤即可使用 Node.js 和 Express.js 创建您的第一个后端。 ️5个关键步骤: 第 1 步:设置项目 第 2 步:整理文件夹 第3步:创建server.js文...编程 发布于2024-11-05
-
跨域场景下CORS何时使用预检请求?CORS:了解跨域请求的“预检”请求跨域资源共享 (CORS) 在制作 HTTP 时提出了挑战跨域请求。为了解决这些限制,引入了预检请求作为解决方法。预检请求说明预检请求是先于实际请求(例如 GET 或 POST)的 OPTIONS 请求)并用于与服务器协商请求的权限。这些请求包括两个附加标头:Ac...编程 发布于2024-11-05
-
如何使用 PHP 的 glob() 函数按扩展名过滤文件?在 PHP 中按扩展名过滤文件使用目录时,通常需要根据扩展名检索特定文件。 PHP 提供了一种使用 glob() 函数来完成此任务的有效方法。要按扩展名过滤文件,请使用语法:$files = glob('/path/to/directory/*.extension');例如,要检索目录 /path/...编程 发布于2024-11-05
-
理解 JavaScript 中的 Promise 和 Promise Chaining什么是承诺? JavaScript 中的 Promise 就像你对未来做某事的“承诺”。它是一个对象,表示异步任务的最终完成(或失败)及其结果值。简而言之,Promise 充当尚不可用但将来可用的值的占位符。 承诺国家 Promise 可以存在于以下三种状态之一: ...编程 发布于2024-11-05
-
Pip 的可编辑模式何时对本地 Python 包开发有用?使用 Pip 在 Python 中利用可编辑模式进行本地包开发在 Python 的包管理生态系统中,Pip 拥有“-e”(或'--editable') 特定场景的选项。什么时候使用这个选项比较有利?答案在于可编辑模式的实现,官方文档中有详细说明:“从本地以可编辑模式安装项目(即 se...编程 发布于2024-11-05
-
当您在浏览器中输入 URL 时会发生什么?您是否想知道当您在浏览器中输入 URL 并按 Enter 键时幕后会发生什么?该过程比您想象的更加复杂,涉及多个步骤,这些步骤无缝地协同工作以提供您请求的网页。在本文中,我们将探讨从输入 URL 到查看完全加载的网页的整个过程,阐明使这一切成为可能的技术和协议。 第 1 步:输入 U...编程 发布于2024-11-05
-
如何有效管理大量小HashMap对象的“OutOfMemoryError:超出GC开销限制”?OutOfMemoryError: Handling Garbage Collection Overhead在Java中,当过多时会出现“java.lang.OutOfMemoryError: GC Overhead limit allowed”错误根据 Sun 的文档,时间花费在垃圾收集上。要解决...编程 发布于2024-11-05
-
为什么在 Python 列表初始化中使用 [[]] * n 时列表会链接在一起?使用 [[]] * n 进行列表初始化时的列表链接问题使用 [[]] 初始化列表列表时 n,程序员经常会遇到一个意想不到的问题,即列表似乎链接在一起。出现这种情况是因为 [x]n 语法创建对同一基础列表对象的多个引用,而不是创建不同的列表实例。为了说明该问题,请考虑以下代码:x = [[]] * ...编程 发布于2024-11-05
-
Python 变得简单:从初学者到高级 |博客Python Course Code Examples This is a Documentation of the python code i used and created , for learning python. Its easy to understand and L...编程 发布于2024-11-05
-
简化 TypeScript 中的类型缩小和防护Introduction to Narrowing Concept Typescript documentation explains this topic really well. I am not going to copy and paste the same descrip...编程 发布于2024-11-05
-
何时应该使用 session_unset() 而不是 session_destroy() ,反之亦然?理解 PHP 中 session_unset() 和 session_destroy() 的区别PHP 函数 session_unset() 和 session_destroy() 有不同的用途管理会话数据。尽管它们在清除会话变量方面有明显相似之处,但它们具有不同的效果。session_unset(...编程 发布于2024-11-05
-
如何选择在 C++ 中解析 INI 文件的最佳方法?在 C 中解析 INI 文件:各种方法指南在 C 中处理初始化 (INI) 文件时,开发人员经常遇到有效解析这些文件以提取所需信息的挑战。本文探讨了用 C 解析 INI 文件的不同方法,讨论了它们的优点和注意事项。本机 Windows API 函数一种方法是利用 Windows API 函数INI ...编程 发布于2024-11-05










![为什么在 Python 列表初始化中使用 [[]] * n 时列表会链接在一起?](http://www.luping.net/uploads/20241021/17294774536715bb4d76111.jpg)




学习中文
- 1 走路用中文怎么说?走路中文发音,走路中文学习
- 2 坐飞机用中文怎么说?坐飞机中文发音,坐飞机中文学习
- 3 坐火车用中文怎么说?坐火车中文发音,坐火车中文学习
- 4 坐车用中文怎么说?坐车中文发音,坐车中文学习
- 5 开车用中文怎么说?开车中文发音,开车中文学习
- 6 游泳用中文怎么说?游泳中文发音,游泳中文学习
- 7 骑自行车用中文怎么说?骑自行车中文发音,骑自行车中文学习
- 8 你好用中文怎么说?你好中文发音,你好中文学习
- 9 谢谢用中文怎么说?谢谢中文发音,谢谢中文学习
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









