
Expiração antecipada probabilística em Go
 Navegar:500
Navegar:500
Sobre debandadas de cache
Muitas vezes acabo em situações em que preciso armazenar em cache isso ou aquilo. Freqüentemente, esses valores são armazenados em cache por um período de tempo. Você provavelmente está familiarizado com o padrão. Você tenta obter um valor do cache; se tiver sucesso, você o devolve ao chamador e encerra o dia. Se o valor não estiver lá, você o busca (provavelmente no banco de dados) ou calcula-o e coloca-o no cache. Na maioria dos casos, isso funciona muito bem. No entanto, se a chave que você está usando para a entrada do cache for acessada com frequência e a operação para calcular os dados demorar um pouco, você acabará em uma situação em que várias solicitações paralelas terão simultaneamente uma falha no cache. Todas essas solicitações carregarão independentemente a origem e armazenarão o valor no cache. Isso resulta em desperdício de recursos e pode até levar à negação de serviço.
Deixe-me ilustrar com um exemplo. Usarei redis para cache e um servidor Go http simples na parte superior. Aqui está o código completo:
package main
import (
"errors"
"log"
"net/http"
"time"
"github.com/redis/go-redis/v9"
)
type handler struct {
rdb *redis.Client
cacheTTL time.Duration
}
func (ch *handler) simple(w http.ResponseWriter, r *http.Request) {
cacheKey := "my_cache_key"
// we'll use 200 to signify a cache hit & 201 to signify a miss
responseCode := http.StatusOK
cachedData, err := ch.rdb.Get(r.Context(), cacheKey).Result()
if err != nil {
if !errors.Is(err, redis.Nil) {
log.Println("could not reach redis", err.Error())
http.Error(w, "could not reach redis", http.StatusInternalServerError)
return
}
// cache miss - fetch & store
res := longRunningOperation()
responseCode = http.StatusCreated
err = ch.rdb.Set(r.Context(), cacheKey, res, ch.cacheTTL).Err()
if err != nil {
log.Println("failed to set cache value", err.Error())
http.Error(w, "failed to set cache value", http.StatusInternalServerError)
return
}
cachedData = res
}
w.WriteHeader(responseCode)
_, _ = w.Write([]byte(cachedData))
}
func longRunningOperation() string {
time.Sleep(time.Millisecond * 500)
return "hello"
}
func main() {
ttl := time.Second * 3
rdb := redis.NewClient(&redis.Options{
Addr: "localhost:6379",
})
handler := &handler{
rdb: rdb,
cacheTTL: ttl,
}
http.HandleFunc("/simple", handler.simple)
if err := http.ListenAndServe(":8080", nil); err != nil {
log.Fatalf("Could not start server: %s\n", err.Error())
}
}
Vamos colocar um pouco de carga no endpoint /simple e ver o que acontece. Vou usar vegeta para isso.
Eu executo o ataque vegeta -duration=30s -rate=500 -targets=./targets_simple.txt > res_simple.bin. Vegeta acaba fazendo 500 solicitações a cada segundo durante 30 segundos. Eu os represento graficamente como um histograma de códigos de resultado HTTP com intervalos que abrangem 100 ms cada. O resultado é o gráfico a seguir.
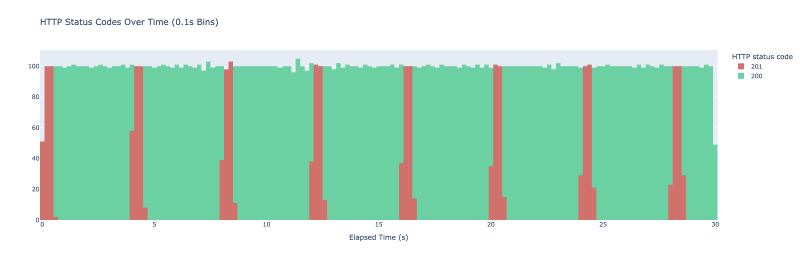
Quando iniciamos o experimento, o cache está vazio - não temos nenhum valor armazenado lá. Recebemos a debandada inicial quando um monte de solicitações chegam ao nosso servidor. Todos eles verificam o cache e não encontram nada lá, chamam longRunningOperation e armazenam no cache. Como longRunningOperation leva aproximadamente 500ms para concluir, qualquer solicitação feita nos primeiros 500ms acaba chamando longRunningOperation. Depois que uma das solicitações consegue armazenar o valor no cache, todas as solicitações seguintes o buscam no cache e começamos a ver respostas com o código de status 200. O padrão se repete a cada 3 segundos conforme o mecanismo de expiração no redis entra em ação.
Neste exemplo de brinquedo, isso não causa nenhum problema, mas em um ambiente de produção pode levar a uma carga desnecessária em seus sistemas, degradação da experiência do usuário ou até mesmo uma negação de serviço auto-induzida. Então, como podemos evitar isso? Bem, existem algumas maneiras. Poderíamos introduzir um bloqueio - qualquer falha no cache resultaria na tentativa de código de obter um bloqueio. O bloqueio distribuído não é algo trivial e muitas vezes apresenta casos extremos sutis que exigem um manuseio delicado. Também poderíamos recalcular periodicamente o valor usando um trabalho em segundo plano, mas isso requer a execução de um processo extra, introduzindo mais uma engrenagem que precisa ser mantida e monitorada em nosso código. Essa abordagem também pode não ser viável se você tiver chaves de cache dinâmicas. Existe outra abordagem, chamada expiração antecipada probabilística e isso é algo que gostaria de explorar mais detalhadamente.
Expiração antecipada probabilística
Esta técnica permite recalcular o valor com base em uma probabilidade. Ao buscar o valor do cache, você também calcula se precisa gerar novamente o valor do cache com base em uma probabilidade. Quanto mais próximo você estiver do vencimento do valor existente, maior será a probabilidade.
Estou baseando a implementação específica no XFetch de A. Vattani, F.Chierichetti & K. Lowenstein em Optimal Probabilistic Cache Stampede Prevention.
Apresentarei um novo endpoint no servidor HTTP que também realizará cálculos caros, mas desta vez usará XFetch ao armazenar em cache. Para que o XFetch funcione, precisamos armazenar quanto tempo demorou a operação cara (o delta) e quando a chave de cache expira. Para conseguir isso, apresentarei uma estrutura que conterá esses valores, bem como a própria mensagem:
type probabilisticValue struct {
Message string
Expiry time.Time
Delta time.Duration
}
Eu adiciono uma função para agrupar a mensagem original com esses atributos e serializá-la para armazenamento em redis:
func wrapMessage(message string, delta, cacheTTL time.Duration) (string, error) {
bts, err := json.Marshal(probabilisticValue{
Message: message,
Delta: delta,
Expiry: time.Now().Add(cacheTTL),
})
if err != nil {
return "", fmt.Errorf("could not marshal message: %w", err)
}
return string(bts), nil
}
Vamos também escrever um método para recalcular e armazenar o valor em redis:
func (ch *handler) recomputeValue(ctx context.Context, cacheKey string) (string, error) {
start := time.Now()
message := longRunningOperation()
delta := time.Since(start)
wrapped, err := wrapMessage(message, delta, ch.cacheTTL)
if err != nil {
return "", fmt.Errorf("could not wrap message: %w", err)
}
err = ch.rdb.Set(ctx, cacheKey, wrapped, ch.cacheTTL).Err()
if err != nil {
return "", fmt.Errorf("could not save value: %w", err)
}
return message, nil
}
Para determinar se precisamos atualizar o valor com base na probabilidade, podemos adicionar um método a probabilisticValue:
func (pv probabilisticValue) shouldUpdate() bool {
// suggested default param in XFetch implementation
// if increased - results in earlier expirations
beta := 1.0
now := time.Now()
scaledGap := pv.Delta.Seconds() * beta * math.Log(rand.Float64())
return now.Sub(pv.Expiry).Seconds() >= scaledGap
}
Se conectarmos tudo, teremos o seguinte manipulador:
func (ch *handler) probabilistic(w http.ResponseWriter, r *http.Request) {
cacheKey := "probabilistic_cache_key"
// we'll use 200 to signify a cache hit & 201 to signify a miss
responseCode := http.StatusOK
cachedData, err := ch.rdb.Get(r.Context(), cacheKey).Result()
if err != nil {
if !errors.Is(err, redis.Nil) {
log.Println("could not reach redis", err.Error())
http.Error(w, "could not reach redis", http.StatusInternalServerError)
return
}
res, err := ch.recomputeValue(r.Context(), cacheKey)
if err != nil {
log.Println("could not recompute value", err.Error())
http.Error(w, "could not recompute value", http.StatusInternalServerError)
return
}
responseCode = http.StatusCreated
cachedData = res
w.WriteHeader(responseCode)
_, _ = w.Write([]byte(cachedData))
return
}
pv := probabilisticValue{}
err = json.Unmarshal([]byte(cachedData), &pv)
if err != nil {
log.Println("could not unmarshal probabilistic value", err.Error())
http.Error(w, "could not unmarshal probabilistic value", http.StatusInternalServerError)
return
}
if pv.shouldUpdate() {
_, err := ch.recomputeValue(r.Context(), cacheKey)
if err != nil {
log.Println("could not recompute value", err.Error())
http.Error(w, "could not recompute value", http.StatusInternalServerError)
return
}
responseCode = http.StatusAccepted
}
w.WriteHeader(responseCode)
_, _ = w.Write([]byte(cachedData))
}
O manipulador funciona de maneira muito parecida com o primeiro, porém, ao obter um cache hit, jogamos os dados. Dependendo do resultado, apenas retornamos o valor que acabamos de buscar ou atualizamos o valor antecipadamente.
Usaremos os códigos de status HTTP para determinar entre os 3 casos:
- 200 - retornamos o valor do cache
- 201 - falta de cache, nenhum valor presente
- 202 - ocorrência de cache, atualização probabilística acionada
Eu inicio o vegeta mais uma vez, desta vez rodando no novo endpoint e aqui está o resultado:
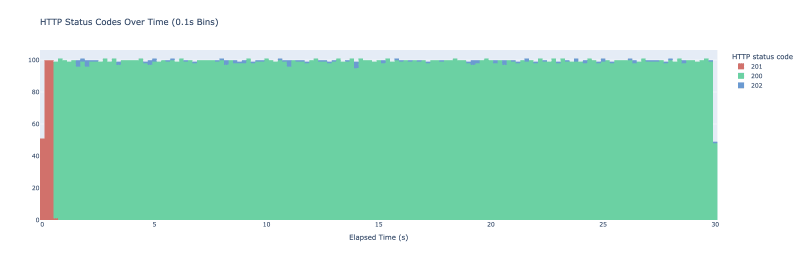
As pequenas manchas azuis indicam quando acabamos atualizando o valor do cache mais cedo. Não vemos mais perdas de cache após o período de aquecimento inicial. Para evitar o pico inicial, você pode pré-armazenar o valor em cache se isso for importante para o seu caso de uso.
Se quiser ser mais agressivo com seu cache e atualizar o valor com mais frequência, você pode brincar com o parâmetro beta. Esta é a aparência do mesmo experimento com o parâmetro beta definido como 2:
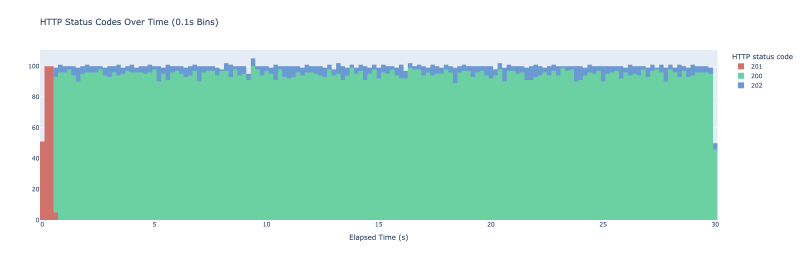
Agora estamos vendo atualizações probabilísticas com muito mais frequência.
Em suma, esta é uma pequena técnica interessante que pode ajudar a evitar debandadas de cache. Porém, lembre-se de que isso só funciona se você buscar periodicamente a mesma chave do cache - caso contrário, você não verá muitos benefícios.
Tem outra maneira de lidar com a debandada de cache? Notou um erro? Deixe-me saber nos comentários abaixo!
-
 Por que o Microsoft Visual C ++ falha ao implementar corretamente a instanciação do modelo bifásico?O mistério do modelo de duas fases "quebrado" bifásia instanciação no Microsoft Visual C Declaração de Problema: STRAGLES Expressa...Programação Postado em 2025-03-12
Por que o Microsoft Visual C ++ falha ao implementar corretamente a instanciação do modelo bifásico?O mistério do modelo de duas fases "quebrado" bifásia instanciação no Microsoft Visual C Declaração de Problema: STRAGLES Expressa...Programação Postado em 2025-03-12 -
UTF-8 vs. Latin-1: O segredo da codificação de caráter!distinguindo UTF-8 e Latin1 Ao lidar com a codificação, surgem duas opções proeminentes: utf-8 e latin1. Em meio a seus aplicativos, surge uma...Programação Postado em 2025-03-12
-
VariedadeOs métodos são FNs que podem ser chamados em objetos Matrizes são objetos, portanto, eles também têm métodos no JS. Flice (Begin): Extra...Programação Postado em 2025-03-12
-
Como posso substituir com eficiência várias substringas em uma string java?substituindo várias substâncias em uma string com eficiência em java quando confrontado com a necessidade de substituir várias substringas den...Programação Postado em 2025-03-12
-
Parte SQL Injeção Série: Explicação detalhada das técnicas avançadas de injeção de SQLAutor: Trix Cyrus Ferramenta Pentesting Waymap: Clique aqui TrixSec Github: clique aqui TrixSec Telegram: clique aqui Explorações ...Programação Postado em 2025-03-12
-
Como corrigir “Erro geral: o servidor MySQL 2006 desapareceu” ao inserir dados?Como resolver "Erro geral: o servidor MySQL de 2006 desapareceu" ao inserir registrosIntrodução:A inserção de dados em um banco de dados MyS...Programação Postado em 2025-03-12
-
Como podemos garantir uploads de arquivos contra conteúdo malicioso?preocupações de segurança com o arquivo uploads carregando arquivos para um servidor pode introduzir riscos de segurança significativos devido...Programação Postado em 2025-03-12
-
Como remover quebras de linha das cordas usando expressões regulares em JavaScript?removendo quebras de linha de strings Neste cenário de código, o objetivo é eliminar quebras de linha de uma string de texto lida de uma textare...Programação Postado em 2025-03-12
-
Por que a execução do JavaScript cessa ao usar o botão Back Firefox?Problema do histórico de navegação: JavaScript deixa de executar após o uso do botão de volta ao Firefox usuários do Firefox podem encontrar u...Programação Postado em 2025-03-12
-
Como inserir corretamente Blobs (imagens) no MySQL usando PHP?Insira Blobs nos bancos de dados MySQL com PHP Ao tentar armazenar uma imagem no banco de dados A MySQL, você pode encontrar um problema. Est...Programação Postado em 2025-03-12
-
Posso migrar minha criptografia de McRypt para OpenSSL e descriptografar dados criptografados por McRypt usando o OpenSSL?Atualizando minha biblioteca de criptografia de McRypt para OpenSSL posso atualizar minha biblioteca de criptografia de McHRPT para openssl? N...Programação Postado em 2025-03-12
-
Existe uma diferença de desempenho entre usar um loop for-Each e um iterador para travessia de coleção em Java?para cada loop vs. iterator: eficiência na coleção Traversal Introduction quando travessing uma coleção em java, the ARIDES quando trave...Programação Postado em 2025-03-12
-
Como verificar se um objeto tem um atributo específico no Python?Método para determinar o atributo de objeto Existence Esta consulta busca um método para verificar a presença de um atributo específico em um ...Programação Postado em 2025-03-12
-
Explicação detalhada do método de aquisição de elementos aleatórios de hashset/linkedhashset javaencontrando um elemento aleatório em um set na programação, pode ser útil selecionar um elemento aleatório de uma coleção, como um set. O Java f...Programação Postado em 2025-03-12
-
Quando o CSS atribui o fallback a pixels (PX) sem unidades?Fallback para atributos CSS sem unidades: um estudo de caso atributos CSS geralmente requerem unidades (por exemplo, px, em, %) para especific...Programação Postado em 2025-03-12















Estude chinês
- 1 Como se diz “andar” em chinês? 走路 Pronúncia chinesa, 走路 aprendizagem chinesa
- 2 Como se diz “pegar um avião” em chinês? 坐飞机 Pronúncia chinesa, 坐飞机 aprendizagem chinesa
- 3 Como se diz “pegar um trem” em chinês? 坐火车 Pronúncia chinesa, 坐火车 aprendizagem chinesa
- 4 Como se diz “pegar um ônibus” em chinês? 坐车 Pronúncia chinesa, 坐车 aprendizagem chinesa
- 5 Como se diz dirigir em chinês? 开车 Pronúncia chinesa, 开车 aprendizagem chinesa
- 6 Como se diz nadar em chinês? 游泳 Pronúncia chinesa, 游泳 aprendizagem chinesa
- 7 Como se diz andar de bicicleta em chinês? 骑自行车 Pronúncia chinesa, 骑自行车 aprendizagem chinesa
- 8 Como você diz olá em chinês? 你好Pronúncia chinesa, 你好Aprendizagem chinesa
- 9 Como você agradece em chinês? 谢谢Pronúncia chinesa, 谢谢Aprendizagem chinesa
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









