
Перейти к синхронизации. Пул и механика, стоящая за ним
 Просматривать:751
Просматривать:751
Это отрывок из сообщения; полный пост доступен здесь: https://victoriametrics.com/blog/go-sync-pool/
Этот пост является частью серии об управлении параллелизмом в Go:
- Перейти к синхронизации. Мьютекс: обычный режим и режим голодания
- Go sync.WaitGroup и проблема выравнивания
- Go sync.Пул и его механика (мы здесь)
- Go sync.Cond, самый недооцененный механизм синхронизации
В исходном коде VictoriaMetrics мы часто используем sync.Pool, и, честно говоря, он отлично подходит для обработки временных объектов, особенно байтовых буферов или срезов.
Он обычно используется в стандартной библиотеке. Например, в пакетеcoding/json:
package json
var encodeStatePool sync.Pool
// An encodeState encodes JSON into a bytes.Buffer.
type encodeState struct {
bytes.Buffer // accumulated output
ptrLevel uint
ptrSeen map[any]struct{}
}
В этом случае sync.Pool используется для повторного использования объектов *encodeState, которые обрабатывают процесс кодирования JSON в байты.Buffer.
Вместо того, чтобы просто выбрасывать эти объекты после каждого использования, что только усложнит работу сборщику мусора, мы прячем их в пуле (sync.Pool). В следующий раз, когда нам понадобится что-то подобное, мы просто возьмем это из пула, а не создадим новое с нуля.
В пакете net/http вы также найдете несколько экземпляров sync.Pool, которые используются для оптимизации операций ввода-вывода:
package http
var (
bufioReaderPool sync.Pool
bufioWriter2kPool sync.Pool
bufioWriter4kPool sync.Pool
)
Когда сервер считывает тела запросов или записывает ответы, он может быстро извлечь из этих пулов предварительно выделенное устройство чтения или записи, пропуская дополнительные выделения. Кроме того, два пула записи, *bufioWriter2kPool и *bufioWriter4kPool, настроены для удовлетворения различных потребностей записи.
func bufioWriterPool(size int) *sync.Pool {
switch size {
case 2
Ладно, хватит вступления.
Сегодня мы углубимся в то, что такое sync.Pool, его определение, как он используется, что происходит под капотом и все остальное, что вы, возможно, захотите узнать.
Кстати, если вам нужно что-то более практичное, есть хорошая статья от наших экспертов по Go, показывающая, как мы используем sync.Pool в VictoriaMetrics: методы оптимизации производительности в базах данных временных рядов: sync.Pool для операций, связанных с процессором
]
Что такое синхронизирующий пул?
Проще говоря, sync.Pool в Go — это место, где вы можете хранить временные объекты для последующего повторного использования.
Но вот в чем дело: вы не контролируете, сколько объектов остается в пуле, и все, что вы туда помещаете, может быть удалено в любой момент без какого-либо предупреждения, и вы поймете почему, прочитав последний раздел.
]
Хорошим моментом является то, что пул создан как потокобезопасный, поэтому к нему могут одновременно подключаться несколько горутин. Неудивительно, учитывая, что это часть пакета синхронизации.
"Но зачем нам повторно использовать объекты?"
Когда одновременно выполняется много горутин, им часто нужны похожие объекты. Представьте, что вы запускаете go f() несколько раз одновременно.
Если каждая горутина создает свои собственные объекты, использование памяти может быстро увеличиться, и это создает нагрузку на сборщик мусора, поскольку ему приходится очищать все эти объекты, когда они больше не нужны.
Эта ситуация создает цикл, в котором высокий уровень параллелизма приводит к высокому использованию памяти, что затем замедляет работу сборщика мусора. sync.Pool призван помочь разорвать этот порочный круг.
type Object struct {
Data []byte
}
var pool sync.Pool = sync.Pool{
New: func() any {
return &Object{
Data: make([]byte, 0, 1024),
}
},
}
Чтобы создать пул, вы можете предоставить функцию New(), которая возвращает новый объект, когда пул пуст. Эта функция необязательна. Если вы ее не предоставите, пул просто вернет ноль, если он пуст.
В приведенном выше фрагменте цель состоит в том, чтобы повторно использовать экземпляр структуры Object, а именно фрагмент внутри него.
Повторное использование среза помогает уменьшить ненужный рост.
Например, если размер фрагмента во время использования вырастет до 8192 байт, вы можете сбросить его длину до нуля, прежде чем помещать его обратно в пул. Базовый массив по-прежнему имеет емкость 8192 байта, поэтому в следующий раз, когда они вам понадобятся, эти 8192 байта будут готовы к повторному использованию.
func (o *Object) Reset() {
o.Data = o.Data[:0]
}
func main() {
testObject := pool.Get().(*Object)
// do something with testObject
testObject.Reset()
pool.Put(testObject)
}
Последовательность действий довольно ясна: вы получаете объект из пула, используете его, сбрасываете его, а затем помещаете обратно в пул. Сброс объекта можно сделать либо до того, как вы поместите его обратно, либо сразу после того, как вы достанете его из пула, но это не обязательно, это обычная практика.
Если вы не являетесь поклонником использования утверждений типовpool.Get().(*Object), есть несколько способов избежать этого:
- Используйте специальную функцию для получения объекта из пула:
func getObjectFromPool() *Object {
obj := pool.Get().(*Object)
return obj
}
- Создайте собственную общую версию sync.Pool:
type Pool[T any] struct {
sync.Pool
}
func (p *Pool[T]) Get() T {
return p.Pool.Get().(T)
}
func (p *Pool[T]) Put(x T) {
p.Pool.Put(x)
}
func NewPool[T any](newF func() T) *Pool[T] {
return &Pool[T]{
Pool: sync.Pool{
New: func() interface{} {
return newF()
},
},
}
}
Общая оболочка обеспечивает более типобезопасную работу с пулом, избегая утверждений типов.
Обратите внимание, что это добавляет немного накладных расходов из-за дополнительного уровня косвенности. В большинстве случаев эти накладные расходы минимальны, но если вы работаете в среде с высокой чувствительностью к процессору, рекомендуется запустить тесты, чтобы увидеть, стоит ли оно того.
Но подождите, это еще не все.
sync.Pool и ловушка распределения
Если вы заметили из многих предыдущих примеров, в том числе из стандартной библиотеки, в пуле обычно хранится не сам объект, а указатель на объект.
Позвольте мне объяснить почему на примере:
var pool = sync.Pool{
New: func() any {
return []byte{}
},
}
func main() {
bytes := pool.Get().([]byte)
// do something with bytes
_ = bytes
pool.Put(bytes)
}
Мы используем пул размером в []байт. Обычно (хотя и не всегда), когда вы передаете значение в интерфейс, это может привести к помещению значения в кучу. Это происходит и здесь, не только со срезами, но и со всем, что вы передаете в пул.Put(), что не является указателем.
Если вы проверяете с помощью escape-анализа:
// escape analysis $ go build -gcflags=-m bytes escapes to heap
Я не говорю, что наша переменная bytes перемещается в кучу, я бы сказал: «значение байтов уходит в кучу через интерфейс».
Чтобы понять, почему это происходит, нам нужно разобраться, как работает escape-анализ (что мы могли бы сделать в другой статье). Однако если мы передаем указатель в Pool.Put(), дополнительного выделения не будет:
var pool = sync.Pool{
New: func() any {
return new([]byte)
},
}
func main() {
bytes := pool.Get().(*[]byte)
// do something with bytes
_ = bytes
pool.Put(bytes)
}
Запустите escape-анализ еще раз, и вы увидите, что он больше не переходит в кучу. Если вы хотите узнать больше, в исходном коде Go есть пример.
синхронизация. Внутреннее устройство пула
Прежде чем мы перейдем к тому, как на самом деле работает sync.Pool, стоит разобраться с основами модели планирования PMG Go, это действительно основа того, почему sync.Pool так эффективен.
Есть хорошая статья, в которой модель PMG представлена с некоторыми визуальными эффектами: модели PMG в Go
Если вам сегодня лень и вы ищете упрощенное изложение, я вас поддержу:
PMG означает P (логические pпроцессоры), M (mмашинные потоки) и G (gили процедуры). Ключевым моментом является то, что на каждом логическом процессоре (P) в любой момент времени может работать только один машинный поток (M). А для запуска горутины (G) ее необходимо присоединить к потоку (M).
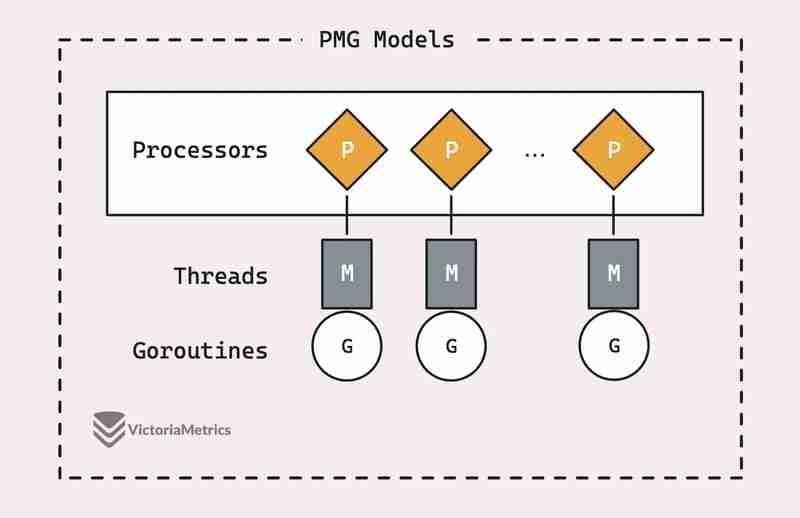
Это сводится к двум ключевым моментам:
- Если у вас n логических процессоров (P), вы можете запускать до n горутин параллельно, если у вас есть хотя бы n доступных машинных потоков (M).
- В любой момент времени на одном процессоре (P) может работать только одна горутина (G). Таким образом, когда P1 занят G, никакой другой G не может работать на этом P1 до тех пор, пока текущий G не будет заблокирован, не завершится или что-то еще не освободит его.
Но дело в том, что синхронизация. Пул в Go — это не просто один большой пул, он на самом деле состоит из нескольких «локальных» пулов, каждый из которых привязан к определенному контексту процессора, или P, который определяет среду выполнения Go. управление в любой момент времени.
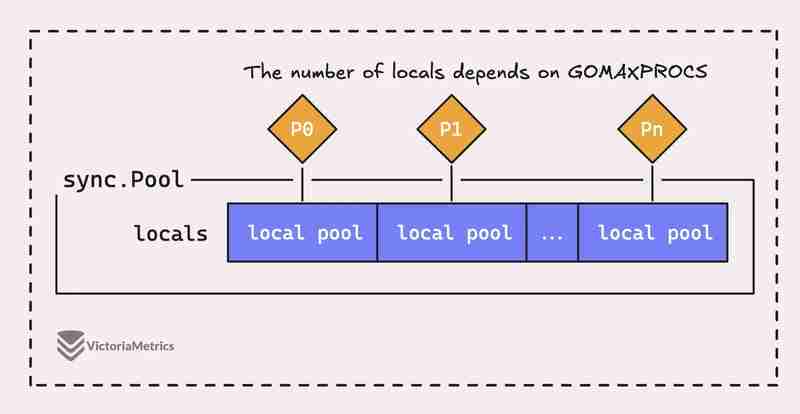
Когда горутина, работающая на процессоре (P), нуждается в объекте из пула, она сначала проверяет свой собственный P-локальный пул, прежде чем искать что-либо еще.
Полную публикацию можно найти здесь: https://victoriametrics.com/blog/go-sync-pool/
-
 Как я могу обрабатывать имена файлов UTF-8 в функциях файловой системы PHP?обработка UTF-8 имен файлов в функциях файловой системы PHP При создании папок, содержащих utf-8, с использованием функции PHP MkDir, вы может...программирование Опубликовано в 2025-03-28
Как я могу обрабатывать имена файлов UTF-8 в функциях файловой системы PHP?обработка UTF-8 имен файлов в функциях файловой системы PHP При создании папок, содержащих utf-8, с использованием функции PHP MkDir, вы может...программирование Опубликовано в 2025-03-28 -
Как вы можете использовать группу по поводу данных в MySQL?pivoting Query Results с использованием группы MySQL by В реляционной базе данных, поворот данных относится к перегруппированию строк и столбц...программирование Опубликовано в 2025-03-28
-
Почему мое фоновое изображение CSS появляется?Устранение неисправностей: CSS Фоновое изображение не отображается Вы столкнулись с проблемой, где ваше фоновое изображение не загружается, не...программирование Опубликовано в 2025-03-28
-
Как я могу эффективно объединить Flexbox и вертикальную прокрутку в макете полной высоты?интеграция Flexbox и вертикального прокрутки в полном макете при работе с приложениями полной высоты может быть распространенным требованием. ...программирование Опубликовано в 2025-03-28
-
Как я могу эффективно создавать словаря, используя понимание Python?Python Dictionary понимание в Python, словарь понимает, предлагает краткий способ создания новых словарей. Хотя они похожи на понимание списков,...программирование Опубликовано в 2025-03-28
-
Как я могу настроить PytesserAct для однозначного распознавания с помощью вывода только для номеров?pytesseract ocr с однозначными цифровыми распознаванием и ограничениями только для номеров ] образец использования Вот пример использовани...программирование Опубликовано в 2025-03-28
-
Почему на моем линейном градиентном фоне есть полосы, и как я могу их исправить?изгнать фоновые полосы из линейного градиента При использовании свойства линейно-градиента для фона вы можете столкнуться с заметными полосами...программирование Опубликовано в 2025-03-28
-
Как проверить, есть ли у объекта конкретный атрибут в Python?Метод для определения атрибута объекта Этот запрос ищет метод для проверки присутствия конкретного атрибута в объекте. Рассмотрим следующий пр...программирование Опубликовано в 2025-03-28
-
Как я могу выполнить команды командной строки, включая изменения каталогов, в Java?выполнить команды командной строки в java задача: выполнение команд командной строки через Java может быть сложной. Хотя вы можете найти ф...программирование Опубликовано в 2025-03-28
-
Почему ввод запроса в POST Захват в PHP, несмотря на действительный код?addressing post запрос неисправность в php в представленном фрагменте кода: action='' intement. Вход из нагламента на нажим. Однако выход ...программирование Опубликовано в 2025-03-28
-
Как обрабатывать пользовательский ввод в полноэкранном эксклюзивном режиме Java?Обработка ввода пользователя в полноэкранном эксклюзивном режиме в Java введение woods режим пассивного рендеринга позволяет использоват...программирование Опубликовано в 2025-03-28
-
Python Read File CSV UnicoDedeCodeError Ultimate Solutionошибка декодирования Unicod Не могу декодировать байты В позиции 2-3: усеченная \ uxxxxxxxxxxxx эта ошибка возникает, когда путь к файлу CSV со...программирование Опубликовано в 2025-03-28
-
Как разрешить ошибку \ "Неверное использование групповой функции \" в MySQL при поиске максимального подсчета?Как получить максимальный счет, используя MySQL В MySQL вы можете столкнуться с проблемой, пытаясь найти максимальный подсчет значений, сгрупп...программирование Опубликовано в 2025-03-28
-
Как загружать файлы с дополнительными параметрами с использованием кодирования Java.net.urlConnection и Multipart/Form Data?загрузка файлов с помощью http-запросов для загрузки файлов на сервер HTTP, в то же время представляя дополнительные параметры, Java.net.urlCo...программирование Опубликовано в 2025-03-28
-
Как `std :: raunder` решить проблемы оптимизации компилятора с членами Const в профсоюзах?раскрыть сущность отмывания памяти: более глубокое погружение в std :: raunder в царстве стандартизации C, P0137 Вводит STD :: Функциональный ...программирование Опубликовано в 2025-03-28















Изучайте китайский
- 1 Как сказать «гулять» по-китайски? 走路 Китайское произношение, 走路 Изучение китайского языка
- 2 Как сказать «Сесть на самолет» по-китайски? 坐飞机 Китайское произношение, 坐飞机 Изучение китайского языка
- 3 Как сказать «сесть на поезд» по-китайски? 坐火车 Китайское произношение, 坐火车 Изучение китайского языка
- 4 Как сказать «поехать на автобусе» по-китайски? 坐车 Китайское произношение, 坐车 Изучение китайского языка
- 5 Как сказать «Ездить» по-китайски? 开车 Китайское произношение, 开车 Изучение китайского языка
- 6 Как будет плавание по-китайски? 游泳 Китайское произношение, 游泳 Изучение китайского языка
- 7 Как сказать «кататься на велосипеде» по-китайски? 骑自行车 Китайское произношение, 骑自行车 Изучение китайского языка
- 8 Как поздороваться по-китайски? 你好Китайское произношение, 你好Изучение китайского языка
- 9 Как сказать спасибо по-китайски? 谢谢Китайское произношение, 谢谢Изучение китайского языка
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









