
Vá para sync.Pool e a mecânica por trás dele
 Navegar:208
Navegar:208
Este é um trecho da postagem; a postagem completa está disponível aqui: https://victoriametrics.com/blog/go-sync-pool/
Esta postagem faz parte de uma série sobre como lidar com a simultaneidade em Go:
- Go sync.Mutex: Modo Normal e de Fome
- Go sync.WaitGroup e o problema de alinhamento
- Go sync.Pool e a mecânica por trás dele (estamos aqui)
- Go sync.Cond, o mecanismo de sincronização mais negligenciado
No código-fonte do VictoriaMetrics, usamos muito o sync.Pool e, honestamente, é uma ótima opção para como lidamos com objetos temporários, especialmente buffers de bytes ou fatias.
É comumente usado na biblioteca padrão. Por exemplo, no pacote encoding/json:
package json
var encodeStatePool sync.Pool
// An encodeState encodes JSON into a bytes.Buffer.
type encodeState struct {
bytes.Buffer // accumulated output
ptrLevel uint
ptrSeen map[any]struct{}
}
Neste caso,sync.Pool está sendo usado para reutilizar objetos *encodeState, que lidam com o processo de codificação JSON em um bytes.Buffer.
Em vez de apenas jogar esses objetos após cada uso, o que só daria mais trabalho ao coletor de lixo, nós os armazenamos em um pool (sync.Pool). Na próxima vez que precisarmos de algo semelhante, basta pegá-lo na piscina em vez de fazer um novo do zero.
Você também encontrará várias instâncias de sync.Pool no pacote net/http, que são usadas para otimizar operações de E/S:
package http
var (
bufioReaderPool sync.Pool
bufioWriter2kPool sync.Pool
bufioWriter4kPool sync.Pool
)
Quando o servidor lê corpos de solicitações ou grava respostas, ele pode extrair rapidamente um leitor ou gravador pré-alocado desses pools, ignorando alocações extras. Além disso, os dois pools de gravadores, *bufioWriter2kPool e *bufioWriter4kPool, são configurados para lidar com diferentes necessidades de gravação.
func bufioWriterPool(size int) *sync.Pool {
switch size {
case 2
Tudo bem, já chega da introdução.
Hoje, estamos nos aprofundando no que é o sync.Pool, a definição, como ele é usado, o que está acontecendo nos bastidores e tudo o mais que você possa querer saber.
A propósito, se você quiser algo mais prático, há um bom artigo de nossos especialistas em Go mostrando como usamos o sync.Pool no VictoriaMetrics: Técnicas de otimização de desempenho em bancos de dados de séries temporais: sync.Pool para operações vinculadas à CPU
O que é sincronização.Pool?
Simplificando, sync.Pool in Go é um lugar onde você pode manter objetos temporários para reutilização posterior.
Mas o problema é o seguinte: você não controla quantos objetos ficam na piscina, e qualquer coisa que você colocar lá pode ser removida a qualquer momento, sem qualquer aviso e você saberá o porquê ao ler a última seção.
O ponto positivo é que o pool foi construído para ser thread-safe, de modo que vários goroutines podem acessá-lo simultaneamente. Não é uma grande surpresa, considerando que faz parte do pacote de sincronização.
"Mas por que nos preocupamos em reutilizar objetos?"
Quando você tem muitas goroutines em execução ao mesmo tempo, elas geralmente precisam de objetos semelhantes. Imagine executar go f() várias vezes simultaneamente.
Se cada goroutine criar seus próprios objetos, o uso de memória pode aumentar rapidamente e isso sobrecarrega o coletor de lixo, pois ele precisa limpar todos esses objetos quando eles não forem mais necessários.
Essa situação cria um ciclo em que a alta simultaneidade leva ao alto uso de memória, o que torna o coletor de lixo mais lento. O sync.Pool foi projetado para ajudar a quebrar esse ciclo.
type Object struct {
Data []byte
}
var pool sync.Pool = sync.Pool{
New: func() any {
return &Object{
Data: make([]byte, 0, 1024),
}
},
}
Para criar um pool, você pode fornecer uma função New() que retorna um novo objeto quando o pool está vazio. Esta função é opcional, se você não fornecer, o pool apenas retornará nulo se estiver vazio.
No trecho acima, o objetivo é reutilizar a instância da estrutura Object, especificamente a fatia dentro dela.
Reutilizar a fatia ajuda a reduzir o crescimento desnecessário.
Por exemplo, se a fatia crescer para 8.192 bytes durante o uso, você poderá redefinir seu comprimento para zero antes de colocá-la novamente no pool. A matriz subjacente ainda tem capacidade de 8.192, portanto, da próxima vez que você precisar dela, esses 8.192 bytes estarão prontos para serem reutilizados.
func (o *Object) Reset() {
o.Data = o.Data[:0]
}
func main() {
testObject := pool.Get().(*Object)
// do something with testObject
testObject.Reset()
pool.Put(testObject)
}
O fluxo é bastante claro: você pega um objeto do pool, usa-o, reinicia-o e depois o coloca de volta no pool. A redefinição do objeto pode ser feita antes de colocá-lo de volta ou logo após retirá-lo do pool, mas não é obrigatório, é uma prática comum.
Se você não gosta de usar asserções de tipo pool.Get().(*Object), existem algumas maneiras de evitá-lo:
- Use uma função dedicada para obter o objeto do pool:
func getObjectFromPool() *Object {
obj := pool.Get().(*Object)
return obj
}
- Crie sua própria versão genérica de sync.Pool:
type Pool[T any] struct {
sync.Pool
}
func (p *Pool[T]) Get() T {
return p.Pool.Get().(T)
}
func (p *Pool[T]) Put(x T) {
p.Pool.Put(x)
}
func NewPool[T any](newF func() T) *Pool[T] {
return &Pool[T]{
Pool: sync.Pool{
New: func() interface{} {
return newF()
},
},
}
}
O wrapper genérico oferece uma maneira mais segura de trabalhar com o pool, evitando asserções de tipo.
Observe que isso adiciona um pouco de sobrecarga devido à camada extra de indireção. Na maioria dos casos, essa sobrecarga é mínima, mas se você estiver em um ambiente altamente sensível à CPU, é uma boa ideia executar benchmarks para ver se vale a pena.
Mas espere, tem mais do que isso.
sync.Pool e armadilha de alocação
Se você notou em muitos exemplos anteriores, incluindo aqueles na biblioteca padrão, o que armazenamos no pool normalmente não é o objeto em si, mas um ponteiro para o objeto.
Deixe-me explicar o porquê com um exemplo:
var pool = sync.Pool{
New: func() any {
return []byte{}
},
}
func main() {
bytes := pool.Get().([]byte)
// do something with bytes
_ = bytes
pool.Put(bytes)
}
Estamos usando um pool de []byte. Geralmente (embora nem sempre), quando você passa um valor para uma interface, isso pode fazer com que o valor seja colocado no heap. Isso acontece aqui também, não apenas com fatias, mas com qualquer coisa que você passe para pool.Put() que não seja um ponteiro.
Se você verificar usando análise de escape:
// escape analysis $ go build -gcflags=-m bytes escapes to heap
Agora, eu não digo que nossos bytes variáveis se movem para o heap, eu diria "o valor dos bytes escapa para o heap através da interface".
Para realmente entender por que isso acontece, precisaríamos nos aprofundar em como funciona a análise de escape (o que poderemos fazer em outro artigo). No entanto, se passarmos um ponteiro para pool.Put(), não haverá alocação extra:
var pool = sync.Pool{
New: func() any {
return new([]byte)
},
}
func main() {
bytes := pool.Get().(*[]byte)
// do something with bytes
_ = bytes
pool.Put(bytes)
}
Execute a análise de escape novamente, você verá que não há mais escapes para a pilha. Se você quiser saber mais, há um exemplo no código-fonte Go.
sincronizar.Pool Internos
Antes de entrarmos em como o sync.Pool realmente funciona, vale a pena entender os fundamentos do modelo de agendamento PMG do Go, esta é realmente a espinha dorsal do motivo pelo qual o sync.Pool é tão eficiente.
Há um bom artigo que detalha o modelo PMG com alguns recursos visuais: Modelos PMG em Go
Se você está com preguiça hoje e procurando um resumo simplificado, eu estou te protegendo:
PMG significa P (processores lógicos), M (mthreads de máquina) e G (goroutines). O ponto principal é que cada processador lógico (P) pode ter apenas um thread de máquina (M) em execução a qualquer momento. E para que uma goroutine (G) seja executada, ela precisa estar anexada a um thread (M).
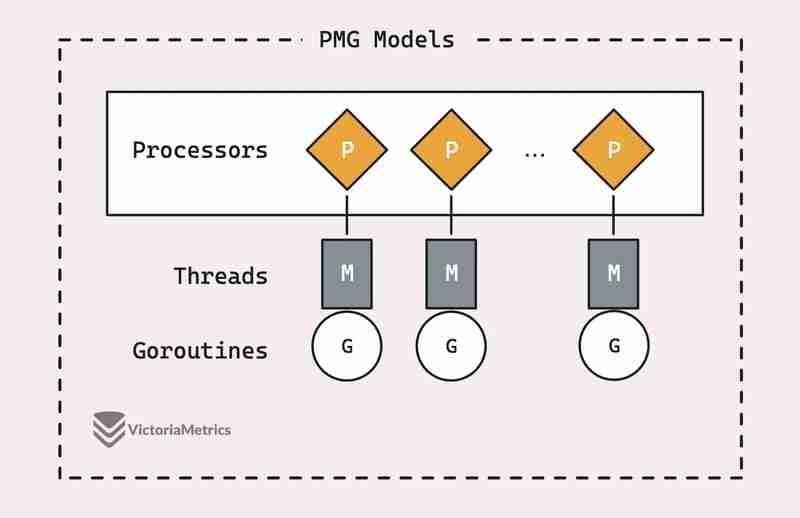
Isso se resume a dois pontos principais:
- Se você tiver n processadores lógicos (P), poderá executar até n goroutines em paralelo, desde que tenha pelo menos n threads de máquina (M) disponíveis.
- A qualquer momento, apenas uma goroutine (G) pode ser executada em um único processador (P). Portanto, quando um P1 está ocupado com um G, nenhum outro G pode ser executado naquele P1 até que o G atual seja bloqueado, termine ou algo mais aconteça para liberá-lo.
Mas a questão é que um sync.Pool em Go não é apenas um grande pool, na verdade é composto de vários pools 'locais', com cada um vinculado a um contexto de processador específico, ou P, que é o tempo de execução do Go. gerenciando a qualquer momento.
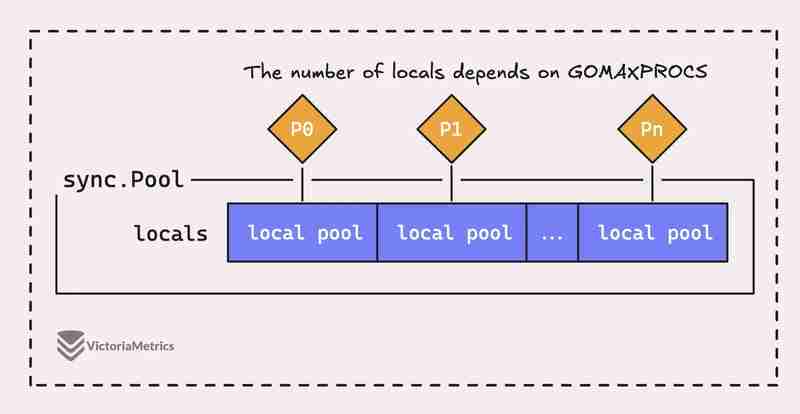
Quando uma goroutine em execução em um processador (P) precisa de um objeto do pool, ela primeiro verificará seu próprio pool P-local antes de procurar em qualquer outro lugar.
A postagem completa está disponível aqui: https://victoriametrics.com/blog/go-sync-pool/
-
 Como posso lidar com os nomes de arquivos UTF-8 nas funções do sistema de arquivos do PHP?lidando com utf-8 nomes de arquivos nas funções do sistema de arquivos do PHP Ao criar pastas que contêm caracteres utf-8 usando a função mkdi...Programação Postado em 2025-03-28
Como posso lidar com os nomes de arquivos UTF-8 nas funções do sistema de arquivos do PHP?lidando com utf-8 nomes de arquivos nas funções do sistema de arquivos do PHP Ao criar pastas que contêm caracteres utf-8 usando a função mkdi...Programação Postado em 2025-03-28 -
Como você pode usar o Grupo By to Pivot Data in MySQL?girando resultados de consulta usando o grupo mysql por em um banco de dados relacional, girando dados se referindo ao rearranjo de linhas e c...Programação Postado em 2025-03-28
-
Por que não está aparecendo na minha imagem de fundo do CSS?SOLHAÇÃO DE TRABALHO: CSS Imagem de fundo não apareceu Você encontrou um problema em que sua imagem em segundo plano falha, apesar das seguint...Programação Postado em 2025-03-28
-
Como posso combinar efetivamente o Flexbox e a rolagem vertical em um layout de altura total?integrando o flexbox e rolagem vertical em um layout de altura inteira ao trabalhar com aplicativos de altura completa, a combinação do Flexbo...Programação Postado em 2025-03-28
-
Como posso criar com eficiência dicionários usando a compreensão do Python?Python Dictionary Compreension Em Python, as compreensões do dicionário oferecem uma maneira concisa de gerar novos dicionários. Embora sejam se...Programação Postado em 2025-03-28
-
Como posso configurar o PyTesSeract para reconhecimento de um dígito com a saída apenas para número?pyTesseract OCR com reconhecimento de um dígito e restrições somente para números no contexto do pyTesSeract, a configuração do TESSERACT para...Programação Postado em 2025-03-28
-
Por que há listras no meu fundo linear de gradiente e como posso consertá -las?banindo as faixas de fundo do gradiente linear Ao empregar a propriedade linear de gradiente para um plano de fundo, você pode encontrar listr...Programação Postado em 2025-03-28
-
Como verificar se um objeto tem um atributo específico no Python?Método para determinar o atributo de objeto Existence Esta consulta busca um método para verificar a presença de um atributo específico em um ...Programação Postado em 2025-03-28
-
Como posso executar comandos de prompt de comando, incluindo alterações de diretório, em java?Executar comandos do prompt de comando em java Problema: executando comandos de prompt de java pode ser desafio. Embora você possa encontr...Programação Postado em 2025-03-28
-
Por que não é um pedido de solicitação de captura de entrada no PHP, apesar do código válido?abordando o mau funcionamento da solicitação de postagem em php no snippet de código apresentado: action='' Mantenha -se vigilante com a alo...Programação Postado em 2025-03-28
-
Como lidar com a entrada do usuário no modo exclusivo de tela cheia da Java?manuseando a entrada do usuário no modo exclusivo da tela full em java introdução ao executar um aplicativo Java no modo exclusivo de tela c...Programação Postado em 2025-03-28
-
Python Leia o arquivo CSV UnicodedecodeError Ultimate Solutionunicode decodificar erro no arquivo csv lendo Ao tentar ler um arquivo csodo (& sinod) usando o módulo CSV embutido, você pode encontrar um er...Programação Postado em 2025-03-28
-
Como resolver o erro \ "Uso inválido da função do grupo \" no MySQL ao encontrar a contagem máxima?como recuperar a contagem máxima usando o mysql em mysql, você pode encontrar um problema enquanto tenta encontrar a contagem máxima de valore...Programação Postado em 2025-03-28
-
Como fazer upload de arquivos com parâmetros adicionais usando java.net.urlConnection e codificação multipartida/formulário?carregando arquivos com http requests para fazer upload de arquivos para um servidor http e também enviando parâmetros adicionais, java.net.ur...Programação Postado em 2025-03-28
-
Como o `std :: launder` resolve problemas de otimização do compilador com os membros const em sindicatos?revelando a essência da lavagem de memória: um mergulho mais profundo no std :: launder no reino da padronização c, P0137 Introduces std :: la...Programação Postado em 2025-03-28















Estude chinês
- 1 Como se diz “andar” em chinês? 走路 Pronúncia chinesa, 走路 aprendizagem chinesa
- 2 Como se diz “pegar um avião” em chinês? 坐飞机 Pronúncia chinesa, 坐飞机 aprendizagem chinesa
- 3 Como se diz “pegar um trem” em chinês? 坐火车 Pronúncia chinesa, 坐火车 aprendizagem chinesa
- 4 Como se diz “pegar um ônibus” em chinês? 坐车 Pronúncia chinesa, 坐车 aprendizagem chinesa
- 5 Como se diz dirigir em chinês? 开车 Pronúncia chinesa, 开车 aprendizagem chinesa
- 6 Como se diz nadar em chinês? 游泳 Pronúncia chinesa, 游泳 aprendizagem chinesa
- 7 Como se diz andar de bicicleta em chinês? 骑自行车 Pronúncia chinesa, 骑自行车 aprendizagem chinesa
- 8 Como você diz olá em chinês? 你好Pronúncia chinesa, 你好Aprendizagem chinesa
- 9 Como você agradece em chinês? 谢谢Pronúncia chinesa, 谢谢Aprendizagem chinesa
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









