 титульная страница > программирование > K Регрессия ближайших соседей, Регрессия: контролируемое машинное обучение
титульная страница > программирование > K Регрессия ближайших соседей, Регрессия: контролируемое машинное обучение
K Регрессия ближайших соседей, Регрессия: контролируемое машинное обучение
 Просматривать:952
Просматривать:952
k-регрессия ближайших соседей
Регрессия k-ближайших соседей (k-NN) — это непараметрический метод, который прогнозирует выходное значение на основе среднего (или средневзвешенного) k-ближайших точек обучающих данных в пространстве признаков. Этот подход позволяет эффективно моделировать сложные отношения в данных, не принимая при этом конкретную функциональную форму.
Метод регрессии k-NN можно резюмировать следующим образом:
- Метрика расстояния: алгоритм использует метрику расстояния (обычно евклидово расстояние) для определения «близости» точек данных.
- k Neighbours: параметр k указывает, сколько ближайших соседей следует учитывать при составлении прогнозов.
- Прогноз: прогнозируемое значение для новой точки данных представляет собой среднее значение k ее ближайших соседей.
Ключевые понятия
Непараметрический: В отличие от параметрических моделей, k-NN не принимает определенную форму для базовой взаимосвязи между входными признаками и целевой переменной. Это делает его гибким при захвате сложных шаблонов.
Расчет расстояния: выбор метрики расстояния может существенно повлиять на производительность модели. Общие метрики включают расстояния Евклида, Манхэттена и Минковского.
Выбор k: количество соседей (k) может быть выбрано на основе перекрестной проверки. Маленькое k может привести к переобучению, тогда как большое k может слишком сильно сгладить прогноз, что может привести к недостаточному подгонке.
Пример регрессии k-ближайших соседей
В этом примере показано, как использовать регрессию k-NN с полиномиальными характеристиками для моделирования сложных отношений, используя при этом непараметрическую природу k-NN.
Пример кода Python
1. Импортировать библиотеки
import numpy as np import matplotlib.pyplot as plt from sklearn.model_selection import train_test_split from sklearn.preprocessing import PolynomialFeatures from sklearn.neighbors import KNeighborsRegressor from sklearn.metrics import mean_squared_error, r2_score
Этот блок импортирует необходимые библиотеки для манипулирования данными, построения графиков и машинного обучения.
2. Создать образец данных
np.random.seed(42) # For reproducibility X = np.linspace(0, 10, 100).reshape(-1, 1) y = 3 * X.ravel() np.sin(2 * X.ravel()) * 5 np.random.normal(0, 1, 100)
Этот блок генерирует выборочные данные, представляющие взаимосвязь с некоторым шумом, имитируя изменения реальных данных.
3. Разделить набор данных
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
Этот блок разбивает набор данных на обучающий и тестовый наборы для оценки модели.
4. Создать полиномиальные объекты
degree = 3 # Change this value for different polynomial degrees poly = PolynomialFeatures(degree=degree) X_poly_train = poly.fit_transform(X_train) X_poly_test = poly.transform(X_test)
Этот блок генерирует полиномиальные функции из наборов обучающих и тестовых данных, позволяя модели фиксировать нелинейные зависимости.
5. Создайте и обучите регрессионную модель k-NN
k = 5 # Number of neighbors knn_model = KNeighborsRegressor(n_neighbors=k) knn_model.fit(X_poly_train, y_train)
Этот блок инициализирует регрессионную модель k-NN и обучает ее с использованием полиномиальных функций, полученных из набора обучающих данных.
6. Делайте прогнозы
y_pred = knn_model.predict(X_poly_test)
Этот блок использует обученную модель для прогнозирования на тестовом наборе.
7. Постройте график результатов
plt.figure(figsize=(10, 6))
plt.scatter(X, y, color='blue', alpha=0.5, label='Data Points')
X_grid = np.linspace(0, 10, 1000).reshape(-1, 1)
X_poly_grid = poly.transform(X_grid)
y_grid = knn_model.predict(X_poly_grid)
plt.plot(X_grid, y_grid, color='red', linewidth=2, label=f'k-NN Regression (k={k}, Degree {degree})')
plt.title(f'k-NN Regression (Polynomial Degree {degree})')
plt.xlabel('X')
plt.ylabel('Y')
plt.legend()
plt.grid(True)
plt.show()
Этот блок создает диаграмму рассеяния фактических точек данных в сравнении с прогнозируемыми значениями из модели регрессии k-NN, визуализируя подобранную кривую.
Вывод с k = 1:
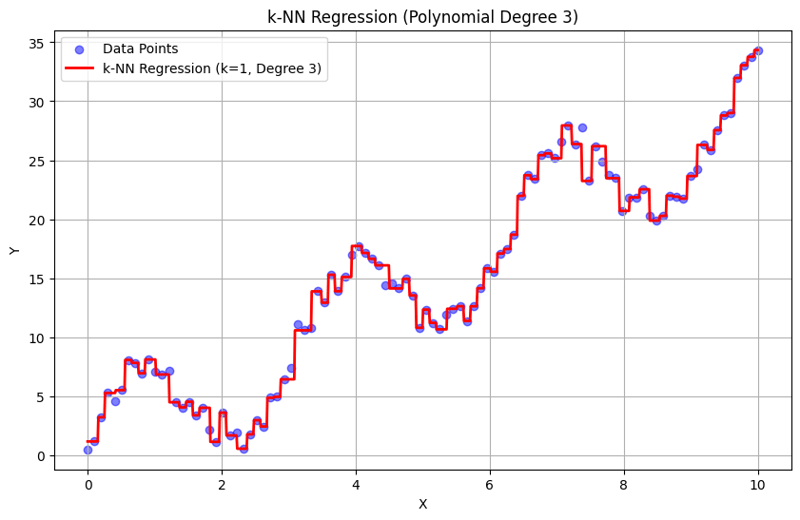
Вывод с k = 10:
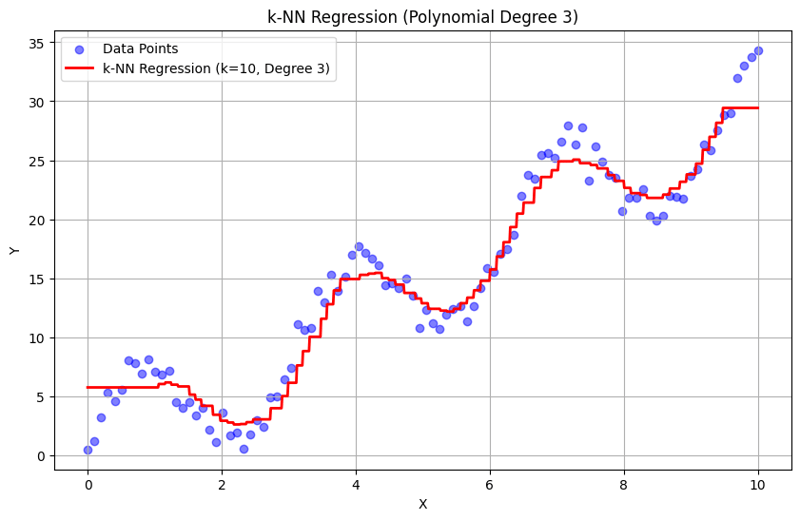
Этот структурированный подход демонстрирует, как реализовать и оценить регрессию k-ближайших соседей с полиномиальными функциями. Улавливая локальные закономерности путем усреднения ответов ближайших соседей, регрессия k-NN эффективно моделирует сложные взаимосвязи в данных, обеспечивая при этом простую реализацию. Выбор k и степени полинома существенно влияет на производительность модели и ее гибкость в выявлении основных тенденций.
-
 Как разрешить расходы на путь модуля в Go Mod с помощью директивы «Заменить»?. с несоответствием пути между импортированным пакетом GO.MOD и фактическим путем импорта. Это может привести к go mod quicley сбои, как продемонс...программирование Опубликовано в 2025-02-07
Как разрешить расходы на путь модуля в Go Mod с помощью директивы «Заменить»?. с несоответствием пути между импортированным пакетом GO.MOD и фактическим путем импорта. Это может привести к go mod quicley сбои, как продемонс...программирование Опубликовано в 2025-02-07 -
Как сортировать данные по длине строки в mySQL с помощью char_length ()?выбор данных по длине строки в mysql для сортировки данных на основе длины строки в mysql, вместо использования string_length (column), рассмо...программирование Опубликовано в 2025-02-07
-
Объект: обложка не удается в IE и Edge, как исправить?object-fit: cover не удастся в IE и Edge, как исправить? В CSS для поддержания постоянной высоты изображения работает беспрепятственно через брау...программирование Опубликовано в 2025-02-07
-
Как правильно вставить Blobs (изображения) в MySQL с помощью PHP?вставьте Blobs в базы данных MySQL с PHP При попытке сохранить изображение в базе данных MySQL, вы можете встретиться с проблема. Это руковод...программирование Опубликовано в 2025-02-07
-
Почему выполнение JavaScript прекращается при использовании кнопки Firefox Back?Проблема истории навигации: Javascript перестает выполнять после использования кнопки Firefox Back пользователи Firefox могут столкнуться с пр...программирование Опубликовано в 2025-02-07
-
Как я могу удалить элемент div, сохраняя его содержимое нетронутым?Устранение Div во время сохранения его элементов для перемещения элементов из -за его внешней части для различных размеров экрана, альтернатив...программирование Опубликовано в 2025-02-07
-
Множествометоды являются FNS, которые можно вызвать на Objects ] Массивы являются объектами, следовательно, они также имеют методы в JS. ] ] Срез (...программирование Опубликовано в 2025-02-07
-
Как реализовать пользовательскую обработку исключений с помощью модуля журнала Python?изготовление пользовательской обработки ошибок с помощью модуля ведения журнала Python обеспечить правильное обработанное и зарегистрированное...программирование Опубликовано в 2025-02-07
-
Как вы можете использовать группу по поводу данных в MySQL?] pivoting Query Results с использованием группы MySQL BY В реляционной базе данных, поворот данных относится к перегруппированию строк и столб...программирование Опубликовано в 2025-02-07
-
Могу ли я использовать SVG в качестве псевдоэлементного контента в CSS?с использованием SVGS в качестве псевдооэлементного содержимо псевдо-элементы, такие как :: до и :: после. Однако были ограничения на то, какой к...программирование Опубликовано в 2025-02-07
-
Как я могу объединить таблицы базы данных с различным числом столбцов?объединенные таблицы с разными столбцами ] может столкнуться с проблемами при попытке объединить таблицы баз данных с разными столбцами. Просто...программирование Опубликовано в 2025-02-07
-
Как я могу надежно проверить наличие столбца в таблице MySQL?определяющий существование столбца в таблице MySQL в MySQL, проверка наличия столбца в таблице может быть немного озадачивающим по сравнению с...программирование Опубликовано в 2025-02-07
-
Как я могу эффективно получить значения атрибутов из файлов XML с помощью PHP?получение значений атрибутов из файлов XML в php каждый разработчик сталкивается с необходимостью проанализировать файлы XML и извлекать опред...программирование Опубликовано в 2025-02-07
-
Как я могу эффективно заменить несколько подстроков в строке Java?заменить несколько подстроков в строку эффективно в Java , когда сталкивается с необходимостью заменить несколько подстроков в строке, это зама...программирование Опубликовано в 2025-02-07
-
Как проверить, есть ли у объекта конкретный атрибут в Python?Метод для определения атрибута объекта Этот запрос ищет метод для проверки присутствия конкретного атрибута в объекте. Рассмотрим следующий пр...программирование Опубликовано в 2025-02-07















Изучайте китайский
- 1 Как сказать «гулять» по-китайски? 走路 Китайское произношение, 走路 Изучение китайского языка
- 2 Как сказать «Сесть на самолет» по-китайски? 坐飞机 Китайское произношение, 坐飞机 Изучение китайского языка
- 3 Как сказать «сесть на поезд» по-китайски? 坐火车 Китайское произношение, 坐火车 Изучение китайского языка
- 4 Как сказать «поехать на автобусе» по-китайски? 坐车 Китайское произношение, 坐车 Изучение китайского языка
- 5 Как сказать «Ездить» по-китайски? 开车 Китайское произношение, 开车 Изучение китайского языка
- 6 Как будет плавание по-китайски? 游泳 Китайское произношение, 游泳 Изучение китайского языка
- 7 Как сказать «кататься на велосипеде» по-китайски? 骑自行车 Китайское произношение, 骑自行车 Изучение китайского языка
- 8 Как поздороваться по-китайски? 你好Китайское произношение, 你好Изучение китайского языка
- 9 Как сказать спасибо по-китайски? 谢谢Китайское произношение, 谢谢Изучение китайского языка
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









