
ResNet x EfficientNet x VGG x NN
 Navegar:310
Navegar:310
Como estudante, testemunhei em primeira mão a frustração causada pelo sistema ineficiente de achados e perdidos da nossa universidade. O processo atual, que depende de e-mails individuais para cada item encontrado, muitas vezes leva a atrasos e perda de conexões entre os pertences perdidos e seus proprietários.
Movido pelo desejo de melhorar essa experiência para mim e para meus colegas estudantes, embarquei em um projeto para explorar o potencial do aprendizado profundo para revolucionar nosso sistema de achados e perdidos. Nesta postagem do blog, compartilharei minha jornada de avaliação de modelos pré-treinados - ResNet, EfficientNet, VGG e NasNet - para automatizar a identificação e categorização de itens perdidos.
Através de uma análise comparativa, pretendo identificar o modelo mais adequado para integração em nosso sistema, criando, em última análise, uma experiência de achados e perdidos mais rápida, precisa e fácil de usar para todos no campus.
ResNet
Inception-ResNet V2 é uma poderosa arquitetura de rede neural convolucional disponível em Keras, combinando os pontos fortes da arquitetura Inception com conexões residuais do ResNet. Este modelo híbrido visa alcançar alta precisão em tarefas de classificação de imagens, mantendo a eficiência computacional.
Conjunto de dados de treinamento: ImageNet
Formato de imagem: 299 x 299
Função de pré-processamento
def readyForResNet(fileName):
pic = load_img(fileName, target_size=(299, 299))
pic_array = img_to_array(pic)
expanded = np.expand_dims(pic_array, axis=0)
return preprocess_input_resnet(expanded)
Previsão
data1 = readyForResNet(test_file) prediction = inception_model_resnet.predict(data1) res1 = decode_predictions_resnet(prediction, top=2)
VGG (Grupo de Geometria Visual)
VGG (Visual Geometry Group) é uma família de arquiteturas de redes neurais convolucionais profundas conhecidas por sua simplicidade e eficácia em tarefas de classificação de imagens. Esses modelos, especialmente VGG16 e VGG19, ganharam popularidade devido ao seu forte desempenho no ImageNet Large Scale Visual Recognition Challenge (ILSVRC) em 2014.
Conjunto de dados de treinamento: ImageNet
Formato de imagem: 224 x 224
Função de pré-processamento
def readyForVGG(fileName):
pic = load_img(fileName, target_size=(224, 224))
pic_array = img_to_array(pic)
expanded = np.expand_dims(pic_array, axis=0)
return preprocess_input_vgg19(expanded)
Previsão
data2 = readyForVGG(test_file) prediction = inception_model_vgg19.predict(data2) res2 = decode_predictions_vgg19(prediction, top=2)
EficienteNet
EfficientNet é uma família de arquiteturas de redes neurais convolucionais que alcançam precisão de última geração em tarefas de classificação de imagens, ao mesmo tempo que são significativamente menores e mais rápidas do que os modelos anteriores. Essa eficiência é alcançada por meio de um novo método de escalonamento composto que equilibra profundidade, largura e resolução da rede.
Conjunto de dados de treinamento: ImageNet
Formato de imagem: 480 x 480
Função de pré-processamento
def readyForEF(fileName):
pic = load_img(fileName, target_size=(480, 480))
pic_array = img_to_array(pic)
expanded = np.expand_dims(pic_array, axis=0)
return preprocess_input_EF(expanded)
Previsão
data3 = readyForEF(test_file) prediction = inception_model_EF.predict(data3) res3 = decode_predictions_EF(prediction, top=2)
NasNet
NasNet (Rede de Pesquisa de Arquitetura Neural) representa uma abordagem inovadora em aprendizado profundo, onde a arquitetura da própria rede neural é descoberta por meio de um processo de pesquisa automatizado. Este processo de busca visa encontrar a combinação ideal de camadas e conexões para alcançar alto desempenho em uma determinada tarefa.
Conjunto de dados de treinamento: ImageNet
Formato de imagem: 224 x 224
Função de pré-processamento
def readyForNN(fileName):
pic = load_img(fileName, target_size=(224, 224))
pic_array = img_to_array(pic)
expanded = np.expand_dims(pic_array, axis=0)
return preprocess_input_NN(expanded)
Previsão
data4 = readyForNN(test_file) prediction = inception_model_NN.predict(data4) res4 = decode_predictions_NN(prediction, top=2)
Confronto
Precisão
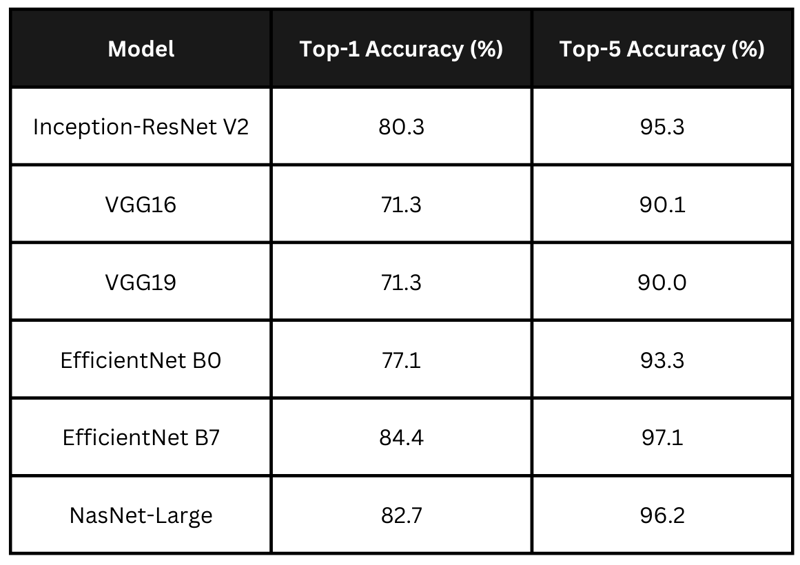
A tabela resume as pontuações de precisão reivindicadas dos modelos acima. EfficientNet B7 lidera com a maior precisão, seguido de perto por NasNet-Large e Inception-ResNet V2. Os modelos VGG apresentam precisões mais baixas. Para minha aplicação, quero escolher um modelo que tenha um equilíbrio entre tempo de processamento e precisão.
Tempo
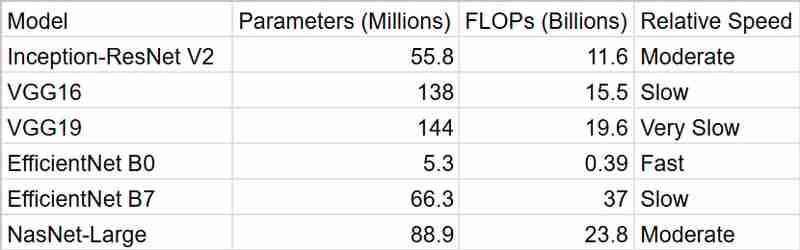
Como podemos ver, EfficientNetB0 nos fornece os resultados mais rápidos, mas InceptionResNetV2 é um pacote melhor quando levada em consideração a precisão
Resumo
Para meu sistema inteligente de achados e perdidos, decidi usar o InceptionResNetV2. Embora o EfficientNet B7 parecesse tentador com sua precisão de alto nível, fiquei preocupado com suas demandas computacionais. Num ambiente universitário, onde os recursos podem ser limitados e o desempenho em tempo real é muitas vezes desejável, senti que era importante encontrar um equilíbrio entre precisão e eficiência. InceptionResNetV2 parecia ser o ajuste perfeito - oferece forte desempenho sem ser excessivamente intensivo em termos computacionais.
Além disso, o fato de ser pré-treinado no ImageNet me dá confiança de que ele pode lidar com a grande variedade de objetos que as pessoas podem perder. E não esqueçamos como é fácil trabalhar no Keras! Isso definitivamente tornou minha decisão mais fácil.
No geral, acredito que InceptionResNetV2 fornece a combinação certa de precisão, eficiência e praticidade para meu projeto. Estou animado para ver como ele funciona ajudando a reunir itens perdidos com seus proprietários!
-
 Por que o Microsoft Visual C ++ falha ao implementar corretamente a instanciação do modelo bifásico?O mistério do modelo de duas fases "quebrado" bifásia instanciação no Microsoft Visual C Declaração de Problema: STRAGLES Expressa...Programação Postado em 2025-03-12
Por que o Microsoft Visual C ++ falha ao implementar corretamente a instanciação do modelo bifásico?O mistério do modelo de duas fases "quebrado" bifásia instanciação no Microsoft Visual C Declaração de Problema: STRAGLES Expressa...Programação Postado em 2025-03-12 -
UTF-8 vs. Latin-1: O segredo da codificação de caráter!distinguindo UTF-8 e Latin1 Ao lidar com a codificação, surgem duas opções proeminentes: utf-8 e latin1. Em meio a seus aplicativos, surge uma...Programação Postado em 2025-03-12
-
VariedadeOs métodos são FNs que podem ser chamados em objetos Matrizes são objetos, portanto, eles também têm métodos no JS. Flice (Begin): Extra...Programação Postado em 2025-03-12
-
Como posso substituir com eficiência várias substringas em uma string java?substituindo várias substâncias em uma string com eficiência em java quando confrontado com a necessidade de substituir várias substringas den...Programação Postado em 2025-03-12
-
Parte SQL Injeção Série: Explicação detalhada das técnicas avançadas de injeção de SQLAutor: Trix Cyrus Ferramenta Pentesting Waymap: Clique aqui TrixSec Github: clique aqui TrixSec Telegram: clique aqui Explorações ...Programação Postado em 2025-03-12
-
Como corrigir “Erro geral: o servidor MySQL 2006 desapareceu” ao inserir dados?Como resolver "Erro geral: o servidor MySQL de 2006 desapareceu" ao inserir registrosIntrodução:A inserção de dados em um banco de dados MyS...Programação Postado em 2025-03-12
-
Como podemos garantir uploads de arquivos contra conteúdo malicioso?preocupações de segurança com o arquivo uploads carregando arquivos para um servidor pode introduzir riscos de segurança significativos devido...Programação Postado em 2025-03-12
-
Como remover quebras de linha das cordas usando expressões regulares em JavaScript?removendo quebras de linha de strings Neste cenário de código, o objetivo é eliminar quebras de linha de uma string de texto lida de uma textare...Programação Postado em 2025-03-12
-
Por que a execução do JavaScript cessa ao usar o botão Back Firefox?Problema do histórico de navegação: JavaScript deixa de executar após o uso do botão de volta ao Firefox usuários do Firefox podem encontrar u...Programação Postado em 2025-03-12
-
Como inserir corretamente Blobs (imagens) no MySQL usando PHP?Insira Blobs nos bancos de dados MySQL com PHP Ao tentar armazenar uma imagem no banco de dados A MySQL, você pode encontrar um problema. Est...Programação Postado em 2025-03-12
-
Posso migrar minha criptografia de McRypt para OpenSSL e descriptografar dados criptografados por McRypt usando o OpenSSL?Atualizando minha biblioteca de criptografia de McRypt para OpenSSL posso atualizar minha biblioteca de criptografia de McHRPT para openssl? N...Programação Postado em 2025-03-12
-
Existe uma diferença de desempenho entre usar um loop for-Each e um iterador para travessia de coleção em Java?para cada loop vs. iterator: eficiência na coleção Traversal Introduction quando travessing uma coleção em java, the ARIDES quando trave...Programação Postado em 2025-03-12
-
Como verificar se um objeto tem um atributo específico no Python?Método para determinar o atributo de objeto Existence Esta consulta busca um método para verificar a presença de um atributo específico em um ...Programação Postado em 2025-03-12
-
Explicação detalhada do método de aquisição de elementos aleatórios de hashset/linkedhashset javaencontrando um elemento aleatório em um set na programação, pode ser útil selecionar um elemento aleatório de uma coleção, como um set. O Java f...Programação Postado em 2025-03-12
-
Quando o CSS atribui o fallback a pixels (PX) sem unidades?Fallback para atributos CSS sem unidades: um estudo de caso atributos CSS geralmente requerem unidades (por exemplo, px, em, %) para especific...Programação Postado em 2025-03-12















Estude chinês
- 1 Como se diz “andar” em chinês? 走路 Pronúncia chinesa, 走路 aprendizagem chinesa
- 2 Como se diz “pegar um avião” em chinês? 坐飞机 Pronúncia chinesa, 坐飞机 aprendizagem chinesa
- 3 Como se diz “pegar um trem” em chinês? 坐火车 Pronúncia chinesa, 坐火车 aprendizagem chinesa
- 4 Como se diz “pegar um ônibus” em chinês? 坐车 Pronúncia chinesa, 坐车 aprendizagem chinesa
- 5 Como se diz dirigir em chinês? 开车 Pronúncia chinesa, 开车 aprendizagem chinesa
- 6 Como se diz nadar em chinês? 游泳 Pronúncia chinesa, 游泳 aprendizagem chinesa
- 7 Como se diz andar de bicicleta em chinês? 骑自行车 Pronúncia chinesa, 骑自行车 aprendizagem chinesa
- 8 Como você diz olá em chinês? 你好Pronúncia chinesa, 你好Aprendizagem chinesa
- 9 Como você agradece em chinês? 谢谢Pronúncia chinesa, 谢谢Aprendizagem chinesa
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









