
Gosync.Pool 及其背後的機制
 瀏覽:623
瀏覽:623
这是帖子的摘录;完整的帖子可以在这里找到:https://victoriametrics.com/blog/go-sync-pool/
这篇文章是关于 Go 中处理并发的系列文章的一部分:
- Gosync.Mutex:正常和饥饿模式
- Gosync.WaitGroup 和对齐问题
- Gosync.Pool 及其背后的机制(我们在这里)
- Gosync.Cond,最被忽视的同步机制
在VictoriaMetrics源代码中,我们经常使用sync.Pool,老实说它非常适合我们处理临时对象的方式,特别是字节缓冲区或切片。
标准库中常用。例如,在encoding/json包中:
package json
var encodeStatePool sync.Pool
// An encodeState encodes JSON into a bytes.Buffer.
type encodeState struct {
bytes.Buffer // accumulated output
ptrLevel uint
ptrSeen map[any]struct{}
}
在本例中,sync.Pool 用于重用 *encodeState 对象,该对象处理将 JSON 编码为 bytes.Buffer 的过程。
我们不会在每次使用后抛出这些对象,这只会给垃圾收集器带来更多工作,而是将它们存储在池中(sync.Pool)。下次当我们需要类似的东西时,我们只需从池中获取它,而不是从头开始制作一个新的。
您还会在net/http包中找到多个sync.Pool实例,它们用于优化I/O操作:
package http
var (
bufioReaderPool sync.Pool
bufioWriter2kPool sync.Pool
bufioWriter4kPool sync.Pool
)
当服务器读取请求主体或写入响应时,它可以快速从这些池中提取预先分配的读取器或写入器,从而跳过额外的分配。此外,还设置了*bufioWriter2kPool和*bufioWriter4kPool这2个写入池来处理不同的写入需求。
func bufioWriterPool(size int) *sync.Pool {
switch size {
case 2
好了,介绍就这么多了。
今天,我们将深入探讨sync.Pool的全部内容、定义、它的使用方式、幕后情况以及您可能想知道的所有其他内容。
顺便说一句,如果你想要更实用的东西,我们的 Go 专家有一篇很好的文章,展示了我们如何在 VictoriaMetrics 中使用sync.Pool:时间序列数据库中的性能优化技术:sync.Pool 用于 CPU 绑定操作
什么是sync.Pool?
简单来说,Go 中的sync.Pool 是一个可以保存临时对象以供以后重用的地方。
但是事情是这样的,你无法控制池中保留多少对象,并且你放入其中的任何东西都可以随时删除,没有任何警告,阅读上一节时你就会知道为什么。
好处是,池被构建为线程安全的,因此多个 goroutine 可以同时利用它。考虑到它是同步包的一部分,这并不奇怪。
“但是我们为什么要费心重用对象呢?”
当你同时运行很多 goroutine 时,它们通常需要类似的对象。想象一下同时运行 go f() 多次。
如果每个 goroutine 创建自己的对象,内存使用量会快速增加,这会给垃圾收集器带来压力,因为一旦不再需要这些对象,它就必须清理它们。
这种情况会造成一个循环,高并发导致高内存使用率,从而减慢垃圾收集器的速度。 sync.Pool 旨在帮助打破这个循环。
type Object struct {
Data []byte
}
var pool sync.Pool = sync.Pool{
New: func() any {
return &Object{
Data: make([]byte, 0, 1024),
}
},
}
要创建一个池,您可以提供一个 New() 函数,该函数在池为空时返回一个新对象。这个函数是可选的,如果你不提供它,如果池为空,则返回 nil。
在上面的代码片段中,目标是重用 Object 结构实例,特别是其中的切片。
重复使用切片有助于减少不必要的生长。
例如,如果切片在使用过程中增长到 8192 字节,您可以将其长度重置为零,然后再将其放回池中。底层数组的容量仍然是 8192,因此下次需要时,这 8192 字节就可以重用了。
func (o *Object) Reset() {
o.Data = o.Data[:0]
}
func main() {
testObject := pool.Get().(*Object)
// do something with testObject
testObject.Reset()
pool.Put(testObject)
}
流程非常清晰:您从池中获取一个对象,使用它,重置它,然后将其放回池中。重置对象可以在将其放回之前或从池中获取它之后立即完成,但这不是强制性的,这是常见的做法。
如果您不喜欢使用类型断言 pool.Get().(*Object),有几种方法可以避免它:
- 使用专用函数从池中获取对象:
func getObjectFromPool() *Object {
obj := pool.Get().(*Object)
return obj
}
- 创建您自己的sync.Pool通用版本:
type Pool[T any] struct {
sync.Pool
}
func (p *Pool[T]) Get() T {
return p.Pool.Get().(T)
}
func (p *Pool[T]) Put(x T) {
p.Pool.Put(x)
}
func NewPool[T any](newF func() T) *Pool[T] {
return &Pool[T]{
Pool: sync.Pool{
New: func() interface{} {
return newF()
},
},
}
}
通用包装器为您提供了一种更类型安全的方式来使用池,避免类型断言。
请注意,由于额外的间接层,它增加了一点点开销。在大多数情况下,这种开销很小,但如果您处于对 CPU 高度敏感的环境中,最好运行基准测试来看看是否值得。
但是等等,还有更多。
同步池和分配陷阱
如果您从之前的许多示例(包括标准库中的示例)中注意到,我们在池中存储的通常不是对象本身,而是指向该对象的指针。
让我用一个例子来解释为什么:
var pool = sync.Pool{
New: func() any {
return []byte{}
},
}
func main() {
bytes := pool.Get().([]byte)
// do something with bytes
_ = bytes
pool.Put(bytes)
}
我们正在使用[]字节池。通常(尽管并非总是),当您将值传递给接口时,可能会导致该值被放置在堆上。这种情况也发生在这里,不仅适用于切片,还适用于传递给 pool.Put() 的任何不是指针的内容。
如果使用逃逸分析进行检查:
// escape analysis $ go build -gcflags=-m bytes escapes to heap
现在,我不是说我们的变量字节移动到堆,我会说“字节的值通过接口转义到堆”。
为了真正理解为什么会发生这种情况,我们需要深入研究逃逸分析的工作原理(我们可能会在另一篇文章中这样做)。但是,如果我们将指针传递给 pool.Put(),则没有额外的分配:
var pool = sync.Pool{
New: func() any {
return new([]byte)
},
}
func main() {
bytes := pool.Get().(*[]byte)
// do something with bytes
_ = bytes
pool.Put(bytes)
}
再次运行逃逸分析,你会发现它不再逃逸到堆中。如果你想了解更多,Go源码中有一个例子。
同步池内部结构
在我们了解sync.Pool的实际工作原理之前,有必要先了解一下Go的PMG调度模型的基础知识,这确实是sync.Pool如此高效的支柱。
有一篇很好的文章用一些视觉效果分解了 PMG 模型:Go 中的 PMG 模型
如果您今天感到懒惰并正在寻找简化的摘要,我会支持您:
PMG 代表 P(逻辑 p处理器)、M(m机器线程)和 G(g或例程)。关键是每个逻辑处理器(P)在任何时候只能有一个机器线程(M)在其上运行。为了让 goroutine (G) 运行,它需要附加到线程 (M)。
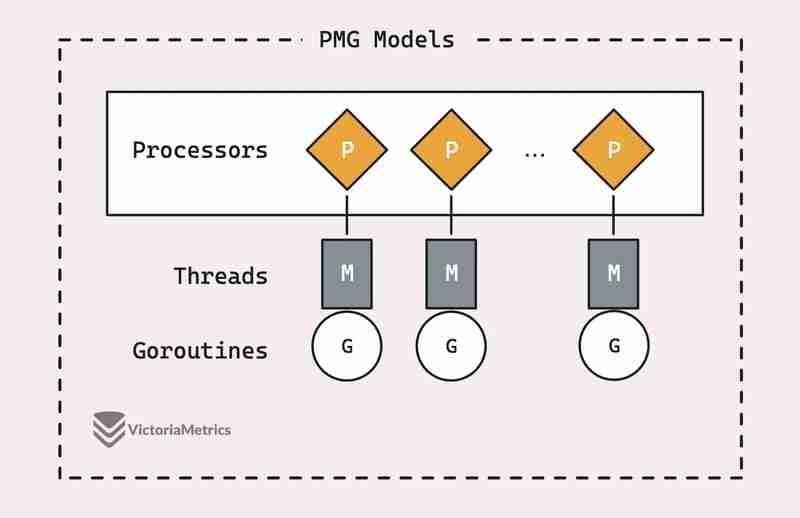
这可以归结为两个关键点:
- 如果你有 n 个逻辑处理器 (P),只要你至少有 n 个机器线程 (M) 可用,你就可以并行运行最多 n 个 goroutine。
- 在任一时刻,单个处理器(P)上只能运行一个 goroutine(G)。因此,当 P1 忙于 G 时,没有其他 G 可以在该 P1 上运行,直到当前 G 被阻塞、完成或发生其他事情将其释放。
但问题是,Go 中的sync.Pool 不仅仅是一个大池,它实际上由几个“本地”池组成,每个池都与一个特定的处理器上下文(或 P)相关联,Go 的运行时是在任何给定时间进行管理。
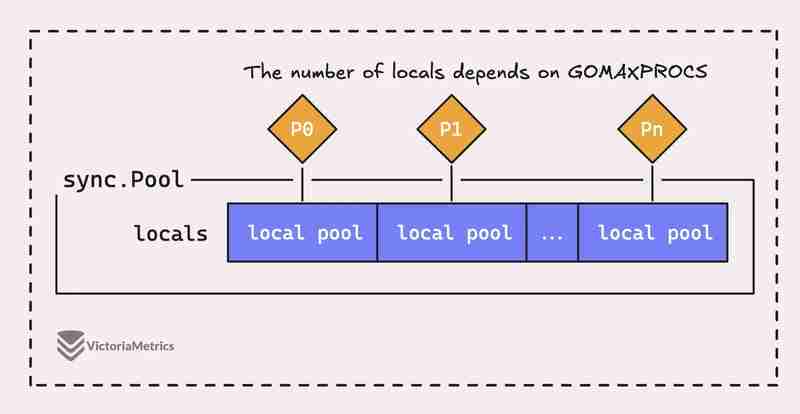
当运行在处理器(P)上的 goroutine 需要池中的对象时,它会首先检查自己的 P 本地池,然后再查找其他地方。
完整的帖子可以在这里找到:https://victoriametrics.com/blog/go-sync-pool/
-
 Java字符串非空且非null的有效檢查方法檢查字符串是否不是null而不是空的 if(str!= null && str.isementy())二手: if(str!= null && str.length()== 0) option 3:trim()。 isement(Isement() trim whitespace whites...程式設計 發佈於2025-07-17
Java字符串非空且非null的有效檢查方法檢查字符串是否不是null而不是空的 if(str!= null && str.isementy())二手: if(str!= null && str.length()== 0) option 3:trim()。 isement(Isement() trim whitespace whites...程式設計 發佈於2025-07-17 -
如何從Python中的字符串中刪除表情符號:固定常見錯誤的初學者指南?從python import codecs import codecs import codecs 導入 text = codecs.decode('這狗\ u0001f602'.encode('utf-8'),'utf-8') 印刷(文字)#帶有...程式設計 發佈於2025-07-17
-
如何避免Go語言切片時的內存洩漏?,a [j:] ...雖然通常有效,但如果使用指針,可能會導致內存洩漏。這是因為原始的備份陣列保持完整,這意味著新切片外部指針引用的任何對象仍然可能佔據內存。 copy(a [i:] 對於k,n:= len(a)-j i,len(a); k程式設計 發佈於2025-07-17
-
為什麼不````''{margin:0; }`始終刪除CSS中的最高邊距?在CSS 問題:不正確的代碼: 全球範圍將所有餘量重置為零,如提供的代碼所建議的,可能會導致意外的副作用。解決特定的保證金問題是更建議的。 例如,在提供的示例中,將以下代碼添加到CSS中,將解決餘量問題: body H1 { 保證金頂:-40px; } 此方法更精確,避免了由全局保證金重置...程式設計 發佈於2025-07-17
-
如何從PHP中的數組中提取隨機元素?從陣列中的隨機選擇,可以輕鬆從數組中獲取隨機項目。考慮以下數組:; 從此數組中檢索一個隨機項目,利用array_rand( array_rand()函數從數組返回一個隨機鍵。通過將$項目數組索引使用此鍵,我們可以從數組中訪問一個隨機元素。這種方法為選擇隨機項目提供了一種直接且可靠的方法。程式設計 發佈於2025-07-17
-
如何有效地選擇熊貓數據框中的列?在處理數據操作任務時,在Pandas DataFrames 中選擇列時,選擇特定列的必要條件是必要的。在Pandas中,選擇列的各種選項。 選項1:使用列名 如果已知列索引,請使用ILOC函數選擇它們。請注意,python索引基於零。 df1 = df.iloc [:,0:2]#使用索引0和1 ...程式設計 發佈於2025-07-17
-
在PHP中如何高效檢測空數組?在PHP 中檢查一個空數組可以通過各種方法在PHP中確定一個空數組。如果需要驗證任何數組元素的存在,則PHP的鬆散鍵入允許對數組本身進行直接評估:一種更嚴格的方法涉及使用count()函數: if(count(count($ playerList)=== 0){ //列表為空。 } 對...程式設計 發佈於2025-07-17
-
在細胞編輯後,如何維護自定義的JTable細胞渲染?在JTable中維護jtable單元格渲染後,在JTable中,在JTable中實現自定義單元格渲染和編輯功能可以增強用戶體驗。但是,至關重要的是要確保即使在編輯操作後也保留所需的格式。 在設置用於格式化“價格”列的“價格”列,用戶遇到的數字格式丟失的“價格”列的“價格”之後,問題在設置自定義單元...程式設計 發佈於2025-07-17
-
表單刷新後如何防止重複提交?在Web開發中預防重複提交 在表格提交後刷新頁面時,遇到重複提交的問題是常見的。要解決這個問題,請考慮以下方法: 想像一下具有這樣的代碼段,看起來像這樣的代碼段:)){ //數據庫操作... 迴聲“操作完成”; 死(); } ? > ...程式設計 發佈於2025-07-17
-
如何將PANDAS DataFrame列轉換為DateTime格式並按日期過濾?Transform Pandas DataFrame Column to DateTime FormatScenario:Data within a Pandas DataFrame often exists in various formats, including strings.使用時間數據時...程式設計 發佈於2025-07-17
-
Python環境變量的訪問與管理方法Accessing Environment Variables in PythonTo access environment variables in Python, utilize the os.environ object, which represents a mapping of envir...程式設計 發佈於2025-07-17
-
切換到MySQLi後CodeIgniter連接MySQL數據庫失敗原因無法連接到mySQL數據庫:故障排除錯誤消息要調試問題,建議將以下代碼添加到文件的末尾.//config/database.php並查看輸出: ... ... 迴聲'... echo '<pre>'; print_r($db['default']); echo '</pr...程式設計 發佈於2025-07-17
-
為什麼我在Silverlight Linq查詢中獲得“無法找到查詢模式的實現”錯誤?查詢模式實現缺失:解決“無法找到”錯誤在Silverlight應用程序中,嘗試使用LINQ建立LINQ連接以錯誤而實現的數據庫”,無法找到查詢模式的實現。”當省略LINQ名稱空間或查詢類型缺少IEnumerable 實現時,通常會發生此錯誤。 解決問題來驗證該類型的質量是至關重要的。在此特定實例...程式設計 發佈於2025-07-17
-
Python中嵌套函數與閉包的區別是什麼嵌套函數與python 在python中的嵌套函數不被考慮閉合,因為它們不符合以下要求:不訪問局部範圍scliables to incling scliables在封裝範圍外執行範圍的局部範圍。 make_printer(msg): DEF打印機(): 打印(味精) ...程式設計 發佈於2025-07-17
-
如何在Java字符串中有效替換多個子字符串?在java 中有效地替換多個substring,需要在需要替換一個字符串中的多個substring的情況下,很容易求助於重複應用字符串的刺激力量。 However, this can be inefficient for large strings or when working with nu...程式設計 發佈於2025-07-17















學習中文
- 1 走路用中文怎麼說? 走路中文發音,走路中文學習
- 2 坐飛機用中文怎麼說? 坐飞机中文發音,坐飞机中文學習
- 3 坐火車用中文怎麼說? 坐火车中文發音,坐火车中文學習
- 4 坐車用中文怎麼說? 坐车中文發音,坐车中文學習
- 5 開車用中文怎麼說? 开车中文發音,开车中文學習
- 6 游泳用中文怎麼說? 游泳中文發音,游泳中文學習
- 7 騎自行車用中文怎麼說? 骑自行车中文發音,骑自行车中文學習
- 8 你好用中文怎麼說? 你好中文發音,你好中文學習
- 9 謝謝用中文怎麼說? 谢谢中文發音,谢谢中文學習
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









