
使用 IAMB 演算法進行特徵選擇:淺談機器學習
 瀏覽:537
瀏覽:537
所以,故事是这样的——我最近完成了庄教授的一项学校作业,其中涉及一个非常酷的算法,称为增量关联马尔可夫毯子(IAMB)。现在,我没有数据科学或统计学的背景,所以这对我来说是新领域,但我喜欢学习新东西。目标?使用 IAMB 选择数据集中的特征并查看它如何影响机器学习模型的性能。
我们将回顾 IAMB 算法的基础知识,并将其应用于 Jason Brownlee 数据集中的 Pima Indians Diabetes Dataset。该数据集跟踪女性的健康数据,包括她们是否患有糖尿病。我们将使用IAMB来找出哪些特征(例如BMI或血糖水平)对于预测糖尿病最重要。
什么是IAMB算法,为什么使用它?
IAMB 算法就像一个朋友,可以帮助您清理谜团中的嫌疑人列表 - 它是一种特征选择方法,旨在仅挑选出对预测目标真正重要的变量。在本例中,目标是某人是否患有糖尿病。
- 正向阶段:添加与目标强相关的变量。
- 向后阶段:修剪掉那些没有真正帮助的变量,确保只留下最关键的变量。
简单来说,IAMB 通过仅选择最相关的特征来帮助我们避免数据集中的混乱。当您想让事情变得简单、提高模型性能并加快训练时间时,这尤其方便。
来源: 大规模马尔可夫毯子发现算法
这是什么阿尔法事物,为什么它很重要?
这就是alpha的用武之地。在统计学中,alpha (α) 是我们设置的阈值,用于决定什么算作“具有统计显着性”。作为教授指示的一部分,我使用了 0.05 的 alpha,这意味着我只想保留与目标变量随机关联的概率小于 5% 的特征。因此,如果某个特征的 p 值 小于 0.05,则意味着与我们的目标存在很强的、具有统计显着性的关联。
通过使用这个 alpha 阈值,我们只关注最有意义的变量,忽略任何未通过我们的“显着性”测试的变量。它就像一个过滤器,保留最相关的特征并剔除噪音。
动手实践:在皮马印第安人糖尿病数据集上使用IAMB
设置如下:皮马印第安人糖尿病数据集具有健康特征(血压、年龄、胰岛素水平等)和我们的目标,结果(是否有人患有糖尿病)。
首先我们加载数据并检查一下:
import pandas as pd # Load and preview the dataset url = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/pima-indians-diabetes.data.csv' column_names = ['Pregnancies', 'Glucose', 'BloodPressure', 'SkinThickness', 'Insulin', 'BMI', 'DiabetesPedigreeFunction', 'Age', 'Outcome'] data = pd.read_csv(url, names=column_names) print(data.head())
实施 Alpha = 0.05 的 IAMB
这是我们的 IAMB 算法的更新版本。我们使用 p 值 来决定保留哪些特征,因此仅选择那些 p 值小于 alpha (0.05) 的特征。
import pingouin as pg
def iamb(target, data, alpha=0.05):
markov_blanket = set()
# Forward Phase: Add features with a p-value alpha
for feature in list(markov_blanket):
reduced_mb = markov_blanket - {feature}
result = pg.partial_corr(data=data, x=feature, y=target, covar=reduced_mb)
p_value = result.at[0, 'p-val']
if p_value > alpha:
markov_blanket.remove(feature)
return list(markov_blanket)
# Apply the updated IAMB function on the Pima dataset
selected_features = iamb('Outcome', data, alpha=0.05)
print("Selected Features:", selected_features)
当我运行这个时,它给了我一份 IAMB 认为与糖尿病结果最密切相关的特征的细化列表。此列表有助于缩小我们构建模型所需的变量范围。
Selected Features: ['BMI', 'DiabetesPedigreeFunction', 'Pregnancies', 'Glucose']
测试IAMB选择的特征对模型性能的影响
一旦我们选择了特征,真正的测试就会将模型性能与所有特征与IAMB选择的特征进行比较。为此,我使用了一个简单的高斯朴素贝叶斯模型,因为它很简单并且在概率方面表现良好(这与整个贝叶斯氛围相关)。
这是训练和测试模型的代码:
from sklearn.model_selection import train_test_split
from sklearn.naive_bayes import GaussianNB
from sklearn.metrics import accuracy_score, f1_score, roc_auc_score
# Split data
X = data.drop('Outcome', axis=1)
y = data['Outcome']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# Model with All Features
model_all = GaussianNB()
model_all.fit(X_train, y_train)
y_pred_all = model_all.predict(X_test)
# Model with IAMB-Selected Features
X_train_selected = X_train[selected_features]
X_test_selected = X_test[selected_features]
model_iamb = GaussianNB()
model_iamb.fit(X_train_selected, y_train)
y_pred_iamb = model_iamb.predict(X_test_selected)
# Evaluate models
results = {
'Model': ['All Features', 'IAMB-Selected Features'],
'Accuracy': [accuracy_score(y_test, y_pred_all), accuracy_score(y_test, y_pred_iamb)],
'F1 Score': [f1_score(y_test, y_pred_all, average='weighted'), f1_score(y_test, y_pred_iamb, average='weighted')],
'AUC-ROC': [roc_auc_score(y_test, y_pred_all), roc_auc_score(y_test, y_pred_iamb)]
}
results_df = pd.DataFrame(results)
display(results_df)
结果
比较如下:
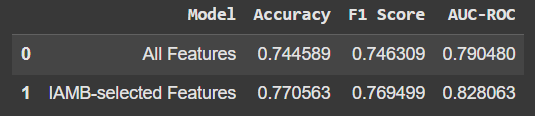
仅使用 IAMB 选择的功能可以略微提高准确性和其他指标。这并不是一个巨大的飞跃,但我们用更少的功能获得更好的性能这一事实是有希望的。另外,这意味着我们的模型不依赖“噪声”或不相关的数据。
要点
- IAMB 非常适合特征选择:它通过只关注对预测目标真正重要的内容来帮助清理我们的数据集。
- 少即是多:有时,更少的特征会给我们带来更好的结果,正如我们在这里看到的,模型精度略有提高。
- 学习和实验是有趣的部分:即使没有深厚的数据科学背景,深入研究这样的项目也可以开辟理解数据和机器学习的新方法。
我希望这能给 IAMB 一个友好的介绍!如果您好奇,请尝试一下 - 它是机器学习工具箱中的一个方便的工具,您可能会在自己的项目中看到一些很酷的改进。
来源: 大规模马尔可夫毯子发现算法
-
 為什麼我的 MySQLi 查詢只回傳一行,而我期望回傳多行?確定MySQLi 查詢僅檢索一行的根本原因當遇到MySQLi 查詢儘管期望多行但僅返回一行的問題時,有必要檢查所涉及的代碼。在所提供的情況下,查詢旨在從 sb_buddies 和 sb_users 表中檢索資料。 代碼從兩個表中選擇列,並根據 buddy_requester_id 欄位將它們連接起來...程式設計 發佈於2024-11-18
為什麼我的 MySQLi 查詢只回傳一行,而我期望回傳多行?確定MySQLi 查詢僅檢索一行的根本原因當遇到MySQLi 查詢儘管期望多行但僅返回一行的問題時,有必要檢查所涉及的代碼。在所提供的情況下,查詢旨在從 sb_buddies 和 sb_users 表中檢索資料。 代碼從兩個表中選擇列,並根據 buddy_requester_id 欄位將它們連接起來...程式設計 發佈於2024-11-18 -
在 Perl 和 Go 中探索密碼強度和數字驗證在本文中,我将解决 Perl Weekly Challenge #287 中的两个挑战:加强弱密码和验证数字。我将为这两项任务提供解决方案,展示 Perl 和 Go 中的实现。 目录 加强弱密码 验证数字 结论 加强弱密码 第一个任务是确定使密码更安全所需的最少更改次...程式設計 發佈於2024-11-18
-
如何使用 GopherLight 像專業人士一樣在 Go 中編寫 API文档 GopherLight 嘿伙计们,首先我要感谢您选择使用我们的项目。尽管他很小,但我们却以极大的热情做到了!要开始使用它,您首先必须安装 go,我们假设您已经安装了它。然后安装框架的主要模块,分别是req和router go get github.com/BrunoCicca...程式設計 發佈於2024-11-18
-
Bootstrap 4 Beta 中的列偏移發生了什麼事?Bootstrap 4 Beta:列偏移的刪除和恢復Bootstrap 4 在其Beta 1 版本中引入了重大更改柱子偏移了。然而,隨著 Beta 2 的後續發布,這些變化已經逆轉。 從 offset-md-* 到 ml-auto在 Bootstrap 4 Beta 1 中, offset-md-*...程式設計 發佈於2024-11-18
-
如何在 PHP 中組合兩個關聯數組,同時保留唯一 ID 並處理重複名稱?在 PHP 中組合關聯數組在 PHP 中,將兩個關聯數組組合成一個數組是常見任務。考慮以下請求:問題描述:提供的代碼定義了兩個關聯數組,$array1 和 $array2。目標是建立一個新陣列 $array3,它合併兩個陣列中的所有鍵值對。 此外,提供的陣列具有唯一的 ID,而名稱可能重疊。要求是建...程式設計 發佈於2024-11-18
-
如何使用不同單位的無單位 CSS 變數?如何靈活地使用無單位CSS 變數無單位CSS 變數提供了儲存數值的能力,這些數值可以在整個樣式表中方便使用。然而,可能會出現這樣的情況:您希望在不同的上下文中使用相同的變量,需要不同的單位,例如百分比或像素。 這種困境的一個例子是設定一個值為 10 的 CSS 變量,但是需要在一個實例中將其用作百分...程式設計 發佈於2024-11-18
-
當 #await 區塊在 Svelte(Kit) 中解析時執行函數跳至内容: 关于 svelte 中的 #await 块 当 #await 块解析或拒绝时运行(触发)函数 修复浏览器中显示的未定义或任何返回的文本 1. 方法一(返回空字符串): 2. 方法二(用CSS隐藏UI中函数返回的文本。) PS:需要雇用 SvelteKit 开发人员吗?联系我 ...程式設計 發佈於2024-11-18
-
一個 Java 檔案中可以有多個類別嗎?Java 檔案中的多個類別在 Java 中,單一 .java 檔案中可以有多個類別。不過,公共頂級類別只能有一個,而且必須與原始檔案同名。 一個文件中有多個類別的目的是為了組織邏輯上相關的程式碼。這些類別通常包括公共頂級類別的支援功能,例如內部資料結構或實用方法。透過將它們捆綁在一起,您可以將相...程式設計 發佈於2024-11-18
-
如何有效測試PDO資料庫連線並處理錯誤?測試PDO資料庫連線開發資料庫安裝時,確保資料庫連線的有效性至關重要。當嘗試建立預設設定時,這一點變得尤為重要。 PDO(PHP 資料物件)提供了一種測試有效和無效連接的有效方法。 驗證連線若要使用PDO 連線至MySQL 資料庫,語法為:$dbh = new pdo('mysql:host=127...程式設計 發佈於2024-11-18
-
當現有值相同時,MySQL 更新查詢是否會覆寫它們?MySQL更新查詢:覆寫現有值在MySQL中,更新表時,可能會遇到這樣的情況:為列指定的新值是與其目前值相同。在這種情況下,自然會出現一個問題:MySQL 會覆寫現有值還是完全忽略更新? UPDATE 語句的 MySQL 文件提供了答案:如果將列設定為它目前的值,MySQL 會注意到這一點並且不會更...程式設計 發佈於2024-11-18
-
為什麼 `std::atomic` 的儲存使用 XCHG 來實現 x86 上的順序一致性?為什麼std::atomic 的儲存採用XCHG 來實現順序一致性在x86 和x86_64 架構的std::atomic 上下文中,a具有順序一致性的儲存操作(std::memory_order_seq_cst) 使用XCHG而不是具有內存屏障的簡單存儲作為實現順序釋放語義的技術。 順序一致性和...程式設計 發佈於2024-11-18
-
為什麼 C++ 不直接支援從函數傳回數組?為什麼C 不贊成陣列返回函數C 景觀與Java 等語言相反,C 不支援陣列返回函數不為傳回數組的函數提供直接支援。雖然可以返回數組,但過程很麻煩。這引發了有關此設計決策背後的根本原因的問題。 C 中的陣列機制要理解這一點,我們必須深入研究 C 中陣列的基礎知識。 C,陣列名稱代表記憶體位址,而非陣列...程式設計 發佈於2024-11-18
-
好的,以下是一些適合文章內容的標題: * How to Fix the \"-lGL: not found\" Error in Qt * Qt Compilation Error: \"-lGL: not found\" - What to Do * Troubleshooting \"-lGL: not found\" Error in Qt Projects * Resolving the解決Qt 中的「-lGL:未找到」錯誤當嘗試在QtCreator 中編譯新建立的專案時,某些使用者可能會和遇到“-lGL:未找到”錯誤。出現此錯誤通常是因為未安裝必要的依賴項。 要解決此問題,請按照以下步驟操作: libgl1-mesa-dev: 該軟體包包含在 Qt 專案中支援 OpenGL 所需...程式設計 發佈於2024-11-18
-
PHP 的「eval」函數使用起來安全嗎?什麼時候 eval 不是邪惡的? 雖然 PHP 的 eval 函數經常被勸阻,但它在 PHP 5.3 中的實用性值得商榷。儘管出現了LSB 和閉包,但以下是一些可以想像的用例,其中eval 可能仍然是首選:評估安全表達式:Eval 可用於評估數值或PHP 程式碼的其他特定子集,例如簡單的數學表達式,...程式設計 發佈於2024-11-18















學習中文
- 1 走路用中文怎麼說? 走路中文發音,走路中文學習
- 2 坐飛機用中文怎麼說? 坐飞机中文發音,坐飞机中文學習
- 3 坐火車用中文怎麼說? 坐火车中文發音,坐火车中文學習
- 4 坐車用中文怎麼說? 坐车中文發音,坐车中文學習
- 5 開車用中文怎麼說? 开车中文發音,开车中文學習
- 6 游泳用中文怎麼說? 游泳中文發音,游泳中文學習
- 7 騎自行車用中文怎麼說? 骑自行车中文發音,骑自行车中文學習
- 8 你好用中文怎麼說? 你好中文發音,你好中文學習
- 9 謝謝用中文怎麼說? 谢谢中文發音,谢谢中文學習
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









