 титульная страница > программирование > Повышение производительности с помощью статического анализа, инициализации изображений и создания моментальных снимков кучи
титульная страница > программирование > Повышение производительности с помощью статического анализа, инициализации изображений и создания моментальных снимков кучи
Повышение производительности с помощью статического анализа, инициализации изображений и создания моментальных снимков кучи
 Просматривать:390
Просматривать:390
От монолитных структур до мира распределенных систем разработка приложений прошла долгий путь. Массовое внедрение облачных вычислений и микросервисной архитектуры существенно изменило подход к созданию и развертыванию серверных приложений. Вместо гигантских серверов приложений теперь у нас есть независимые, индивидуально развернутые сервисы, которые начинают действовать
по мере необходимости.
Однако новым игроком в блоке, который может повлиять на это бесперебойное функционирование, может быть «холодный старт». Холодный старт срабатывает, когда первый запрос обрабатывается на только что созданном работнике. Эта ситуация требует инициализации среды выполнения языка и инициализации конфигурации службы перед обработкой фактического запроса. Непредсказуемость и более медленное выполнение, связанные с холодным запуском, могут нарушить соглашения об уровне обслуживания облачной службы. Итак, как можно противостоять этому растущему беспокойству?
Собственный образ: оптимизация времени запуска и объема памяти
Для борьбы с неэффективностью холодного запуска был разработан новый подход, включающий анализ точек на, инициализацию приложения во время сборки, создание моментальных снимков кучи и упреждающую (AOT) компиляцию. Этот метод работает в предположении закрытого мира, требуя, чтобы все классы Java были предопределены и доступны во время сборки. На этом этапе комплексный анализ точек определяет все доступные элементы программы (классы, методы, поля), чтобы гарантировать, что компилируются только необходимые методы Java.
Код инициализации приложения может выполняться в процессе сборки, а не во время выполнения. Это позволяет предварительно выделять объекты Java и создавать сложные структуры данных, которые затем становятся доступными во время выполнения через «кучу изображений». Эта куча изображений интегрирована в исполняемый файл, обеспечивая немедленную доступность при запуске приложения.
итеративное выполнение анализа точек и создания снимков продолжается до тех пор, пока не будет достигнуто стабильное состояние (фиксированная точка), оптимизируя как время запуска, так и потребление ресурсов.
Подробный рабочий процесс
Вводными данными для нашей системы является байт-код Java, который может быть взят из таких языков, как Java, Scala или Kotlin. В этом процессе приложение, его библиотеки, JDK и компоненты виртуальной машины обрабатываются единообразно для создания собственного исполняемого файла, специфичного для операционной системы и архитектуры, называемого «собственным образом». Процесс построения включает в себя итеративный анализ точек и создание снимков кучи до тех пор, пока не будет достигнута фиксированная точка, что позволяет приложению активно участвовать посредством зарегистрированных обратных вызовов. Эти шаги вместе называются процессом создания собственного образа (Рис. 1)
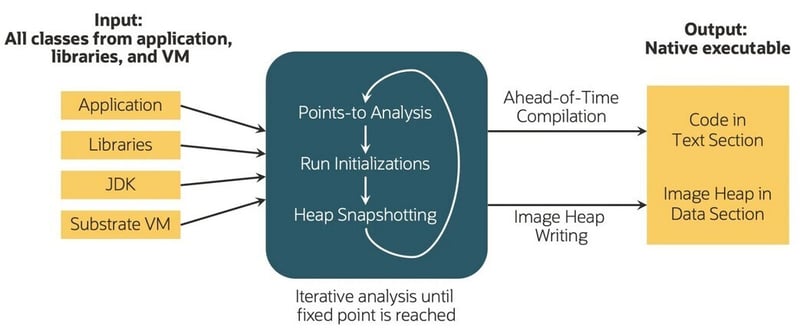
Рис. 1. Процесс создания собственного образа (источник: redhat.com)
Точки для анализа
Мы используем точечный анализ, чтобы убедиться в достижимости классов, методов и полей во время выполнения. Анализ точек к начинается со всех точек входа, таких как основной метод приложения, и итеративно обходит все транзитивно достижимые методы, пока не достигнет фиксированной точки (Рисунок 2).
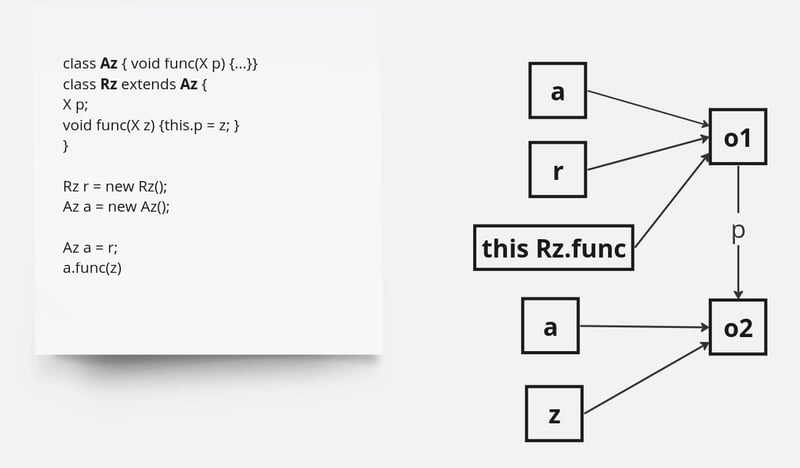
Рис. 2. Объекты для анализа
Наш точечный анализ использует интерфейс нашего компилятора для анализа байт-кода Java в высокоуровневом промежуточном представлении компилятора (IR). Впоследствии IR преобразуется в граф типа потока. В этом графе узлы представляют инструкции, работающие с типами объектов, а ребра обозначают ребра направленного использования между узлами, указывающие от определения к использованию. Каждый узел поддерживает состояние типа, состоящее из списка типов, которые могут достигать узла, и информации о недействительности. Состояния типов распространяются через ребра использования; если состояние типа узла изменяется, это изменение распространяется на все способы использования. Важно отметить, что состояния типов могут только расширяться; новые типы могут быть добавлены в состояние типа, но существующие типы никогда не удаляются. Этот механизм гарантирует, что
анализ в конечном итоге сходится к фиксированной точке, что приводит к завершению.
Запустите код инициализации
Анализ точек на направляет выполнение кода инициализации, когда он достигает локальной фиксированной точки. Этот код берет свое начало в двух отдельных источниках: инициализаторах классов и пакете пользовательского кода, выполняемом во время сборки через функциональный интерфейс:
Инициализаторы классов: Каждый класс Java может иметь инициализатор класса, указанный методом
, который инициализирует статические поля. Разработчики могут выбирать, какие классы инициализировать во время сборки, а не во время выполнения. Явные обратные вызовы: Разработчики могут реализовывать собственный код с помощью перехватчиков, предоставляемых нашей системой, выполняющихся до, во время или после этапов анализа.
Вот API-интерфейсы, предоставляемые для интеграции с нашей системой.
Пассивный API (запрашивает текущий статус анализа)
boolean isReachable(Class> clazz); boolean isReachable(Field field); boolean isReachable(Executable method);
Для получения дополнительной информации обратитесь к QueryReachabilityAccess
Активный API (регистрирует обратные вызовы для изменения статуса анализа):
void registerReachabilityHandler(Consumercallback, Object... elements); void registerSubtypeReachabilityHandler(BiConsumer > callback, Class> baseClass); void registerMethodOverrideReachabilityHandler(BiConsumer callback, Executable baseMethod);
Для получения дополнительной информации см. раздел BeforeAnalysisAccess
На этом этапе приложение может выполнять собственный код, например выделение объектов и инициализацию более крупных структур данных. Важно отметить, что код инициализации может получить доступ к текущему состоянию анализа точек, позволяя запрашивать доступность типов, методов или полей. Это достигается с помощью различных методов isReachable(), предоставляемых во время анализаAccess. Используя эту информацию, приложение может создавать структуры данных, оптимизированные для доступных сегментов приложения.
Снимки кучи
Наконец, создание снимков кучи создает граф объектов, следуя корневым указателям, таким как статические поля, для создания комплексного представления всех доступных объектов. Затем этот график заполняет исходное изображение
куча изображений, обеспечивающая эффективную загрузку исходного состояния приложения при запуске.
Чтобы сгенерировать транзитивное замыкание достижимых объектов, алгоритм обходит поля объекта, считывая их значения с помощью отражения. Очень важно отметить, что построитель образов работает в среде Java. Во время этого обхода учитываются только поля экземпляров, помеченные как «прочитанные» при анализе точек на. Например, если класс имеет два поля экземпляра, но одно из них не помечено как прочитанное, объект, доступный через неотмеченное поле, исключается из кучи изображений.
При обнаружении значения поля, класс которого ранее не был идентифицирован анализом точек на, этот класс регистрируется как тип поля. Эта регистрация гарантирует, что в последующих итерациях анализа точек новый тип будет распространяться на все чтения полей и транзитивные использования в графе потока типов.
Приведенный ниже фрагмент кода описывает основной алгоритм создания моментальных снимков кучи:
Declare List worklist := []
Declare Set reachableObjects := []
Function BuildHeapSnapshot(PointsToState pointsToState)
For Each field in pointsToState.getReachableStaticObjectFields()
Call AddObjectToWorkList(field.readValue())
End For
For Each method in pointsToState.getReachableMethods()
For Each constant in method.embeddedConstants()
Call AddObjectToWorkList(constant)
End For
End For
While worklist.isNotEmpty
Object current := Pop from worklist
If current Object is an Array
For Each value in current
Call AddObjectToWorkList(value)
Add current.getClass() to pointsToState.getObjectArrayTypes()
End For
Else
For Each field in pointsToState.getReachableInstanceObjectFields(current.getClass())
Object value := field.read(current)
Call AddObjectToWorkList(value)
Add value.getClass() to pointsToState.getFieldValueTypes(field)
End For
End If
End While
Return reachableObjects
End Function
Подводя итог, можно сказать, что алгоритм создания снимков кучи эффективно создает снимок кучи путем систематического обхода доступных объектов и их полей. Это гарантирует, что в кучу изображения будут включены только соответствующие объекты, оптимизируя производительность и объем памяти исходного образа.
Заключение
В заключение, процесс создания снимков кучи играет решающую роль в создании собственных образов. Систематически просматривая доступные объекты и их поля, алгоритм создания снимков кучи создает граф объектов, который представляет собой транзитивное замыкание доступных объектов из корневых указателей, таких как статические поля. Этот граф объектов затем встраивается в собственное изображение в виде кучи изображений, служащей начальной кучей при запуске собственного образа.
На протяжении всего процесса алгоритм опирается на состояние анализа точек, чтобы определить, какие объекты и поля подходят для включения в кучу изображений. Объекты и поля, помеченные как «прочитанные» при анализе точек на, учитываются, а неотмеченные сущности исключаются. Кроме того, при обнаружении ранее неизвестных типов алгоритм регистрирует их для распространения в последующих итерациях анализа точек.
В целом, создание снимков кучи оптимизирует производительность и использование памяти собственными изображениями, гарантируя, что в кучу изображений включаются только необходимые объекты. Такой системный подход повышает эффективность и надежность выполнения собственных изображений.
-
 Как проверить, есть ли у объекта конкретный атрибут в Python?Метод для определения атрибута объекта Этот запрос ищет метод для проверки присутствия конкретного атрибута в объекте. Рассмотрим следующий пр...программирование Опубликовано в 2025-03-15
Как проверить, есть ли у объекта конкретный атрибут в Python?Метод для определения атрибута объекта Этот запрос ищет метод для проверки присутствия конкретного атрибута в объекте. Рассмотрим следующий пр...программирование Опубликовано в 2025-03-15 -
Могу ли я перенести свой шифрование с McRypt в OpenSSL и расшифровывает данные, заполненные McRypt, используя OpenSSL?Обновление моей библиотеки шифрования с McRypt до OpenSSL Могу ли я обновить свою библиотеку шифрования с McRypt до OpenSSL? В OpenSSL можно л...программирование Опубликовано в 2025-03-15
-
Python Read File CSV UnicoDedeCodeError Ultimate Solutionошибка декодирования Unicod Не могу декодировать байты В позиции 2-3: усеченная \ uxxxxxxxxxxxx эта ошибка возникает, когда путь к файлу CSV со...программирование Опубликовано в 2025-03-15
-
Можно ли сложить несколько липких элементов друг на друга в чистых CSS?возможно ли иметь несколько липких элементов, сложенных друг на друга в чистом CSS? Здесь: https://webthemez.com/demo/sticky-multi-heand-scroll/...программирование Опубликовано в 2025-03-15
-
Каковы были ограничения на использование current_timestamp с столбцами TimeStamp в MySQL до версии 5.6.5?Restrictions on TIMESTAMP Columns with CURRENT_TIMESTAMP in DEFAULT or ON UPDATE Clauses in MySQL Versions Prior to 5.6.5Historically, in MySQL versio...программирование Опубликовано в 2025-03-15
-
Как вы можете использовать группу по поводу данных в MySQL?pivoting Query Results с использованием группы MySQL by В реляционной базе данных, поворот данных относится к перегруппированию строк и столбц...программирование Опубликовано в 2025-03-15
-
Как я могу объединить таблицы базы данных с различным числом столбцов?объединенные таблицы с разными столбцами ] может столкнуться с проблемами при попытке объединить таблицы баз данных с разными столбцами. Просто...программирование Опубликовано в 2025-03-15
-
Как эффективно получить последнюю строку для каждого уникального идентификатора в PostgreSQL?postgresql: извлечение последней строки для каждого уникального идентификатора В Postgresql вы можете столкнуться с ситуациями, где вам необхо...программирование Опубликовано в 2025-03-15
-
Почему Microsoft Visual C ++ не может правильно реализовать двухфазной экземпляры?загадка «Сломанная» двухфазное матричное экземпляры в Microsoft Visual C Задача задачи: пользователи обычно выражают обеспокоенность Microso...программирование Опубликовано в 2025-03-15
-
Существует ли разница в производительности между использованием зала и итератора для сбора сбора в Java?для каждого цикла против итератора: эффективность в сборе Traversal введение при переселении коллекции в Java, выборе между использованием...программирование Опубликовано в 2025-03-15
-
Как динамически установить клавиши в объектах JavaScript?Как создать динамический ключ для переменной объекта Javascript при попытке создать динамический ключ для объекта Javascript, используя этот син...программирование Опубликовано в 2025-03-15
-
Почему мое фоновое изображение CSS появляется?Устранение неисправностей: CSS Фоновое изображение не отображается Вы столкнулись с проблемой, где ваше фоновое изображение не загружается, не...программирование Опубликовано в 2025-03-15
-
Как снять анонимные обработчики событий JavaScript чисто?] удаление слушателей анонимных событий добавление слушателей анонимных событий в элементы обеспечивают гибкость и простоту, но когда пришло врем...программирование Опубликовано в 2025-03-15
-
Как я могу эффективно заменить несколько подстроков в строке Java?заменить несколько подстроков в строку эффективно в Java , когда сталкивается с необходимостью заменить несколько подстроков в строке, это зама...программирование Опубликовано в 2025-03-15
-
Как разрешить расходы на путь модуля в Go Mod с помощью директивы «Заменить»?Распространение пути преодоления модуля в Go Mod При использовании MOD можно столкнуться с конфликтом, где 3 -й пакет импортирует другой пакет...программирование Опубликовано в 2025-03-15















Изучайте китайский
- 1 Как сказать «гулять» по-китайски? 走路 Китайское произношение, 走路 Изучение китайского языка
- 2 Как сказать «Сесть на самолет» по-китайски? 坐飞机 Китайское произношение, 坐飞机 Изучение китайского языка
- 3 Как сказать «сесть на поезд» по-китайски? 坐火车 Китайское произношение, 坐火车 Изучение китайского языка
- 4 Как сказать «поехать на автобусе» по-китайски? 坐车 Китайское произношение, 坐车 Изучение китайского языка
- 5 Как сказать «Ездить» по-китайски? 开车 Китайское произношение, 开车 Изучение китайского языка
- 6 Как будет плавание по-китайски? 游泳 Китайское произношение, 游泳 Изучение китайского языка
- 7 Как сказать «кататься на велосипеде» по-китайски? 骑自行车 Китайское произношение, 骑自行车 Изучение китайского языка
- 8 Как поздороваться по-китайски? 你好Китайское произношение, 你好Изучение китайского языка
- 9 Как сказать спасибо по-китайски? 谢谢Китайское произношение, 谢谢Изучение китайского языка
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









