
使用 Python 掌握機器學習:基礎與關鍵概念
 瀏覽:813
瀏覽:813
In today's era of Artificial Intelligence (AI), scaling businesses and streamlining workflows has never been easier or more accessible. AI and machine learning equip companies to make informed decisions, giving them a superpower to predict the future with just a few lines of code. Before taking a significant risk, wouldn't knowing if it's worth it be beneficial? Have you ever wondered how these AIs and machine learning models are trained to make such precise predictions?
In this article, we will explore, hands-on, how to create a machine-learning model that can make predictions from our input data. Join me on this journey as we delve into these principles together.
This is the first part of a series on mastering machine learning, focusing on the foundations and key concepts. In the second part, we will dive deeper into advanced techniques and real-world applications.
Introduction:
Machine Learning (ML) essentially means training a model to solve problems. It involves feeding large amounts of data (input-data) to a model, enabling it to learn and discover patterns from the data. Interestingly, the model's accuracy depends solely on the quantity and quality of data it is fed.
Machine learning extends beyond making predictions for enterprises; it powers innovations like self-driving cars, robotics, and much more. With continuous advancements in ML, there's no telling what incredible achievements lie ahead - it's simply amazing, right?
There's no contest as to why Python remains one of the most sought-after programming languages for machine learning. Its vast libraries, such as Scikit-Learn and Pandas, and its easy-to-read syntax make it ideal for ML tasks. Python offers a simplified and well-structured environment that allows developers to maximize their potential. As an open-source programming language, it benefits from contributions worldwide, making it even more suitable and advantageous for data science and machine learning.
Fundamentals Of Machine Learning
Machine Learning (ML) is a vast and complex field that requires years of continuous learning and practice. While it's impossible to cover everything in this article, let's look into some important fundamentals of machine learning, specifically:
- Supervised Machine Learning From its name, we can deduce that supervised machine learning involves some form of monitoring or structure. It entails mapping one function to another; that is, providing labeled data input (i) to the machine, explaining what should be done (algorithms), and waiting for its output (j). Through this mapping, the machine learns to predict the output (j) whenever an input (i) is fed into it. The result will always remain output (j). Supervised ML can further be classified into:
Regression: When a variable input (i) is supplied as data to train a machine, it produces a continuous numerical output (j). For example, a regression algorithm can be used to predict the price of an item based on its size and other features.
Classification: This algorithm makes predictions based on grouping by determining certain attributes that make up the group. For example, predicting whether a product review is positive, negative, or neutral.
- Unsupervised Machine Learning Unsupervised Machine Learning tackles unlabeled or unmonitored data. Unlike supervised learning, where models are trained on labeled data, unsupervised learning algorithms identify patterns and relationships in data without prior knowledge of the outcomes. For example, grouping customers based on their purchasing behavior.
Setting Up Your Environment
When setting up your environment to create your first model, it's essential to understand some basic steps in ML and familiarize yourself with the libraries and tools we will explore in this article.
Steps in Machine Learning:
- Import the Data: Gather the data you need for your analysis.
- Clean the Data: Ensure your data is in good and complete shape by handling missing values and correcting inconsistencies.
- Split the Data: Divide the data into training and test sets.
- Create a Model: Choose your preferred algorithm to analyze the data and build your model.
- Train the Model: Use the training set to teach your model.
- Make Predictions: Use the test set to make predictions with your trained model.
- Evaluate and Improve: Assess the model's performance and refine it based on the outputs.
Common Libraries and Tools:
NumPy: Known for providing multidimensional arrays, NumPy is fundamental for numerical computations.
Pandas: A data analysis library that offers data frames (two-dimensional data structures similar to Excel spreadsheets) with rows and columns.
Matplotlib: Matplotlib is a two-dimensional plotting library for creating graphs and plots.
Scikit-Learn: The most popular machine learning library, providing all common algorithms like decision trees, neural networks, and more.
Recommended Development Environment:
Standard IDEs such as VS Code or terminals may not be ideal when creating a model due to the difficulty in inspecting data while writing code. For our learning purposes, the recommended environment is Jupyter Notebook, which provides an interactive platform to write and execute code, visualize data, and document the process simultaneously.
Step-by-Step Setup:
Download Anaconda:
Anaconda is a popular distribution of Python and R for scientific computing and data science. It includes the Jupyter Notebook and other essential tools.
Download Anaconda from this link.
Install Anaconda:
Follow the installation instructions based on your operating system (Windows, macOS, or Linux).
After the installation is complete, you will have access to the Anaconda Navigator, which is a graphical interface for managing your Anaconda packages, environments, and notebooks.
Launching Jupyter Notebook:
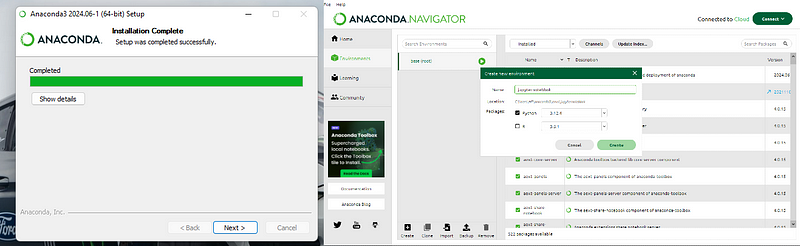
Open the Anaconda Navigator
In the Navigator, click on the "Environments" tab.
Select the "base (root)" environment, and then click "Open with Terminal" or "Open Terminal" (the exact wording may vary depending on the OS).
In the terminal window that opens, type the command jupyter notebook and press Enter.
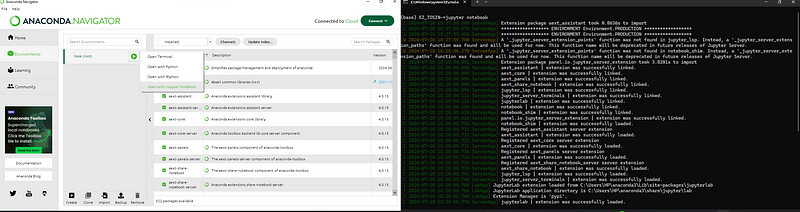
This command will launch the Jupyter Notebook server and automatically open a new tab in your default web browser, displaying the Jupyter Notebook interface.
Using Jupyter Notebook:
The browser window will show a file directory where you can navigate to your project folder or create new notebooks.
Click "New" and select "Python 3" (or the appropriate kernel) to create a new Jupyter Notebook.
You can now start writing and executing your code in the cells of the notebook. The interface allows you to document your code, visualize data, and explore datasets interactively.
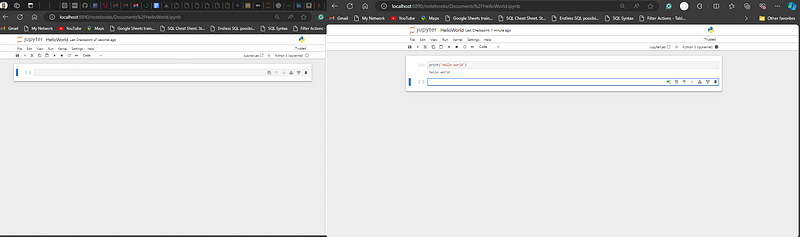
Building Your First Machine Learning Model
In building your first model, we have to take cognizance of the steps in Machine Learning as discussed earlier, which are:
- Import the Data
- Clean the Data
- Split the Data
- Create a Model
- Train the Model
- Make Predictions
- Evaluate and Improve
Now, let's assume a scenario involving an online bookstore where users sign up and provide their necessary information such as name, age, and gender. Based on their profile, we aim to recommend various books they are likely to buy and build a model that helps boost sales.
First, we need to feed the model with sample data from existing users. The model will learn patterns from this data to make predictions. When a new user signs up, we can tell the model, "Hey, we have a new user with this profile. What kind of book are they likely to be interested in?" The model will then recommend, for instance, a history or a romance novel, and based on that, we can make personalized suggestions to the user.
Let's break down the process step-by-step:
- Import the Data: Load the dataset containing user profiles and their book preferences.
- Clean the Data: Handle missing values, correct inconsistencies, and prepare the data for analysis.
- Split the Data: Divide the dataset into training and testing sets to evaluate the model's performance.
- Create a Model: Choose a suitable machine learning algorithm to build the recommendation model.
- Train the Model: Train the model using the training data to learn the patterns and relationships within the data.
- Make Predictions: Use the trained model to predict book preferences for new users based on their profiles.
- Evaluate and Improve: Assess the model's accuracy using the testing data and refine it to improve its performance.
By following these steps, you will be able to build a machine-learning model that effectively recommends books to users, enhancing their experience and boosting sales for the online bookstore. You can gain access to the datasets used in this tutorial here.
Let's walk through a sample code snippet to illustrate the process of testing the accuracy of the model:
- Import the necessary libraries:
import pandas as pd from sklearn.tree import DecisionTreeClassifier from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score
We start by importing the essential libraries. pandas is used for data manipulation and analysis, while DecisionTreeClassifier, train_test_split, and accuracy_score are from Scikit-learn, a popular machine learning library.
- Load the dataset:
book_data = pd.read_csv('book_Data.csv')
Read the dataset from a `CSV file` into a pandas DataFrame.
- Prepare the data:
X = book_data.drop(columns=['Genre']) y = book_data['Genre']
Create a feature matrix X by dropping the 'Genre' column from the dataset and a target vector y containing the 'Genre' column.
- Split the data:
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
Split the data into training and testing sets with 80% for training and 20% for testing.
- Initialize and train the model:
model = DecisionTreeClassifier() model.fit(X_train, y_train)
Initialize the DecisionTreeClassifier model and train it using the training data.
- Make predictions and evaluate the model:
predictions = model.predict(X_test) score = accuracy_score(y_test, predictions) print(score)
Make predictions on the test data and calculate the accuracy of the model by comparing the test labels to the predictions. Finally, print the accuracy score to the console.
In this example, we start by importing the essential libraries. Pandas is used for data manipulation and analysis, while DecisionTreeClassifier, train_test_split, and accuracy_score are from Scikit-learn, a popular machine learning library. We then read the dataset from a CSV file into a pandas DataFrame, prepare the data by creating a feature matrix X and a target vector y, split the data into training and testing sets, initialize and train the DecisionTreeClassifier model, make predictions on the test data, and calculate the accuracy of the model by comparing the test labels to the predictions.
Depending on the data you're using, the results will vary. For instance, in the output below, the accuracy score displayed is 0.7, but it may show 0.5 when the code is run again with a different dataset. The accuracy score will vary, a higher score indicates a more accurate model.
Output:
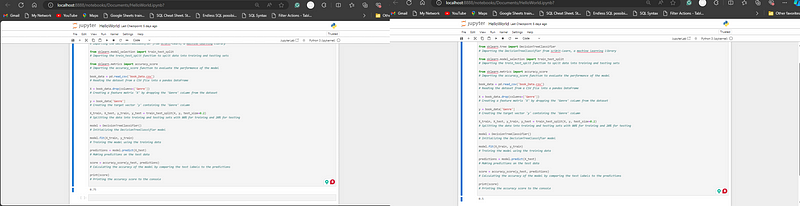
Data Preprocessing:
Now that you've successfully created your model, it's important to note that the kind of data used to train your model is crucial to the accuracy and reliability of your predictions. In Mastering Data Analysis: Unveiling the Power of Fairness and Bias in Information, I discussed extensively the importance of data cleaning and ensuring data fairness. Depending on what you intend to do with your model, it is essential to consider if your data is fair and free of any bias. Data cleaning is a very vital part of machine learning, ensuring that your model is trained on accurate, unbiased data. Some of these ethical considerations are:
Removing Outliers: Ensure that the data does not contain extreme values that could skew the model's predictions.
Handling Missing Values: Address any missing data points to avoid inaccurate predictions.
Standardizing Data: Make sure the data is in a consistent format, allowing the model to interpret it correctly.
Balancing the Dataset: Ensure that your dataset represents all categories fairly to avoid bias in predictions.
Ensuring Data Fairness: Check for any biases in your data that could lead to unfair predictions and take steps to mitigate them.
By addressing these ethical considerations, you ensure that your model is not only accurate but also fair and reliable, providing meaningful predictions.
Conclusion:
Machine learning is a powerful tool that can transform data into valuable insights and predictions. In this article, we explored the fundamentals of machine learning, focusing on supervised and unsupervised learning, and demonstrated how to set up your environment and build a simple machine learning model using Python and its libraries. By following these steps and experimenting with different algorithms and datasets, you can unlock the potential of machine learning to solve complex problems and make data-driven decisions.
In the next part of this series, we will dive deeper into advanced techniques and real-world applications of machine learning, exploring topics such as feature engineering, model evaluation, and optimization. Stay tuned for more insights and practical examples to enhance your machine-learning journey.
Additional Resources:
Programming with Mosh
Machine Learning Tutorial geeksforgeeks
-
 如何有效管理多個 JavaScript 和 CSS 檔案以獲得最佳頁面效能?管理多個JavaScript 和CSS 檔案:最佳實踐組織過多的JavaScript 和CSS 檔案可能會帶來挑戰,特別是在保持最佳頁面性能方面。下面列出了有效解決此問題的最佳實踐。 PHP Minify:簡化 HTTP 請求不要載入大量單獨的文件,而是考慮使用 PHP Minify。該工具將多個 ...程式設計 發佈於2024-11-08
如何有效管理多個 JavaScript 和 CSS 檔案以獲得最佳頁面效能?管理多個JavaScript 和CSS 檔案:最佳實踐組織過多的JavaScript 和CSS 檔案可能會帶來挑戰,特別是在保持最佳頁面性能方面。下面列出了有效解決此問題的最佳實踐。 PHP Minify:簡化 HTTP 請求不要載入大量單獨的文件,而是考慮使用 PHP Minify。該工具將多個 ...程式設計 發佈於2024-11-08 -
我的 Amazon SDE 面試經驗 – 5 月 4 日我的 Amazon SDE 面试经历 – 2024 年 5 月 2024 年 5 月,我有机会面试亚马逊的软件开发工程师 (SDE) 职位。这一切都始于一位招聘人员通过 LinkedIn 联系我。我很惊喜,因为它总是令人兴奋。 一切是如何开始的 招聘人员专业且清晰,...程式設計 發佈於2024-11-08
-
如何在 cURL POST 請求中傳送多個影像?在cURL POST 請求中使用陣列在嘗試使用cURL 傳送影像陣列時,使用者可能會遇到僅第一個影像的問題傳輸數組值。這個問題探討如何修正這個問題。 原始程式碼似乎在陣列結構上有一個小缺陷。要解決此問題,建議使用 http_build_query 來正確格式化陣列:$fields = array( ...程式設計 發佈於2024-11-08
-
為什麼 $_POST 中的 Axios POST 資料不可存取?Axios Post 參數未由$_POST 讀取您正在使用Axios 將資料發佈到PHP 端點,並希望在$ 中存取它_POST 或$_REQUEST。但是,您目前無法檢測到它。 最初,您使用了預設的 axios.post 方法,但由於懷疑標頭問題而切換到提供的程式碼片段。儘管發生了這種變化,數據仍然...程式設計 發佈於2024-11-08
-
## JPQL 中的建構函數表達式:使用還是不使用?JPQL 中的建構子表達式:有益或有問題的實踐? JPQL 提供了使用建構函式表達式在 select 語句中建立新物件的能力。雖然此功能提供了某些優勢,但它引發了關於其在軟體開發實踐中是否適用的問題。 建構函數表達式的優點建構函數表達式允許開發人員從實體中提取特定資料並進行組裝,從而簡化了資料檢索將...程式設計 發佈於2024-11-08
-
Python 變數:命名規則和型別推斷解釋Python 是一種廣泛使用的程式語言,以其簡單性和可讀性而聞名。了解變數的工作原理是編寫高效 Python 程式碼的基礎。在本文中,我們將介紹Python變數命名規則和類型推斷,確保您可以編寫乾淨、無錯誤的程式碼。 Python變數命名規則 在Python中命名變數時,必須遵循一...程式設計 發佈於2024-11-08
-
如何同時有效率地將多個欄位新增至 Pandas DataFrame ?同時向Pandas DataFrame 添加多個列在Pandas 資料操作中,有效地向DataFrame 添加多個新列可能是一項需要優雅解決方案的任務。雖然使用帶有等號的列列表語法的直覺方法可能看起來很簡單,但它可能會導致意外的結果。 挑戰如提供的範例所示,以下語法無法如預期建立新欄位:df[['c...程式設計 發佈於2024-11-08
-
從開發人員到資深架構師:技術專長與奉獻精神的成功故事一個開發人員晉升為高級架構師的真實故事 一位熟練的Java EE開發人員,只有4年的經驗,加入了一家跨國IT公司,並晉升為高級架構師。憑藉著多樣化的技能和 Oracle 認證的 Java EE 企業架構師,該開發人員已經證明了他在架構領域的勇氣。 加入公司後,開發人員被分配到一個項目,該公司在為汽...程式設計 發佈於2024-11-08
-
如何在 PHP 8.1 中有條件地將元素新增至關聯數組?條件數組元素添加在 PHP 中,有條件地將元素添加到關聯數組的任務可能是一個挑戰。例如,考慮以下數組:$arr = ['a' => 'abc'];我們如何有條件地添加'b' => 'xyz'使用array() 語句對此陣列進行運算?在這種情況下,三元運算子不是一...程式設計 發佈於2024-11-08
-
從打字機到像素:CMYK、RGB 和建立色彩視覺化工具的旅程當我還是個孩子的時候,我出版了一本關於漫畫的粉絲雜誌。那是在我擁有計算機之前很久——它是用打字機、紙和剪刀創建的! 粉絲雜誌最初是黑白的,在我的學校複印的。隨著時間的推移,隨著它取得了更大的成功,我能夠負擔得起帶有彩色封面的膠印! 然而,管理這些顏色非常具有挑戰性。每個封面必須列印四次,每種顏色...程式設計 發佈於2024-11-08
-
如何將 Boehm 的垃圾收集器與 C++ 標準函式庫整合?整合 Boehm 垃圾收集器和 C 標準庫要將 Boehm 保守垃圾收集器與 C標準庫集合無縫集成,有兩種主要方法:重新定義運算符::new此方法涉及重新定義運算符::new以使用Boehm的GC。但是,它可能與現有 C 程式碼衝突,並且可能無法在不同編譯器之間移植。 明確分配器參數您可以使用而不是...程式設計 發佈於2024-11-08
-
如何優化子集驗證以獲得頂級效能?優化子集驗證:確保每一位都很重要確定一個清單是否是另一個清單的子集的任務在程式設計中常遇到。雖然交叉列表和比較相等性是一種簡單的方法,但考慮效能至關重要,尤其是對於大型資料集。 考慮到這種情況,需要考慮的一個關鍵因素是任何清單在多個測試中是否保持不變。由於您的場景中的其中一個清單是靜態的,因此我們可...程式設計 發佈於2024-11-08
-
如何處理超出 MySQL BIGINT 限制的大整數?超出MySQL BIGINT 限制的大整數處理超出MySQL BIGINT 限制的大整數處理MySQL 的BIGINT 資料型別可能看起來是最廣泛的整數表示形式,但在處理時會出現限制超過20 位的數字。 超出BIGINT 的選項邊界當儲存需求超出BIGINT的能力時,會出現兩個選項:儲存為VARCH...程式設計 發佈於2024-11-08
-
如何確保 Python Selenium 中載入多個元素?Python Selenium:確保多個元素載入透過AJAX 處理動態載入的元素時,確認其外觀可能具有挑戰性。為了處理這種情況,我們將利用 Selenium 的 WebDriverWait 及其各種策略來確保多個元素的存在。 所有元素的可見性:驗證所有與特定選擇器匹配的元素,我們可以使用visibi...程式設計 發佈於2024-11-08















學習中文
- 1 走路用中文怎麼說? 走路中文發音,走路中文學習
- 2 坐飛機用中文怎麼說? 坐飞机中文發音,坐飞机中文學習
- 3 坐火車用中文怎麼說? 坐火车中文發音,坐火车中文學習
- 4 坐車用中文怎麼說? 坐车中文發音,坐车中文學習
- 5 開車用中文怎麼說? 开车中文發音,开车中文學習
- 6 游泳用中文怎麼說? 游泳中文發音,游泳中文學習
- 7 騎自行車用中文怎麼說? 骑自行车中文發音,骑自行车中文學習
- 8 你好用中文怎麼說? 你好中文發音,你好中文學習
- 9 謝謝用中文怎麼說? 谢谢中文發音,谢谢中文學習
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









