
import streamlit as stimport numpy as npimport pandas as pdimport joblib
stremlit é uma biblioteca Python que facilita a criação e o compartilhamento de aplicativos da web personalizados para projetos de aprendizado de máquina e ciência de dados.
numpy é uma biblioteca Python fundamental para computação numérica. Ele fornece suporte para matrizes e matrizes grandes e multidimensionais, juntamente com uma coleção de funções matemáticas para operar nessas matrizes de forma eficiente.
data = { \\\"island\\\": island, \\\"bill_length_mm\\\": bill_length_mm, \\\"bill_depth_mm\\\": bill_depth_mm, \\\"flipper_length_mm\\\": flipper_length_mm, \\\"body_mass_g\\\": body_mass_g, \\\"sex\\\": sex,}input_df = pd.DataFrame(data, index=[0])encode = [\\\"island\\\", \\\"sex\\\"]input_encoded_df = pd.get_dummies(input_df, prefix=encode)Os valores de entrada são recuperados do formulário de entrada criado pelo Stremlit e as variáveis categóricas são codificadas usando as mesmas regras de quando o modelo foi criado. Observe que a ordem de cada dado também deve ser a mesma de quando o modelo foi criado. Se a ordem for diferente, ocorrerá um erro ao executar uma previsão usando o modelo.
clf = joblib.load(\\\"penguin_classifier_model.pkl\\\")
\\\"penguin_classifier_model.pkl\\\" é o arquivo onde o modelo salvo anteriormente está armazenado. Este arquivo contém um RandomForestClassifier treinado em formato binário. A execução desse código carrega o modelo no clf, permitindo usá-lo para previsões e avaliações de novos dados.
prediction = clf.predict(input_encoded_df)prediction_proba = clf.predict_proba(input_encoded_df)
clf.predict(input_encoded_df): Usa o modelo treinado para prever a classe para os novos dados de entrada codificados, armazenando o resultado na previsão.
clf.predict_proba(input_encoded_df): Calcula a probabilidade de cada classe, armazenando os resultados em Prediction_proba.
Você pode publicar seu aplicativo desenvolvido na Internet acessando o Stremlit Community Cloud (https://streamlit.io/cloud) e especificando a URL do repositório GitHub.

Arte de @allison_horst (https://github.com/allisonhorst)
O modelo é treinado usando o conjunto de dados Palmer Penguins, um conjunto de dados amplamente reconhecido para a prática de técnicas de aprendizado de máquina. Este conjunto de dados fornece informações sobre três espécies de pinguins (Adelie, Chinstrap e Gentoo) do Arquipélago Palmer, na Antártica. Os principais recursos incluem:
Este conjunto de dados é proveniente do Kaggle e pode ser acessado aqui. A diversidade de características o torna uma excelente escolha para construir um modelo de classificação e compreender a importância de cada característica na previsão de espécies.
","image":"http://www.luping.net/uploads/20241006/17282217676702924713227.png","datePublished":"2024-11-02T21:56:21+08:00","dateModified":"2024-11-02T21:56:21+08:00","author":{"@type":"Person","name":"luping.net","url":"https://www.luping.net/articlelist/0_1.html"}} Primeira página > Programação > Implantação de modelo de aprendizado de máquina como um aplicativo da Web usando Streamlit
Primeira página > Programação > Implantação de modelo de aprendizado de máquina como um aplicativo da Web usando Streamlit
 Navegar:899
Navegar:899
Um modelo de aprendizado de máquina é essencialmente um conjunto de regras ou mecanismos usados para fazer previsões ou encontrar padrões em dados. Para simplificar (e sem medo de simplificar demais), uma linha de tendência calculada usando o método dos mínimos quadrados no Excel também é um modelo. No entanto, os modelos utilizados em aplicações reais não são tão simples – muitas vezes envolvem equações e algoritmos mais complexos, e não apenas equações simples.
Nesta postagem, começarei construindo um modelo de aprendizado de máquina muito simples e lançando-o como um aplicativo da web muito simples para ter uma ideia do processo.
Aqui, vou me concentrar apenas no processo, não no modelo de ML em si. Além disso, usarei Streamlit e Streamlit Community Cloud para lançar facilmente aplicativos da web em Python.
Usando o scikit-learn, uma biblioteca Python popular para aprendizado de máquina, você pode treinar dados rapidamente e criar um modelo com apenas algumas linhas de código para tarefas simples. O modelo pode então ser salvo como um arquivo reutilizável com joblib. Este modelo salvo pode ser importado/carregado como uma biblioteca Python normal em um aplicativo da web, permitindo que o aplicativo faça previsões usando o modelo treinado!
URL do aplicativo: https://yh-machine-learning.streamlit.app/
GitHub: https://github.com/yoshan0921/yh-machine-learning.git
Este aplicativo permite que você examine as previsões feitas por um modelo de floresta aleatório treinado no conjunto de dados Palmer Penguins. (Veja o final deste artigo para obter mais detalhes sobre os dados de treinamento.)
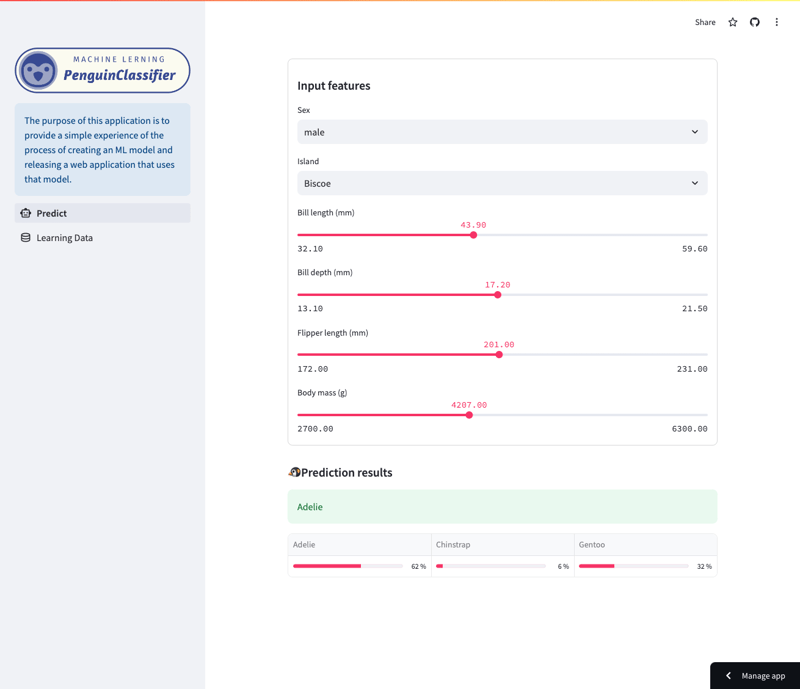
Especificamente, o modelo prevê espécies de pinguins com base em uma variedade de características, incluindo espécie, ilha, comprimento do bico, comprimento das nadadeiras, tamanho do corpo e sexo. Os usuários podem navegar no aplicativo para ver como diferentes recursos afetam as previsões do modelo.
Tela de previsão
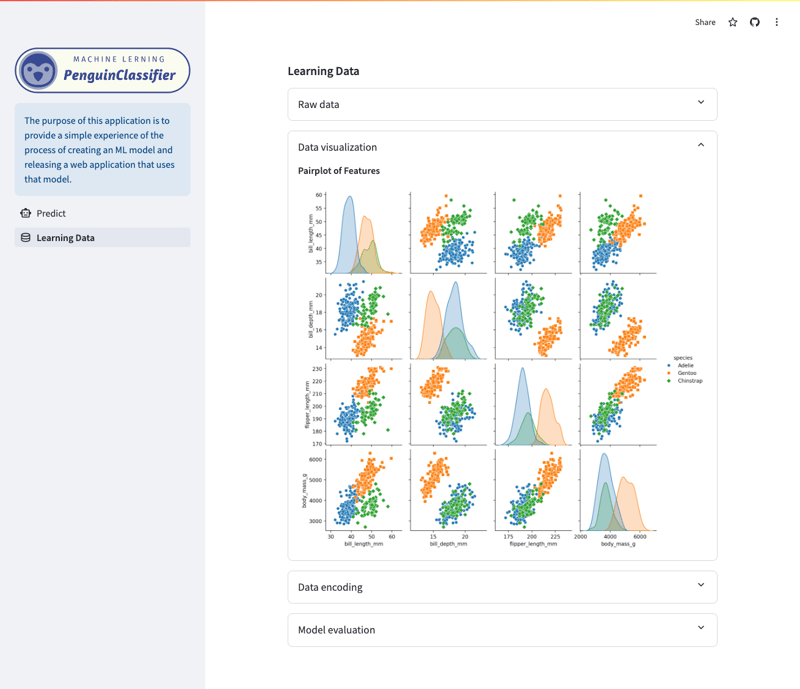
Tela de dados/visualização de aprendizagem
import pandas as pd from sklearn.model_selection import train_test_split from sklearn.ensemble import RandomForestClassifier from sklearn.metrics import accuracy_score import joblib
pandas é uma biblioteca Python especializada em manipulação e análise de dados. Ele suporta carregamento, pré-processamento e estruturação de dados usando DataFrames, preparando dados para modelos de aprendizado de máquina.
sklearn é uma biblioteca Python abrangente para aprendizado de máquina que fornece ferramentas para treinamento e avaliação. Neste post, irei construir um modelo usando um método de aprendizagem chamado Random Forest.
joblib é uma biblioteca Python que ajuda a salvar e carregar objetos Python, como modelos de aprendizado de máquina, de uma forma muito eficiente.
df = pd.read_csv("./dataset/penguins_cleaned.csv")
X_raw = df.drop("species", axis=1)
y_raw = df.species
Carregue o conjunto de dados (dados de treinamento) e separe-o em recursos (X) e variáveis de destino (y).
encode = ["island", "sex"]
X_encoded = pd.get_dummies(X_raw, columns=encode)
target_mapper = {"Adelie": 0, "Chinstrap": 1, "Gentoo": 2}
y_encoded = y_raw.apply(lambda x: target_mapper[x])
As variáveis categóricas são convertidas em um formato numérico usando codificação one-hot (X_encoded). Por exemplo, se “ilha” contiver as categorias “Biscoe”, “Dream” e “Torgersen”, uma nova coluna será criada para cada uma (island_Biscoe, island_Dream, island_Torgersen). O mesmo é feito para o sexo. Se os dados originais forem “Biscoe”, a coluna ilha_Biscoe será definida como 1 e as demais como 0.
A variável alvo espécie é mapeada para valores numéricos (y_encoded).
x_train, x_test, y_train, y_test = train_test_split(
X_encoded, y_encoded, test_size=0.3, random_state=1
)
Para avaliar um modelo, é necessário medir o desempenho do modelo em dados não utilizados para treinamento. 7:3 é amplamente utilizado como prática geral em aprendizado de máquina.
clf = RandomForestClassifier() clf.fit(x_train, y_train)
O método de ajuste é usado para treinar o modelo.
O x_train representa os dados de treinamento para as variáveis explicativas e o y_train representa as variáveis de destino.
Ao chamar esse método, o modelo treinado com base nos dados de treinamento é armazenado em clf.
joblib.dump(clf, "penguin_classifier_model.pkl")
joblib.dump() é uma função para salvar objetos Python em formato binário. Ao salvar o modelo neste formato, o modelo pode ser carregado de um arquivo e usado como está, sem a necessidade de ser treinado novamente.
import streamlit as st import numpy as np import pandas as pd import joblib
stremlit é uma biblioteca Python que facilita a criação e o compartilhamento de aplicativos da web personalizados para projetos de aprendizado de máquina e ciência de dados.
numpy é uma biblioteca Python fundamental para computação numérica. Ele fornece suporte para matrizes e matrizes grandes e multidimensionais, juntamente com uma coleção de funções matemáticas para operar nessas matrizes de forma eficiente.
data = {
"island": island,
"bill_length_mm": bill_length_mm,
"bill_depth_mm": bill_depth_mm,
"flipper_length_mm": flipper_length_mm,
"body_mass_g": body_mass_g,
"sex": sex,
}
input_df = pd.DataFrame(data, index=[0])
encode = ["island", "sex"]
input_encoded_df = pd.get_dummies(input_df, prefix=encode)
Os valores de entrada são recuperados do formulário de entrada criado pelo Stremlit e as variáveis categóricas são codificadas usando as mesmas regras de quando o modelo foi criado. Observe que a ordem de cada dado também deve ser a mesma de quando o modelo foi criado. Se a ordem for diferente, ocorrerá um erro ao executar uma previsão usando o modelo.
clf = joblib.load("penguin_classifier_model.pkl")
"penguin_classifier_model.pkl" é o arquivo onde o modelo salvo anteriormente está armazenado. Este arquivo contém um RandomForestClassifier treinado em formato binário. A execução desse código carrega o modelo no clf, permitindo usá-lo para previsões e avaliações de novos dados.
prediction = clf.predict(input_encoded_df) prediction_proba = clf.predict_proba(input_encoded_df)
clf.predict(input_encoded_df): Usa o modelo treinado para prever a classe para os novos dados de entrada codificados, armazenando o resultado na previsão.
clf.predict_proba(input_encoded_df): Calcula a probabilidade de cada classe, armazenando os resultados em Prediction_proba.
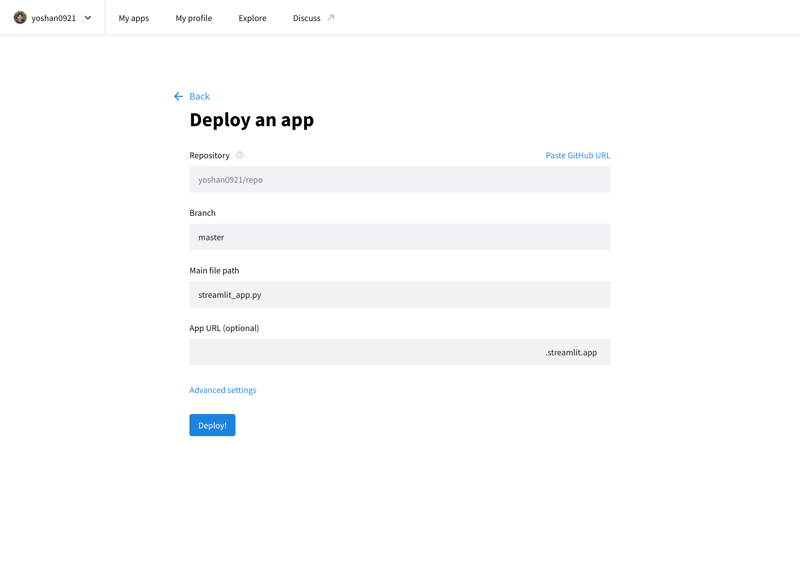
Você pode publicar seu aplicativo desenvolvido na Internet acessando o Stremlit Community Cloud (https://streamlit.io/cloud) e especificando a URL do repositório GitHub.

Arte de @allison_horst (https://github.com/allisonhorst)
O modelo é treinado usando o conjunto de dados Palmer Penguins, um conjunto de dados amplamente reconhecido para a prática de técnicas de aprendizado de máquina. Este conjunto de dados fornece informações sobre três espécies de pinguins (Adelie, Chinstrap e Gentoo) do Arquipélago Palmer, na Antártica. Os principais recursos incluem:
Este conjunto de dados é proveniente do Kaggle e pode ser acessado aqui. A diversidade de características o torna uma excelente escolha para construir um modelo de classificação e compreender a importância de cada característica na previsão de espécies.

























Isenção de responsabilidade: Todos os recursos fornecidos são parcialmente provenientes da Internet. Se houver qualquer violação de seus direitos autorais ou outros direitos e interesses, explique os motivos detalhados e forneça prova de direitos autorais ou direitos e interesses e envie-a para o e-mail: [email protected]. Nós cuidaremos disso para você o mais rápido possível.
Copyright© 2022 湘ICP备2022001581号-3