 Primeira página > Programação > Otimizando web scraping: raspagem de dados de autenticação usando JSDOM
Primeira página > Programação > Otimizando web scraping: raspagem de dados de autenticação usando JSDOM
Otimizando web scraping: raspagem de dados de autenticação usando JSDOM
 Navegar:885
Navegar:885
Como desenvolvedores de scraping, às vezes precisamos extrair dados de autenticação, como chaves temporárias, para realizar nossas tarefas. No entanto, não é tão simples assim. Normalmente, é em solicitações de rede HTML ou XHR, mas às vezes os dados de autenticação são computados. Nesse caso, podemos fazer engenharia reversa da computação, o que leva muito tempo para desofuscar scripts, ou executar o JavaScript que a calcula. Normalmente usamos um navegador, mas é caro. Crawlee fornece suporte para executar o raspador de navegador e o Cheerio Scraper em paralelo, mas isso é muito complexo e caro em termos de uso de recursos de computação. JSDOM nos ajuda a executar o JavaScript da página com menos recursos que um navegador e um pouco mais alto que o Cheerio.
Este artigo discutirá uma nova abordagem que usamos em um de nossos atores para obter os dados de autenticação do centro criativo de anúncios TikTok gerados por aplicativos da web do navegador sem realmente executar o navegador, mas em vez disso, usando JSDOM.
Analisando o site
Quando você visita este URL:
https://ads.tiktok.com/business/creativecenter/inspiration/popular/hashtag/pc/en
Você verá uma lista de hashtags com sua classificação ao vivo, o número de postagens que possuem, gráfico de tendências, criadores e análises. Você também pode notar que podemos filtrar o setor, definir o período de tempo e usar uma caixa de seleção para filtrar se a tendência é nova no top 100 ou não.
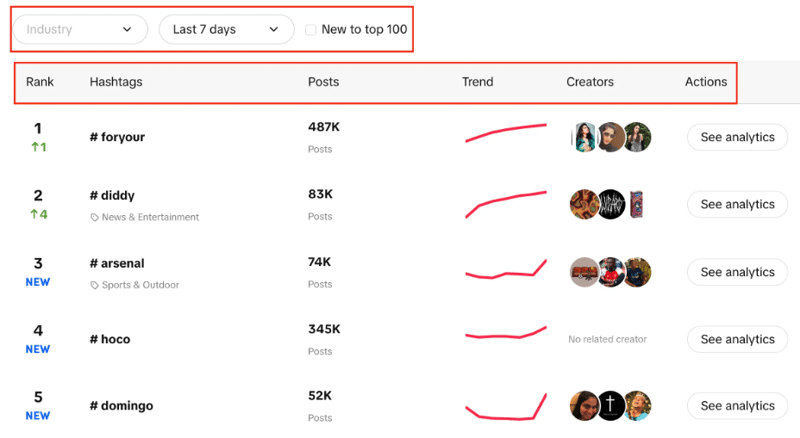
Nosso objetivo aqui é extrair as 100 principais hashtags da lista com os filtros fornecidos.
As duas abordagens possíveis são usar o CheerioCrawler, e a segunda será a raspagem baseada em navegador. Cheerio fornece resultados mais rápidos, mas não funciona com sites renderizados em JavaScript.
Cheerio não é a melhor opção aqui, pois o Creative Center é um aplicativo da web e a fonte de dados é API, portanto, só podemos obter as hashtags inicialmente presentes na estrutura HTML, mas não cada uma das 100 conforme necessário.
A segunda abordagem pode ser usar bibliotecas como Puppeteer, Playwright, etc, para fazer scraping baseado em navegador e usar automação para raspar todas as hashtags, mas com experiências anteriores, leva muito tempo para uma tarefa tão pequena.
Agora vem a nova abordagem que desenvolvemos para tornar esse processo muito melhor do que o rastreamento baseado em navegador e muito próximo do rastreamento baseado em CheerioCrawler.
Abordagem JSDOM
Antes de me aprofundar nessa abordagem, gostaria de dar crédito a Alexey Udovydchenko, engenheiro de automação da Web da Apify, por desenvolver essa abordagem. Parabéns a ele!
Nesta abordagem, faremos chamadas de API para https://ads.tiktok.com/creative_radar_api/v1/popular_trend/hashtag/list para obter os dados necessários.
Antes de fazer chamadas para esta API, precisaremos de alguns cabeçalhos necessários (dados de autenticação), então primeiro faremos a chamada para https://ads.tiktok.com/business/creativecenter/inspiration/popular/hashtag/pad /pt.
Começaremos esta abordagem criando uma função que criará a URL para a chamada da API para nós e fará a chamada e obterá os dados.
export const createStartUrls = (input) => {
const {
days = '7',
country = '',
resultsLimit = 100,
industry = '',
isNewToTop100,
} = input;
const filterBy = isNewToTop100 ? 'new_on_board' : '';
return [
{
url: `https://ads.tiktok.com/creative_radar_api/v1/popular_trend/hashtag/list?page=1&limit=50&period=${days}&country_code=${country}&filter_by=${filterBy}&sort_by=popular&industry_id=${industry}`,
headers: {
// required headers
},
userData: { resultsLimit },
},
];
};
Na função acima, criamos o URL inicial para a chamada da API que inclui vários parâmetros conforme falamos anteriormente. Após criar a URL de acordo com os parâmetros ele irá chamar o creative_radar_api e buscar todos os resultados.
Mas não funcionará até obtermos os cabeçalhos. Então, vamos criar uma função que primeiro criará uma sessão usando sessionPool e proxyConfiguration.
export const createSessionFunction = async (
sessionPool,
proxyConfiguration,
) => {
const proxyUrl = await proxyConfiguration.newUrl(Math.random().toString());
const url =
'https://ads.tiktok.com/business/creativecenter/inspiration/popular/hashtag/pad/en';
// need url with data to generate token
const response = await gotScraping({ url, proxyUrl });
const headers = await getApiUrlWithVerificationToken(
response.body.toString(),
url,
);
if (!headers) {
throw new Error(`Token generation blocked`);
}
log.info(`Generated API verification headers`, Object.values(headers));
return new Session({
userData: {
headers,
},
sessionPool,
});
};
Nesta função, o objetivo principal é ligar para https://ads.tiktok.com/business/creativecenter/inspiration/popular/hashtag/pad/en e obter cabeçalhos em troca. Para obter os cabeçalhos, estamos usando a função getApiUrlWithVerificationToken.
Antes de prosseguir, quero mencionar que Crawlee oferece suporte nativo a JSDOM usando o JSDOM Crawler. Ele fornece uma estrutura para rastreamento paralelo de páginas da web usando solicitações HTTP simples e implementação jsdom DOM. Ele usa solicitações HTTP brutas para baixar páginas da web, é muito rápido e eficiente na largura de banda de dados.
Vamos ver como vamos criar a função getApiUrlWithVerificationToken:
const getApiUrlWithVerificationToken = async (body, url) => {
log.info(`Getting API session`);
const virtualConsole = new VirtualConsole();
const { window } = new JSDOM(body, {
url,
contentType: 'text/html',
runScripts: 'dangerously',
resources: 'usable' || new CustomResourceLoader(),
// ^ 'usable' faster than custom and works without canvas
pretendToBeVisual: false,
virtualConsole,
});
virtualConsole.on('error', () => {
// ignore errors cause by fake XMLHttpRequest
});
const apiHeaderKeys = ['anonymous-user-id', 'timestamp', 'user-sign'];
const apiValues = {};
let retries = 10;
// api calls made outside of fetch, hack below is to get URL without actual call
window.XMLHttpRequest.prototype.setRequestHeader = (name, value) => {
if (apiHeaderKeys.includes(name)) {
apiValues[name] = value;
}
if (Object.values(apiValues).length === apiHeaderKeys.length) {
retries = 0;
}
};
window.XMLHttpRequest.prototype.open = (method, urlToOpen) => {
if (
['static', 'scontent'].find((x) =>
urlToOpen.startsWith(`https://${x}`),
)
)
log.debug('urlToOpen', urlToOpen);
};
do {
await sleep(4000);
retries--;
} while (retries > 0);
await window.close();
return apiValues;
};
Nesta função, estamos criando um console virtual que usa CustomResourceLoader para executar o processo em segundo plano e substituir o navegador por JSDOM.
Para este exemplo específico, precisamos de três cabeçalhos obrigatórios para fazer a chamada de API, e esses são ID de usuário anônimo, carimbo de data/hora e sinal de usuário.
Usando XMLHttpRequest.prototype.setRequestHeader, estamos verificando se os cabeçalhos mencionados estão na resposta ou não, se sim, pegamos o valor desses cabeçalhos e repetimos as tentativas até obter todos os cabeçalhos.
Então, a parte mais importante é que usamos XMLHttpRequest.prototype.open para extrair os dados de autenticação e fazer chamadas sem realmente usar navegadores ou expor a atividade do bot.
No final de createSessionFunction, ele retorna uma sessão com os cabeçalhos necessários.
Agora, chegando ao nosso código principal, usaremos CheerioCrawler e prenavigationHooks para injetar os cabeçalhos que obtivemos da função anterior no requestHandler.
const crawler = new CheerioCrawler({
sessionPoolOptions: {
maxPoolSize: 1,
createSessionFunction: async (sessionPool) =>
createSessionFunction(sessionPool, proxyConfiguration),
},
preNavigationHooks: [
(crawlingContext) => {
const { request, session } = crawlingContext;
request.headers = {
...request.headers,
...session.userData?.headers,
};
},
],
proxyConfiguration,
});
Finalmente, no manipulador de solicitações, fazemos a chamada usando os cabeçalhos e verificamos quantas chamadas são necessárias para buscar toda a paginação de manipulação de dados.
async requestHandler(context) {
const { log, request, json } = context;
const { userData } = request;
const { itemsCounter = 0, resultsLimit = 0 } = userData;
if (!json.data) {
throw new Error('BLOCKED');
}
const { data } = json;
const items = data.list;
const counter = itemsCounter items.length;
const dataItems = items.slice(
0,
resultsLimit && counter > resultsLimit
? resultsLimit - itemsCounter
: undefined,
);
await context.pushData(dataItems);
const {
pagination: { page, total },
} = data;
log.info(
`Scraped ${dataItems.length} results out of ${total} from search page ${page}`,
);
const isResultsLimitNotReached =
counter
Uma coisa importante a ser observada aqui é que estamos criando esse código de forma que possamos fazer qualquer número de chamadas de API.
Neste exemplo específico, fizemos apenas uma solicitação e uma única sessão, mas você pode fazer mais se precisar. Quando a primeira chamada de API for concluída, a segunda chamada de API será criada. Novamente, você pode fazer mais ligações se necessário, mas paramos nas duas.
Para deixar as coisas mais claras, esta é a aparência do fluxo de código:
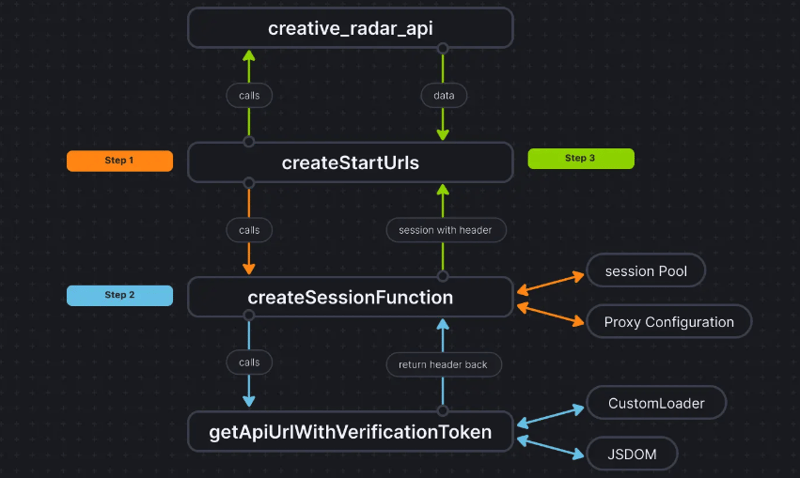
Conclusão
Essa abordagem nos ajuda a obter uma terceira maneira de extrair os dados de autenticação sem realmente usar um navegador e passar os dados para o CheerioCrawler. Isso melhora significativamente o desempenho e reduz o requisito de RAM em 50%, e embora o desempenho de raspagem baseado em navegador seja dez vezes mais lento que o Cheerio puro, o JSDOM faz isso apenas 3 a 4 vezes mais lento, o que o torna 2 a 3 vezes mais rápido que o navegador. raspagem baseada.
A base de código do projeto já foi carregada aqui. O código é escrito como um Apify Actor; você pode encontrar mais sobre isso aqui, mas também pode executá-lo sem usar o Apify SDK.
Se você tiver alguma dúvida ou pergunta sobre esta abordagem, entre em contato conosco em nosso servidor Discord.
-
 `Console.log` mostra o motivo da exceção do valor do objeto modificadoObjetos e console.log: uma estranheza desvendada Ao trabalhar com objetos e console.log, você pode encontrar comportamento peculiar. Vamos des...Programação Postado em 2025-07-13
`Console.log` mostra o motivo da exceção do valor do objeto modificadoObjetos e console.log: uma estranheza desvendada Ao trabalhar com objetos e console.log, você pode encontrar comportamento peculiar. Vamos des...Programação Postado em 2025-07-13 -
Como converter com eficiência fusos horários em PHP?Conversão eficiente do fuso horário em php No PHP, o manuseio dos fusos horários pode ser uma tarefa direta. Este guia fornecerá um método fácil...Programação Postado em 2025-07-13
-
Como evitar envios duplicados após a atualização do formulário?impedindo envios duplicados com atualização de manipulação no desenvolvimento da web, é comum encontrar a questão das submissões duplicadas qu...Programação Postado em 2025-07-13
-
\ "while (1) vs. para (;;): a otimização do compilador elimina as diferenças de desempenho? \"while (1) vs. for (;;): existe uma diferença de velocidade? loops? Resposta: Na maioria dos compiladores modernos, não há diferença de dese...Programação Postado em 2025-07-13
-
Como lidar com a memória fatiada na coleção de lixo de idiomas Go?coleta de lixo em go slies: uma análise detalhada em go, uma fatia é uma matriz dinâmica que faz referência a uma matriz subjacente. Ao trabal...Programação Postado em 2025-07-13
-
Preciso excluir explicitamente as alocações de heap em C ++ antes da saída do programa?exclusão explícita em c, apesar do programa exit ao trabalhar com a alocação de memória dinâmica em C, os desenvolvedores geralmente se pergun...Programação Postado em 2025-07-13
-
Os parâmetros de modelo podem na função C ++ 20 ConstEval depender dos parâmetros da função?funções constEval e parâmetros de modelos dependentes de argumentos de função em C 17, um parâmetro de modelo não pode depender de um argument...Programação Postado em 2025-07-13
-
Por que não `corpo {margem: 0; } `Sempre remova a margem superior no CSS?abordando a remoção da margem corporal em css para desenvolvedores da web iniciantes, remover a margem do elemento corporal pode ser uma taref...Programação Postado em 2025-07-13
-
Como inserir com eficiência dados em várias tabelas MySQL em uma transação?mysql Inserir em múltiplas tabelas tentando inserir dados em várias tabelas com uma única consulta MySQL pode produzir resultados inesperados....Programação Postado em 2025-07-13
-
Qual é a diferença entre funções aninhadas e fechamentos em Pythonfunções aninhadas vs. fechamentos em python enquanto as funções aninhadas em python se assemelham superficialmente, e são fundamentalmente dis...Programação Postado em 2025-07-13
-
Quando um aplicativo Go Go fecha a conexão do banco de dados?Gerenciando conexões de banco de dados em Applications Go Web em aplicativos simples Go Web que utilizam bancos de dados como PostGresql, o mome...Programação Postado em 2025-07-13
-
Como remover emojis das cordas em Python: um guia para iniciantes para corrigir erros comuns?removendo os emojis de strings em python o código Python fornecido para remover emojis falha porque contém syntaxe erros. As cadeias de unicod...Programação Postado em 2025-07-13
-
Como usar corretamente as consultas com parâmetros de PDO?usando consultas semelhantes em PDO Ao tentar implementar como consultas em PDO, você pode encontrar questões como as descritas na consulta ab...Programação Postado em 2025-07-13
-
Como analisar números na notação exponencial usando decimal.parse ()?analisando um número da notação exponencial ao tentar analisar uma string expressa em anotação exponencial usando Decimal.parse ("1.2345e...Programação Postado em 2025-07-13
-
Por que não é um pedido de solicitação de captura de entrada no PHP, apesar do código válido?abordando o mau funcionamento da solicitação de postagem em php no snippet de código apresentado: action='' Mantenha -se vigilante com a alo...Programação Postado em 2025-07-13















Estude chinês
- 1 Como se diz “andar” em chinês? 走路 Pronúncia chinesa, 走路 aprendizagem chinesa
- 2 Como se diz “pegar um avião” em chinês? 坐飞机 Pronúncia chinesa, 坐飞机 aprendizagem chinesa
- 3 Como se diz “pegar um trem” em chinês? 坐火车 Pronúncia chinesa, 坐火车 aprendizagem chinesa
- 4 Como se diz “pegar um ônibus” em chinês? 坐车 Pronúncia chinesa, 坐车 aprendizagem chinesa
- 5 Como se diz dirigir em chinês? 开车 Pronúncia chinesa, 开车 aprendizagem chinesa
- 6 Como se diz nadar em chinês? 游泳 Pronúncia chinesa, 游泳 aprendizagem chinesa
- 7 Como se diz andar de bicicleta em chinês? 骑自行车 Pronúncia chinesa, 骑自行车 aprendizagem chinesa
- 8 Como você diz olá em chinês? 你好Pronúncia chinesa, 你好Aprendizagem chinesa
- 9 Como você agradece em chinês? 谢谢Pronúncia chinesa, 谢谢Aprendizagem chinesa
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









