 титульная страница > программирование > Полный рабочий процесс машинного обучения с помощью Scikit-Learn: прогнозирование цен на жилье в Калифорнии
титульная страница > программирование > Полный рабочий процесс машинного обучения с помощью Scikit-Learn: прогнозирование цен на жилье в Калифорнии
Полный рабочий процесс машинного обучения с помощью Scikit-Learn: прогнозирование цен на жилье в Калифорнии
 Просматривать:235
Просматривать:235
Введение
В этой статье мы продемонстрируем полный рабочий процесс проекта машинного обучения с использованием Scikit-Learn. Мы построим модель для прогнозирования цен на жилье в Калифорнии на основе различных характеристик, таких как средний доход, возраст дома и среднее количество комнат. Этот проект проведет вас через каждый этап процесса, включая загрузку данных, исследование, обучение модели, оценку и визуализацию результатов. Независимо от того, являетесь ли вы новичком, желающим понять основы, или опытным практиком, желающим повысить свою квалификацию, эта статья предоставит ценную информацию о практическом применении методов машинного обучения.
Проект прогнозирования цен на жилье в Калифорнии
1. Введение
Рынок жилья Калифорнии известен своими уникальными характеристиками и динамикой цен. В этом проекте мы стремимся разработать модель машинного обучения для прогнозирования цен на жилье на основе различных функций. Мы будем использовать набор данных о жилье в Калифорнии, который включает в себя различные атрибуты, такие как средний доход, возраст дома, среднее количество комнат и многое другое.
2. Импорт библиотек
В этом разделе мы импортируем необходимые библиотеки для манипулирования данными, визуализации и построения нашей модели машинного обучения.
import pandas as pd import matplotlib.pyplot as plt from sklearn.model_selection import train_test_split from sklearn.linear_model import LinearRegression from sklearn.metrics import mean_squared_error from sklearn.datasets import fetch_california_housing
3. Загрузка набора данных
Мы загрузим набор данных о жилье в Калифорнии и создадим DataFrame для организации данных. Целевая переменная, то есть цена дома, будет добавлена в новый столбец.
# Load the California Housing dataset california = fetch_california_housing() df = pd.DataFrame(california.data, columns=california.feature_names) df['PRICE'] = california.target
4. Случайный выбор образцов
Чтобы обеспечить управляемость анализа, мы случайным образом выберем 700 образцов из набора данных для нашего исследования.
# Randomly Selecting 700 Samples df_sample = df.sample(n=700, random_state=42)
5. Анализ наших данных
В этом разделе представлен обзор набора данных с отображением первых пяти строк, чтобы понять особенности и структуру наших данных.
# Overview of the data
print("First five rows of the dataset:")
print(df_sample.head())
Выход
First five rows of the dataset:
MedInc HouseAge AveRooms AveBedrms Population AveOccup Latitude \
20046 1.6812 25.0 4.192201 1.022284 1392.0 3.877437 36.06
3024 2.5313 30.0 5.039384 1.193493 1565.0 2.679795 35.14
15663 3.4801 52.0 3.977155 1.185877 1310.0 1.360332 37.80
20484 5.7376 17.0 6.163636 1.020202 1705.0 3.444444 34.28
9814 3.7250 34.0 5.492991 1.028037 1063.0 2.483645 36.62
Longitude PRICE
20046 -119.01 0.47700
3024 -119.46 0.45800
15663 -122.44 5.00001
20484 -118.72 2.18600
9814 -121.93 2.78000
Отображение информации о кадре данных
print(df_sample.info())
Выход
Index: 700 entries, 20046 to 5350 Data columns (total 9 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 MedInc 700 non-null float64 1 HouseAge 700 non-null float64 2 AveRooms 700 non-null float64 3 AveBedrms 700 non-null float64 4 Population 700 non-null float64 5 AveOccup 700 non-null float64 6 Latitude 700 non-null float64 7 Longitude 700 non-null float64 8 PRICE 700 non-null float64 dtypes: float64(9) memory usage: 54.7 KB
Отображение сводной статистики
print(df_sample.describe())
Выход
MedInc HouseAge AveRooms AveBedrms Population \
count 700.000000 700.000000 700.000000 700.000000 700.000000
mean 3.937653 28.855714 5.404192 1.079266 1387.422857
std 2.085831 12.353313 1.848898 0.236318 1027.873659
min 0.852700 2.000000 2.096692 0.500000 8.000000
25% 2.576350 18.000000 4.397751 1.005934 781.000000
50% 3.480000 30.000000 5.145295 1.047086 1159.500000
75% 4.794625 37.000000 6.098061 1.098656 1666.500000
max 15.000100 52.000000 36.075472 5.273585 8652.000000
AveOccup Latitude Longitude PRICE
count 700.000000 700.000000 700.000000 700.000000
mean 2.939913 35.498243 -119.439729 2.082073
std 0.745525 2.123689 1.956998 1.157855
min 1.312994 32.590000 -124.150000 0.458000
25% 2.457560 33.930000 -121.497500 1.218500
50% 2.834524 34.190000 -118.420000 1.799000
75% 3.326869 37.592500 -118.007500 2.665500
max 7.200000 41.790000 -114.590000 5.000010
6. Разделение набора данных на обучающий и тестовый наборы
Мы разделим набор данных на функции (X) и целевую переменную (y), а затем разделим его на обучающий и тестовый наборы для обучения и оценки модели.
# Splitting the dataset into Train and Test sets
X = df_sample.drop('PRICE', axis=1) # Features
y = df_sample['PRICE'] # Target variable
# Split the dataset into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
7. Модельное обучение
В этом разделе мы создадим и обучим модель линейной регрессии, используя обучающие данные, чтобы изучить взаимосвязь между функциями и ценами на жилье.
# Creating and training the Linear Regression model lr = LinearRegression() lr.fit(X_train, y_train)
8. Оценка модели
Мы сделаем прогнозы на тестовом наборе и рассчитаем среднеквадратическую ошибку (MSE) и значения R-квадрата, чтобы оценить производительность модели.
# Making predictions on the test set
y_pred = lr.predict(X_test)
# Calculating Mean Squared Error
mse = mean_squared_error(y_test, y_pred)
print(f"\nLinear Regression Mean Squared Error: {mse}")
Выход
Linear Regression Mean Squared Error: 0.3699851092128846
9. Отображение фактических и прогнозируемых значений
Здесь мы создадим DataFrame для сравнения фактических цен на жилье с прогнозируемыми ценами, сгенерированными нашей моделью.
# Displaying Actual vs Predicted Values
results = pd.DataFrame({'Actual Prices': y_test.values, 'Predicted Prices': y_pred})
print("\nActual vs Predicted:")
print(results)
Выход
Actual vs Predicted:
Actual Prices Predicted Prices
0 0.87500 0.887202
1 1.19400 2.445412
2 5.00001 6.249122
3 2.78700 2.743305
4 1.99300 2.794774
.. ... ...
135 1.62100 2.246041
136 3.52500 2.626354
137 1.91700 1.899090
138 2.27900 2.731436
139 1.73400 2.017134
[140 rows x
2 columns]
10. Визуализация результатов
В последнем разделе мы визуализируем взаимосвязь между фактическими и прогнозируемыми ценами на жилье, используя диаграмму рассеяния, чтобы визуально оценить эффективность модели.
# Visualizing the Results
plt.figure(figsize=(8, 6))
plt.scatter(y_test, y_pred, color='blue')
plt.xlabel('Actual Prices')
plt.ylabel('Predicted Prices')
plt.title('Actual vs Predicted House Prices')
# Draw the ideal line
plt.plot([0, 6], [0, 6], color='red', linestyle='--')
# Set limits to minimize empty space
plt.xlim(y_test.min() - 1, y_test.max() 1)
plt.ylim(y_test.min() - 1, y_test.max() 1)
plt.grid()
plt.show()
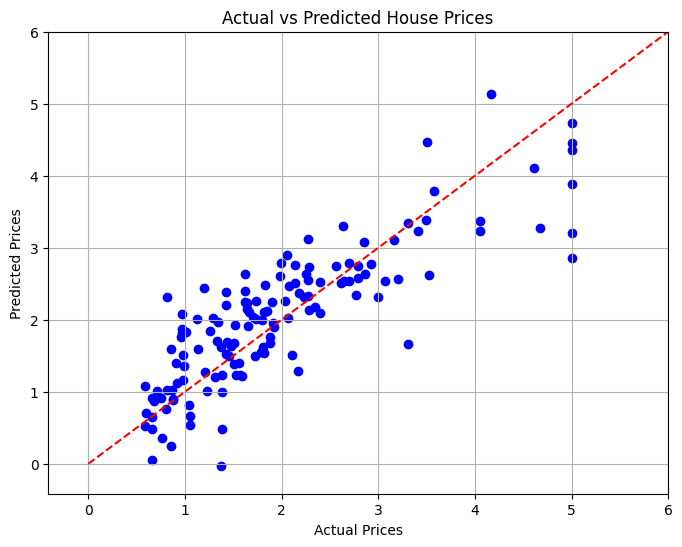
Заключение
В этом проекте мы разработали модель линейной регрессии для прогнозирования цен на жилье в Калифорнии на основе различных характеристик. Среднеквадратическая ошибка была рассчитана для оценки производительности модели, что обеспечило количественную меру точности прогноза. С помощью визуализации мы смогли увидеть, насколько хорошо наша модель работает по сравнению с фактическими значениями.
Этот проект демонстрирует возможности машинного обучения в аналитике недвижимости и может служить основой для более продвинутых методов прогнозного моделирования.
-
 Почему ввод запроса в POST Захват в PHP, несмотря на действительный код?addressing post запрос неисправность в php в представленном фрагменте кода: action='' intement. Вход из нагламента на нажим. Однако выход ...программирование Опубликовано в 2025-04-07
Почему ввод запроса в POST Захват в PHP, несмотря на действительный код?addressing post запрос неисправность в php в представленном фрагменте кода: action='' intement. Вход из нагламента на нажим. Однако выход ...программирование Опубликовано в 2025-04-07 -
Eval () против AST.Literal_EVAL (): какая функция Python безопаснее для пользовательского ввода?взвешивание eval () и ast.literal_eval () в Python Security при обращении с вводом пользователя, это необходимо определить определение безопас...программирование Опубликовано в 2025-04-07
-
Почему на моем линейном градиентном фоне есть полосы, и как я могу их исправить?изгнать фоновые полосы из линейного градиента При использовании свойства линейно-градиента для фона вы можете столкнуться с заметными полосами...программирование Опубликовано в 2025-04-07
-
Как я могу эффективно заменить несколько подстроков в строке Java?заменить несколько подстроков в строку эффективно в Java , когда сталкивается с необходимостью заменить несколько подстроков в строке, это зама...программирование Опубликовано в 2025-04-07
-
Как объединить данные из трех таблиц MySQL в новую таблицу?mySQL: Creating a New Table from Data and Columns of Three TablesQuestion:How can I create a new table that combines selected data from three existing...программирование Опубликовано в 2025-04-07
-
Как я могу эффективно генерировать удобные для URL слизняки из строк Unicode в PHP?создание функции для эффективной генерации Slug Создание слизняков, упрощенные представления строк Unicode, используемые в URL, может быть сло...программирование Опубликовано в 2025-04-07
-
Как я могу настроить оптимизацию компиляции в компиляторе GO?настройка оптимизации компиляции в GO Compiler процесс компиляции по умолчанию в GO следует за конкретной стратегией оптимизации. Однако польз...программирование Опубликовано в 2025-04-07
-
Как ограничить диапазон прокрутки элемента в родительском элементе динамического размера?реализация пределов высоты CSS для вертикальных элементов прокрутки В интерактивном интерфейсе, контроль над поведением прокрутки элементов яв...программирование Опубликовано в 2025-04-07
-
Как обойти блоки веб -сайтов с помощью запросов Python и фальшивых пользовательских агентов?Как смоделировать поведение браузера с помощью запросов Python и фальшивых пользовательских агентов библиотеки Python - это мощный инструмент ...программирование Опубликовано в 2025-04-07
-
\ "В то время как (1) против (;;): Оптимизация компилятора исключает различия в производительности? \"while (1) vs. for (;;;): существует ли разница в скорости? ] Вопрос: . Использование (1) вместо (;) петли? Компиляторы: ] perl: как (1)...программирование Опубликовано в 2025-04-07
-
Как я могу синхронно повторять и печатать значения из двух массивов одинакового размера в PHP?синхронно итерационные и печатные значения из двух массивов одного и того же размера при создании Selectbox с использованием двух массивов одина...программирование Опубликовано в 2025-04-07
-
Как вы можете использовать группу по поводу данных в MySQL?pivoting Query Results с использованием группы MySQL by В реляционной базе данных, поворот данных относится к перегруппированию строк и столбц...программирование Опубликовано в 2025-04-07
-
Как разрешить расходы на путь модуля в Go Mod с помощью директивы «Заменить»?Распространение пути преодоления модуля в Go Mod При использовании MOD можно столкнуться с конфликтом, где 3 -й пакет импортирует другой пакет...программирование Опубликовано в 2025-04-07
-
Как правильно использовать как запросы с параметрами PDO?Использование подобных запросов в PDO При попытке реализовать подобные запросы в PDO, вы можете столкнуться с проблемами, подобными тем, котор...программирование Опубликовано в 2025-04-07
-
Как эффективно получить последнюю строку для каждого уникального идентификатора в PostgreSQL?postgresql: извлечение последней строки для каждого уникального идентификатора В Postgresql вы можете столкнуться с ситуациями, где вам необхо...программирование Опубликовано в 2025-04-07















Изучайте китайский
- 1 Как сказать «гулять» по-китайски? 走路 Китайское произношение, 走路 Изучение китайского языка
- 2 Как сказать «Сесть на самолет» по-китайски? 坐飞机 Китайское произношение, 坐飞机 Изучение китайского языка
- 3 Как сказать «сесть на поезд» по-китайски? 坐火车 Китайское произношение, 坐火车 Изучение китайского языка
- 4 Как сказать «поехать на автобусе» по-китайски? 坐车 Китайское произношение, 坐车 Изучение китайского языка
- 5 Как сказать «Ездить» по-китайски? 开车 Китайское произношение, 开车 Изучение китайского языка
- 6 Как будет плавание по-китайски? 游泳 Китайское произношение, 游泳 Изучение китайского языка
- 7 Как сказать «кататься на велосипеде» по-китайски? 骑自行车 Китайское произношение, 骑自行车 Изучение китайского языка
- 8 Как поздороваться по-китайски? 你好Китайское произношение, 你好Изучение китайского языка
- 9 Как сказать спасибо по-китайски? 谢谢Китайское произношение, 谢谢Изучение китайского языка
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









