
Entropix:最大化推理效能的取樣技術
發佈於2024-11-07
 瀏覽:428
瀏覽:428
Entropix:最大化推理效能的取樣技術
根據 Entropix README,Entropix 使用基於熵的取樣方法。本文講解了基於熵和變熵的具體採樣技術。
熵和變熵
讓我們先解釋熵和變熵,因為它們是確定採樣策略的關鍵因素。
熵
在資訊理論中,熵是隨機變數不確定性的量測。隨機變數 X 的熵由下列方程式定義:
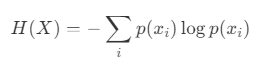
- X:離散隨機變數。
- x_i:X的第i種可能狀態。
- p(x_i):狀態x_i的機率。
當機率分佈均勻時,熵最大化。相反,當特定狀態比其他狀態更有可能出現時,熵就會減少。
變熵
變熵與熵密切相關,代表資訊內容的可變性。考慮隨機變數 X 的資訊內容 I(X)、熵 H(X) 和方差,變熵 V E(X) 定義如下:
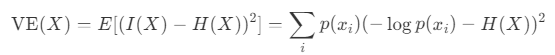
當機率 p(x_i) 變化很大時,變熵變大。當機率均勻時(無論是當分佈具有最大熵時,還是當一個值的機率為 1 而所有其他值的機率為 0 時),它會變小。
抽樣方法
接下來,讓我們探討採樣策略如何根據熵和變熵值變化。
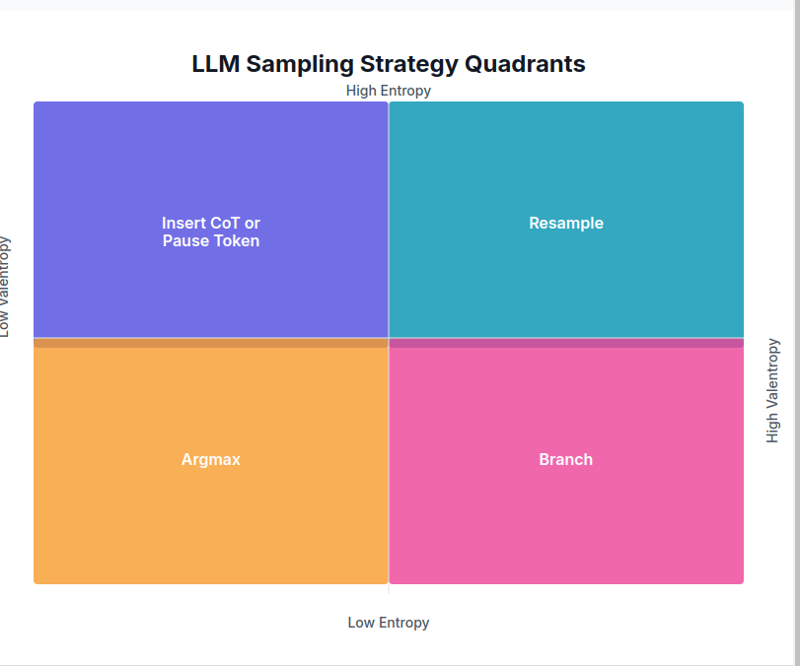
1. 低熵、低變熵 → Argmax
在這種情況下,特定令牌的預測機率比其他代幣高得多。由於下一個標記幾乎確定,因此使用 Argmax。
if ent代碼連結
2. 低熵、高變熵 → 分支
當有一定的信心,但存在多種可行的選擇時,就會發生這種情況。在這種情況下,分支策略用於從多個選擇中進行取樣並選擇最佳結果。
elif ent 5.0: temp_adj = 1.2 0.3 * interaction_strength top_k_adj = max(5, int(top_k * (1 0.5 * (1 - agreement)))) return _sample(logits, temperature=min(1.5, temperature * temp_adj), top_p=top_p, top_k=top_k_adj, min_p=min_p, generator=generator)代碼連結
雖然這種策略被稱為“分支”,但目前的程式碼似乎是調整取樣範圍並選擇單一路徑。 (如果有人有更多見解,我們將不勝感激。)
3. 高熵、低變熵 → CoT 或插入暫停令牌
當下一個token的預測機率相當均勻時,表示下一個上下文不確定,則插入一個澄清token來解決歧義。
elif ent > 3.0 and vent代碼連結
4. 高熵、高變熵 → 重採樣
在這種情況下,存在多個上下文,且下一個標記的預測機率較低。 重採樣策略採用較高的溫度設定和較低的 top-p。
elif ent > 5.0 and vent > 5.0: temp_adj = 2.0 0.5 * attn_vent top_p_adj = max(0.5, top_p - 0.2 * attn_ent) return _sample(logits, temperature=max(2.0, temperature * temp_adj), top_p=top_p_adj, top_k=top_k, min_p=min_p, generator=generator)代碼連結
中級案例
如果上述條件都不滿足,則執行自適應採樣。採取多個樣本,根據熵、變熵和注意力資訊計算最佳採樣分數。
else: return adaptive_sample( logits, metrics, gen_tokens, n_samples=5, base_temp=temperature, base_top_p=top_p, base_top_k=top_k, generator=generator )代碼連結
參考
- Entropix 儲存庫
- Entropix 在做什麼?
版本聲明
本文轉載於:https://dev.to/m_sea_bass/entropix-sampling-techniques-for-maximizing-inference-performance-2hgc?1如有侵犯,請聯絡[email protected]刪除
最新教學
更多>
-
 為什麼我的 Java 應用程式使用 GMT 而不是作業系統時區,如何修復它?如何解決Java 中預設時區不正確的問題在某些情況下,Java 應用程式可能會遇到JVM 時區預設為GMT 的問題作業系統(OS) 定義的時區。這可能會導致日期和時間處理不正確。 在 Windows Server Enterprise (2007) 上執行的 Java 開發工具包 (JDK) 版本 ...程式設計 發佈於2024-11-07
為什麼我的 Java 應用程式使用 GMT 而不是作業系統時區,如何修復它?如何解決Java 中預設時區不正確的問題在某些情況下,Java 應用程式可能會遇到JVM 時區預設為GMT 的問題作業系統(OS) 定義的時區。這可能會導致日期和時間處理不正確。 在 Windows Server Enterprise (2007) 上執行的 Java 開發工具包 (JDK) 版本 ...程式設計 發佈於2024-11-07 -
如何將 AWS SDK v2 與變數憑證結合使用?使用變數中的憑證執行 AWS SDK v2問:如何使用變數中的憑證執行 AWS SDK v2? 要利用 SDK v2 而不使用舊的 Session 類,您可以建立一個新客戶端並將您的憑證作為變數傳遞。考慮 IAM 服務的 getIAMClient 函數:func getIAMClient(ctx c...程式設計 發佈於2024-11-07
-
為什麼我的 Java 專案找不到「tools.jar」?Java專案中缺少Tools.jar在複雜的Java程式設計中,您可能會遇到“無法找到tools.jar”的神秘問題「錯誤。當您的專案缺少編譯和執行所必需的關鍵組件時,通常會出現此錯誤。診斷難題 檢查錯誤訊息後,您會發現系統正在運作無法在預期位置找到「tools.jar」檔案:C:\Program ...程式設計 發佈於2024-11-07
-
我什麼時候應該在資料庫系統中使用 MySQL BLOB 進行檔案管理?何時利用MySQL BLOB 進行檔案管理在資料庫管理中,處理檔案儲存時,出現兩個主要選項:檔案系統儲存或MySQL BLOB(二進位大型)物件)存儲。每種方法都有其優點和局限性,但選擇最佳方法取決於應用程式的特定要求。 效能注意事項在某些情況下,使用 BLOB 可以顯著提高效能。當同時從多個伺服器...程式設計 發佈於2024-11-07
-
如何在 Java 中轉義特殊字元以實現精確的正規表示式匹配?轉義特殊字元以實現最佳正則表達式匹配使用正則表達式(regex) 匹配文本時,轉義某有些特殊字元至關重要,以確保它們被解釋為文字而不是元字元。在Java中,必須轉義的特殊字元包括:。 [ ] { } ( ) \ < > * - = ! ? ^ $ |但是,需要注意一些例外情況:方括號([]) 內只有...程式設計 發佈於2024-11-07
-
用 Java 建立旋轉排序數組搜尋:了解樞軸搜尋和二分搜尋什麼是旋轉排序數組? 考慮一個排序數組,例如: [1, 2, 3, 4, 5, 6] 現在,如果這個陣列在某個樞軸處旋轉,例如在索引 3 處,它將變成: [4, 5, 6, 1, 2, 3] 請注意,陣列仍然是排序的,但它被分成兩部分。我們的目標是有效地在此類數組中搜尋目標值。 ...程式設計 發佈於2024-11-07
-
在 � 學習 Three.jsI had the chance to dive into some web development where I wanted to add interactive 3D elements that could move and react to certain triggers. Natura...程式設計 發佈於2024-11-07
-
模板文字可以真正重複使用嗎?模板文字:復興重用ES6 中的模板文字經常被吹捧為強大的文本操作工具,但一個棘手的問題仍然存在:它們真的可以重用嗎? 無法實現的期望乍一看,模板文字似乎只在聲明時承諾動態替換。這就引出了一個問題:什麼是保持靜態的模板? 打破循環與流行的看法相反,模板文字可以使用函數通過運行時替換來重新煥發活力構造函...程式設計 發佈於2024-11-07
-
在 Java 中使用 Fisher-Yates 演算法對陣列進行洗牌介紹 在電腦科學領域,對元素數組或列表進行洗牌是一種常見的操作,可用於各種應用程序,從隨機化遊戲結果到分發牌組中的紙牌。為此目的最有效的演算法之一是 Fisher-Yates Shuffle,也稱為 Knuth Shuffle。該演算法確保數組的每個排列都有相同的可能性,這使其成為...程式設計 發佈於2024-11-07
-
我作為全端開發人員的旅程:與 MERN Stack 一起成長的一年你好!我是 Shivaji Zirpe,一位充滿熱情的全端開發人員,專門研究 MERN 堆疊。在過去的一年裡,我深入研究了 Web 開發領域,廣泛使用了 React、Node.js、MongoDB 等。在這篇文章中,我想分享我的旅程、經歷以及我作為開發人員的成長過程。 ?我的經歷一...程式設計 發佈於2024-11-07
-
為什麼常數引用可以延長 C++ 中臨時變數的生命週期?透過常數引用擴展右值生命週期在C 中,常量引用不僅充當不可變別名,還可以延長臨時變量的生命週期。為什麼 C 委員會決定要實現此行為? 此功能的一個基本原理是隱藏類別和函數的實作細節。考慮一個可以傳回行向量或列向量的矩陣類別。為了最佳化效能,類別可以選擇根據其行優先或列優先組織傳回內部值的參考。透過要...程式設計 發佈於2024-11-07
-
如何在 Go 中將切片作為可變參數傳遞?將解壓縮的切片作為可變參數傳遞在 Go 中,可變參數函數接受不定數量的特定類型的參數。將切片的切片傳遞給此類函數時,了解所涉及的類型轉換和解包機制至關重要。 如果切片包含與可變參數參數類型相同的元素,則可以在不使用切片的情況下傳遞切片拆包。然而,如果切片中包含多種類型的混合或切片中包含切片,情況會變...程式設計 發佈於2024-11-07















學習中文
- 1 走路用中文怎麼說? 走路中文發音,走路中文學習
- 2 坐飛機用中文怎麼說? 坐飞机中文發音,坐飞机中文學習
- 3 坐火車用中文怎麼說? 坐火车中文發音,坐火车中文學習
- 4 坐車用中文怎麼說? 坐车中文發音,坐车中文學習
- 5 開車用中文怎麼說? 开车中文發音,开车中文學習
- 6 游泳用中文怎麼說? 游泳中文發音,游泳中文學習
- 7 騎自行車用中文怎麼說? 骑自行车中文發音,骑自行车中文學習
- 8 你好用中文怎麼說? 你好中文發音,你好中文學習
- 9 謝謝用中文怎麼說? 谢谢中文發音,谢谢中文學習
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









