
5 个最佳开源 AI 图像生成器
 浏览:111
浏览:111
互联网上有数十个免费和开源的人工智能文本到图像生成器,专门用于特定类型的图像。因此,我们筛选了一堆,找到了您现在可以尝试的最佳开源人工智能文本到图像生成器。
1 Craiyon
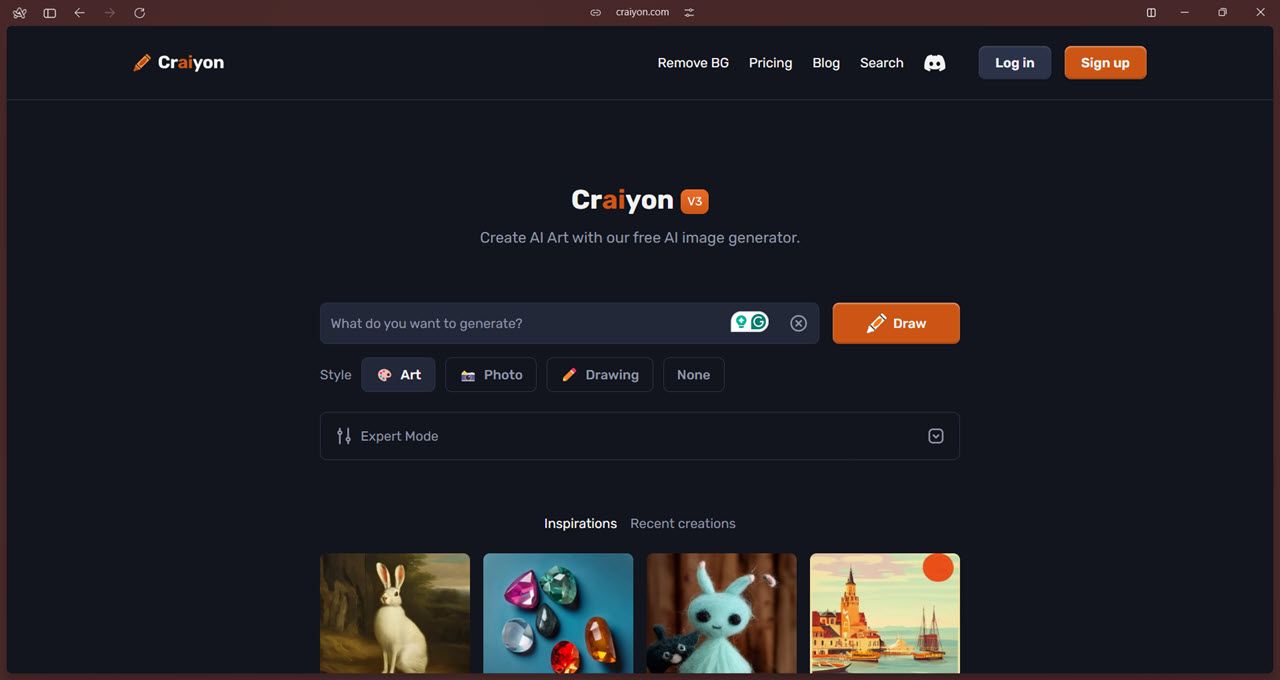
Craiyon 是最容易访问的开源 AI 图像生成器之一。它基于 DALL-E Mini,虽然您可以克隆 Github 存储库并将模型本地安装在计算机上,但 Craiyon 似乎已经放弃了这种方法,转而采用其网站。
官方 Github 存储库自 2022 年 6 月以来一直没有更新,但最新模型仍然可以在 Craiyon 官方网站上免费获得。也没有 Android 或 iOS 应用程序。
在功能方面,您将看到 AI 图像生成器所期望的所有常用选项。输入提示并获取图像后,您可以使用高档功能来获取更高分辨率的副本。有三种风格可供选择:艺术、照片和绘画。如果您希望模型来决定,您也可以选择“无”选项。
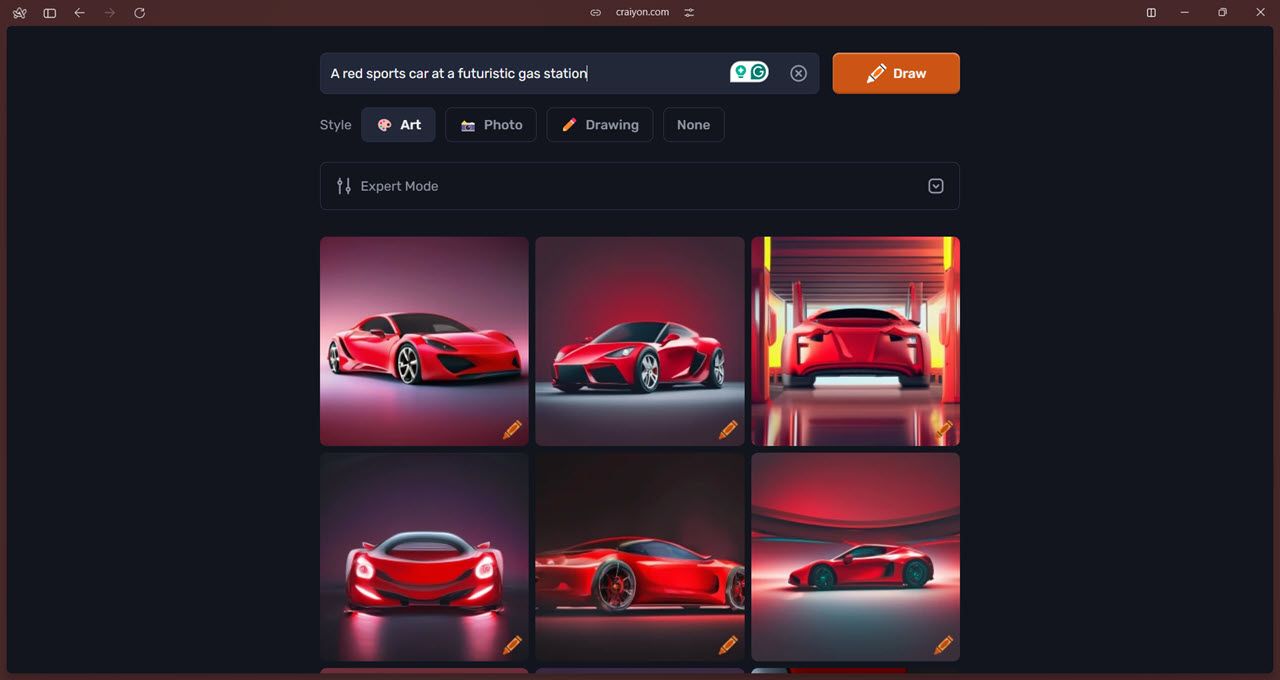
此外,“专家模式”允许您包含否定词,告诉模型避免特定项目。还有一个提示预测功能,它使用 ChatGPT 帮助用户编写尽可能最好、最详细的提示。最后,人工智能驱动的删除背景功能可以帮助您节省从图像中裁剪背景的时间和精力。
这就是 Craiyon 所做的一切。它不是最复杂的人工智能图像生成模型,但如果您不想要详细或真实的东西,它作为基本模型效果很好。
该模型可以免费使用,但免费用户在一分钟内一次只能使用九张免费图像。您可以订阅他们的支持者或专业级别(价格分别为每月 5 美元和 20 美元,按年计费),以获得无广告或水印、更快的生成速度以及将生成的图像保密的选项。自定义订阅层还允许自定义模型、集成、专用支持和专用服务器。
2 Stable Diffusion 1.5
Stable Diffusion 也许是最流行的开源文本到图像生成模型之一。它还为其他模型提供动力,包括下面提到的三个图像生成器。它于 2022 年发布,此后已有多次实现。
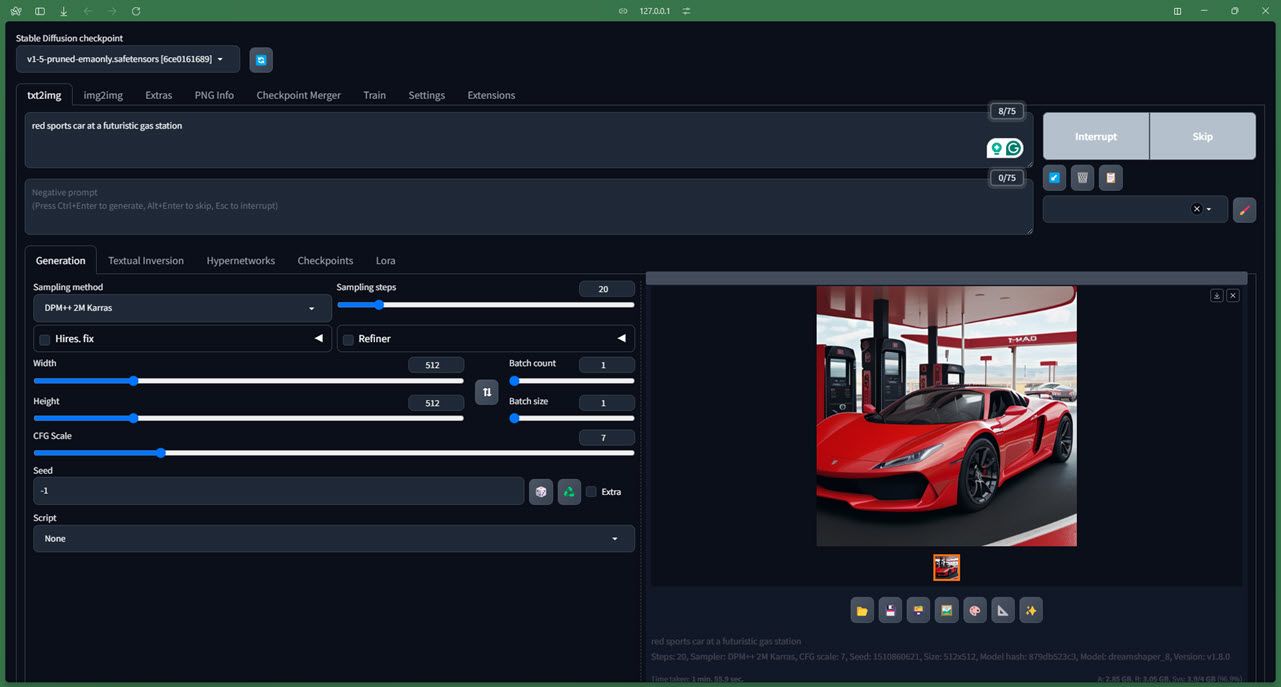
我不会向您介绍该模型如何工作的过多技术细节(您可以查看他们的官方 Github 存储库),但该模型即使对于完全的初学者来说也很容易安装并且运行良好只要您拥有至少 4GB 内存的专用 GPU。您还可以在线访问 Stable Diffusion,如果您想在 Mac 上运行 Stable Diffusion,我们可以为您提供帮助。
有几个检查点(考虑它们的版本)可用于稳定扩散。虽然我们测试了 1.5 版,但 2.1 版也在积极开发中,并且更加精确。

运行模型也相当容易。我们使用 AUTOMATIC1111 Stable Diffusion Web 用户界面对其进行了测试,所有控件和参数都运行良好。由于模型训练所用的 LAION-5B 数据库,它也完全符合 NSFW 标准(请注意,尽管它并不完美)。虽然生成时间本身会根据您的硬件而有所不同,但即使有基本的提示,您也可以期望您的图像是详细且真实的。
3 DreamShaper
DreamShaper 是基于稳定扩散的图像生成模型。它的目的是作为 MidJourney 的开源替代品,并专注于生成图像中的真实感,尽管它可以通过一些调整来处理动画和绘画风格。
该模型比稳定扩散更强大,允许用户对最终输出有更大的自由度,从闪电改进到更宽松的 NSFW 限制。运行模型也很容易,可以在线下载预训练版本以供本地访问,并且可以通过许多网站(包括 Sinkin.ai、RandomSeed 和 Mage.space)(需要基本订阅)来运行模型GPU 加速。
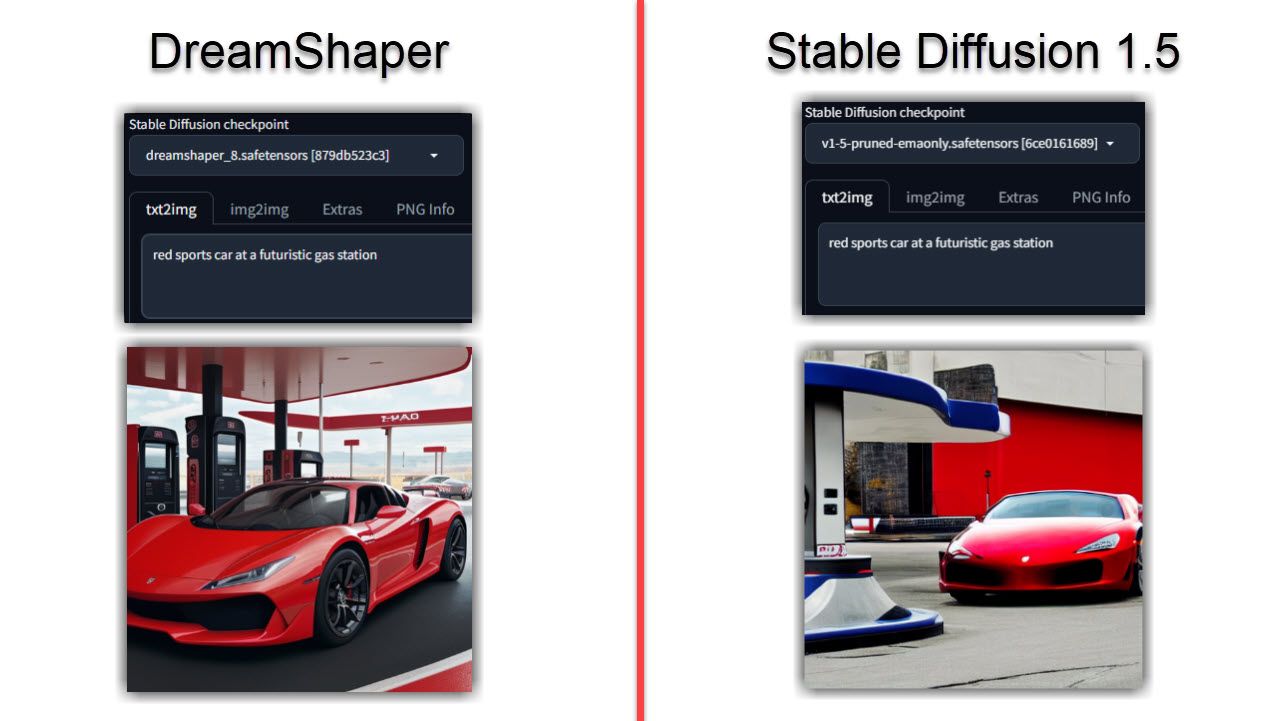
正如您现在可能猜到的那样,与稳定扩散相比,DreamShaper 生成的图像往往看起来更真实。即使您在两个模型上运行相同的提示,DreamShaper 模型也可能会更加真实、详细且光线更好。
对于肖像或人物来说尤其如此,我发现与相同的提示相比,稳定扩散缺乏这一点。如果您的图像变得过于真实,可以使用以下四种方法来识别人工智能生成的图像。
您也不需要庞大的 PC 来运行该模型。我的 GTX 1650Ti 配备 4GB VRAM 完美运行该模型。生成时间有点长,但这似乎并不影响实际输出。也就是说,您可能需要具有更多 VRAM 的 GPU 才能运行基于稳定扩散 XL 模型的 DreamShaper XL。
4 InvokeAI
Invoke AI是另一种基于Stable Diffusion的AI图像生成模型,有基于Stable Diffusion XL的XL版本。它还拥有自己的网络和命令行用户界面,这意味着您不必使用稳定扩散网络用户界面之类的东西。
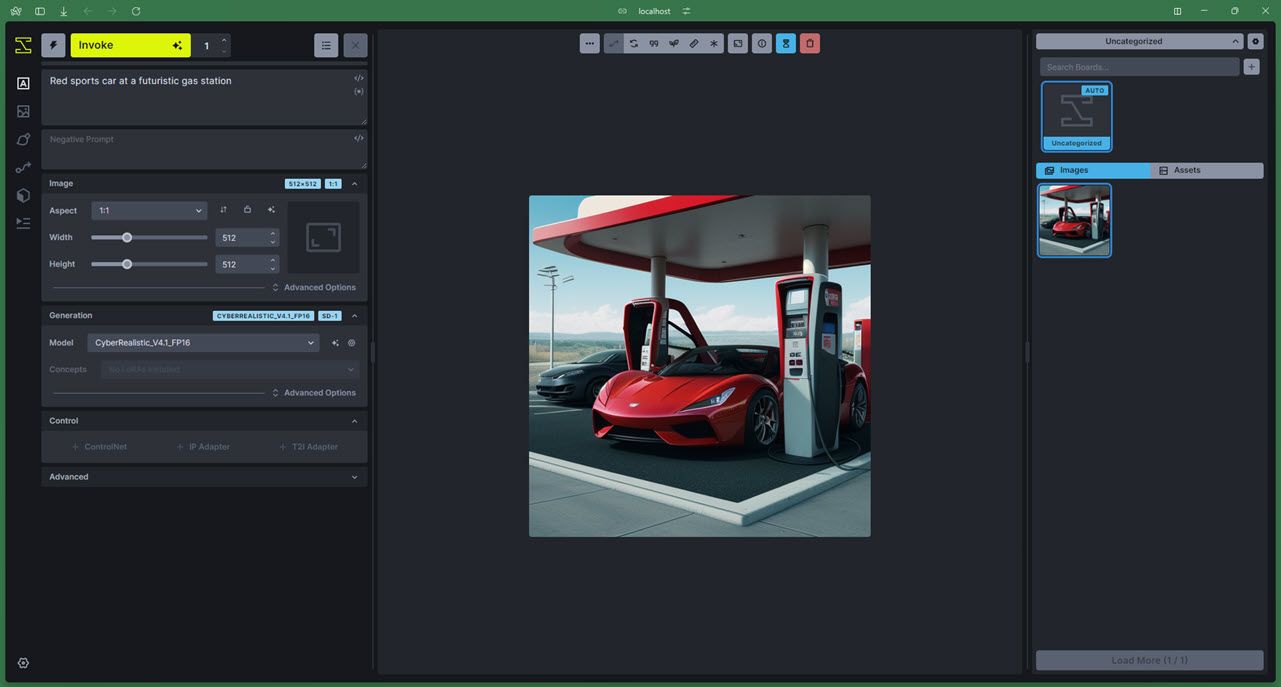
该模型侧重于让用户根据其知识产权通过定制工作流程创建视觉效果。 InvokeAI 是用于训练自定义模型和处理知识产权的最佳开源 AI 图像生成模型之一。
其官方 Github 存储库列出了两种安装方法:通过 InvokeAI 的安装程序安装,或者如果您熟悉终端和 Python 并且需要对随模型安装的包进行更多控制,则使用 PyPI 进行安装。
然而,额外的控制确实带来了一些限制,最明显的是更严格的硬件要求。 InvokeAI 建议使用至少具有 4GB 内存的专用 GPU,建议使用 6 到 8GB 来运行 XL 变体。 VRAM 要求适用于 AMD 和 Nvidia GPU。您还需要至少 12GB 的 RAM 和 12GB 的可用磁盘空间用于模型、其依赖项和 Python。

虽然文档不推荐 Nvidia 的 GTX 10 系列和 16 系列 GPU,因为它们缺乏视频内存,但提供的安装程序确实运行得很好。虽然您的情况可能会有所不同,但如果您使用的是低端 GPU,则需要等待更长的时间才能看到提示转换为图像。最后,如果您使用的是 Windows,则只能使用 Nvidia GPU,因为目前不支持 AMD GPU。
对于图像生成部分,模型更倾向于艺术风格而不是照片写实主义。当然,您可以在数据集上训练模型,并让它生成更接近您想要的图像,即使这涉及逼真的图像,特别是如果您在产品设计、建筑或零售空间工作。然而,需要记住的一件重要的事情是,InvokeAI 主要是一个图像生成引擎,这意味着您可能必须使用自己的模型才能获得最佳结果(可以通过 Web 界面中提供的模型管理器轻松找到)作为默认值模型与稳定扩散本身非常相似。
5 Openjourney
Openjourney 是一个免费的开源 AI 图像生成模型,同样基于稳定扩散。如果您想知道为什么该模型被称为 Openjourney,那是因为它是在 Midjourney 图像上进行训练的,并且可以在生成的图像中模仿其风格。
PromptHero 是 Openjourney 背后的公司,可让您与其他模型一起测试该模型,包括稳定扩散(版本 1.5 和 2)、DreamShaper 和 Realistic Vision。注册时,您将获得 25 个免费积分(每生成一张图像就获得一个积分),之后您必须订阅他们的 Pro 订阅级别,每月费用为 9 美元,每月可以使用 300 个积分以及其他独家功能。

但是,如果您想在本地免费运行它,您可以从 HuggingFace 下载模型文件并使用 Stable Diffusion Web UI 运行它。 Openjourney 也是 HuggingFace 上下载量第二高的 AI 图像生成模型,仅次于 Stable Diffusion。
Openjourney 没有列出在其网站上本地运行模型的任何具体硬件要求,但您可以预期与 Stable Diffusion 类似的硬件要求。这意味着您的计算机上需要具有 4GB VRAM、16GB RAM 和大约 12 到 15GB 可用空间的专用 GPU 来保存模型及其依赖项。

除非另有说明,Openjourney 生成的图像往往在照片写实主义和艺术之间取得平衡。如果您正在寻找一款全能型号,并且喜欢 Midjourney 的外观和感觉,而无需付费订阅,那么 Openjourney 是最好的选择之一。
-
 Excel SUMPRODUCT函数详解 - 数据分析学院Excel的SumProduct函数:数据分析PowerHouse 解锁Excel的Sumproduct函数的功能,以用于简化数据分析。这种多功能功能毫不费力地结合了求和功能,扩展到跨相应范围或数组的加法,减法和分裂。 无论您是分析趋势还是解决复杂的计算,Sumproduct都会将数字转换为可...人工智能 发布于2025-04-16
Excel SUMPRODUCT函数详解 - 数据分析学院Excel的SumProduct函数:数据分析PowerHouse 解锁Excel的Sumproduct函数的功能,以用于简化数据分析。这种多功能功能毫不费力地结合了求和功能,扩展到跨相应范围或数组的加法,减法和分裂。 无论您是分析趋势还是解决复杂的计算,Sumproduct都会将数字转换为可...人工智能 发布于2025-04-16 -
深度研究全面开放,ChatGPT Plus用户福利Openai的深入研究:改变游戏的AI研究 Openai已为所有Chatgpt加上订户释放了深入的研究,并承诺在研究效率方面具有重大提高。 在测试了双子座,Grok 3和困惑等竞争对手的类似功能之后,我可以自信地将Openai的深入研究宣布为出色的选择。此博客深入研究了它的功能。 目录 什么是...人工智能 发布于2025-04-16
-
亚马逊Nova Today真实体验与评测 - Analytics Vidhya亚马逊最近的回复:Invent 2024活动展示了Nova,这是其最先进的基础模型套件,旨在彻底改变AI和内容创建。本文深入研究了Nova的架构,通过动手实例探索其功能,并检查基准结果。 我们将介绍功能,评论,基准和对AI应用程序的影响。 [2 此探索将涵盖Amazon Nova的功能,详细的评论...人工智能 发布于2025-04-16
-
ChatGPT定时任务功能的5种使用方法Chatgpt的新计划任务:使用AI 自动化您的一天 Chatgpt最近引入了一个改变游戏规则的功能:计划的任务。 这允许用户自动化重复提示,即使在离线时,也可以在预定时间接收通知或响应。想象一下每天策划的新闻通讯,自动化工作时间表或及时的习惯提醒 - 所有这些都是由Chatgpt自动处理的。...人工智能 发布于2025-04-16
-
三款AI聊机器人对同一提示的反应,哪个最佳?这是我发现的。在精心策划且详细的提示中扮演着质量良好的提示,在输出的质量中扮演任何cathbot生产的质量。与所有工具一样,输出仅与使用该工具的人的技能一样好。 AI聊天机器人没有什么不同。 有了这种理解,我指示每个模型创建一个针对个人理财的基本指南。这种方法使我能够评估多个相互联系的主题(特别是...人工智能 发布于2025-04-15
-
ChatGPT足矣,无需专用AI聊机在一个新的AI聊天机器人每天启动的世界中,决定哪一个是正确的“一个”。但是,以我的经验,chatgpt处理了我所丢下的几乎所有内容,而无需在平台之间切换,只需稍有及时的工程。 在许多实践应用程序中可能会让您感到惊讶。它的范围令人印象深刻,使用户可以生成代码段,草稿求职信,甚至翻译语言。这种多功能性...人工智能 发布于2025-04-14
-
印度AI时刻:与中美在生成AI领域竞赛印度的AI抱负:2025 Update 与中国和美国在生成AI上进行了大量投资,印度正在加快自己的Genai计划。 不可否认的是,迫切需要迎合印度各种语言和文化景观的土著大语模型(LLM)和AI工具。 本文探讨了印度新兴的Genai生态系统,重点介绍了2025年工会预算,公司参与,技能开发计划...人工智能 发布于2025-04-13
-
使用Airflow和Docker自动化CSV到PostgreSQL的导入本教程演示了使用Apache气流,Docker和PostgreSQL构建强大的数据管道,以使数据传输从CSV文件自动化到数据库。 我们将介绍有效工作流程管理的核心气流概念,例如DAG,任务和操作员。 该项目展示了创建可靠的数据管道,该数据管线读取CSV数据并将其写入PostgreSQL数据库。我们...人工智能 发布于2025-04-12
-
群智能算法:三个Python实现Imagine watching a flock of birds in flight. There's no leader, no one giving directions, yet they swoop and glide together in perfect harmony. It may...人工智能 发布于2025-03-24
-
如何通过抹布和微调使LLM更准确Imagine studying a module at university for a semester. At the end, after an intensive learning phase, you take an exam – and you can recall th...人工智能 发布于2025-03-24
-
什么是Google Gemini?您需要了解的有关Google Chatgpt竞争对手的一切Google recently released its new Generative AI model, Gemini. It results from a collaborative effort by a range of teams at Google, including members ...人工智能 发布于2025-03-23
-
与DSPY提示的指南DSPY(声明性的自我改善语言程序)通过抽象及时工程的复杂性来彻底改变LLM应用程序的开发。 本教程提供了使用DSPY的声明方法来构建强大的AI应用程序的综合指南。 [2 抓取DSPY的声明方法,用于简化LLM应用程序开发。 了解DSPY如何自动化提示工程并优化复杂任务的性能。 探索实用的DS...人工智能 发布于2025-03-22
-
自动化博客到Twitter线程本文详细介绍了使用Google的Gemini-2.0 LLM,Chromadb和Shiplit自动化长效内容的转换(例如博客文章)。 手动线程创建耗时;此应用程序简化了该过程。 [2 [2 使用Gemini-2.0,Chromadb和Shatlit自动化博客到twitter线程转换。 获得实用的经...人工智能 发布于2025-03-11
-
人工免疫系统(AIS):python示例的指南本文探讨了人造免疫系统(AIS),这是受人类免疫系统识别和中和威胁的非凡能力启发的计算模型。 我们将深入研究AIS的核心原理,检查诸如克隆选择,负面选择和免疫网络理论之类的关键算法,并用Python代码示例说明其应用。 [2 抗体:识别并结合特定威胁(抗原)。在AIS中,这些代表了问题的潜在解决方...人工智能 发布于2025-03-04
-
尝试向 ChatGPT 询问这些关于您自己的有趣问题有没有想过 ChatGPT 了解您的哪些信息?随着时间的推移,它如何处理您提供给它的信息?我在不同的场景中使用过 ChatGPT 堆,在特定的交互后看看它会说什么总是很有趣。✕ 删除广告 所以,为什么不尝试向 ChatGPT 询问其中一些问题来看看它对你的真实看法是什么? 我理想生活中的...人工智能 发布于2024-11-22















学习中文
- 1 走路用中文怎么说?走路中文发音,走路中文学习
- 2 坐飞机用中文怎么说?坐飞机中文发音,坐飞机中文学习
- 3 坐火车用中文怎么说?坐火车中文发音,坐火车中文学习
- 4 坐车用中文怎么说?坐车中文发音,坐车中文学习
- 5 开车用中文怎么说?开车中文发音,开车中文学习
- 6 游泳用中文怎么说?游泳中文发音,游泳中文学习
- 7 骑自行车用中文怎么说?骑自行车中文发音,骑自行车中文学习
- 8 你好用中文怎么说?你好中文发音,你好中文学习
- 9 谢谢用中文怎么说?谢谢中文发音,谢谢中文学习
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









