 Primeira página > Programação > Usando bibliotecas Python faker e pandas para criar dados sintéticos para teste
Primeira página > Programação > Usando bibliotecas Python faker e pandas para criar dados sintéticos para teste
Usando bibliotecas Python faker e pandas para criar dados sintéticos para teste
 Navegar:645
Navegar:645
Introdução:
Testes abrangentes são essenciais para aplicações orientadas por dados, mas muitas vezes dependem da disponibilidade dos conjuntos de dados corretos, que nem sempre estão disponíveis. Esteja você desenvolvendo aplicativos da Web, modelos de aprendizado de máquina ou sistemas de back-end, dados realistas e estruturados são cruciais para a validação adequada e para garantir um desempenho robusto. A aquisição de dados do mundo real pode ser limitada devido a questões de privacidade, restrições de licenciamento ou simplesmente à indisponibilidade de dados relevantes. É aqui que os dados sintéticos se tornam valiosos.
Neste blog, exploraremos como Python pode ser usado para gerar dados sintéticos para diferentes cenários, incluindo:
- Tabelas inter-relacionadas: representando relacionamentos um-para-muitos.
- Dados hierárquicos: frequentemente usados em estruturas organizacionais.
- Relacionamentos complexos: como relacionamentos muitos-para-muitos em sistemas de inscrição.
Aproveitaremos as bibliotecas faker e pandas para criar conjuntos de dados realistas para esses casos de uso.
Exemplo 1: Criação de dados sintéticos para clientes e pedidos (relacionamento um-para-muitos)
Em muitos aplicativos, os dados são armazenados em várias tabelas com relacionamentos de chave estrangeira. Vamos gerar dados sintéticos para clientes e seus pedidos. Um cliente pode fazer vários pedidos, representando um relacionamento um-para-muitos.
Gerando a tabela de clientes
A tabela Clientes contém informações básicas como CustomerID, nome e endereço de e-mail.
import pandas as pd
from faker import Faker
import random
fake = Faker()
def generate_customers(num_customers):
customers = []
for _ in range(num_customers):
customer_id = fake.uuid4()
name = fake.name()
email = fake.email()
customers.append({'CustomerID': customer_id, 'CustomerName': name, 'Email': email})
return pd.DataFrame(customers)
customers_df = generate_customers(10)
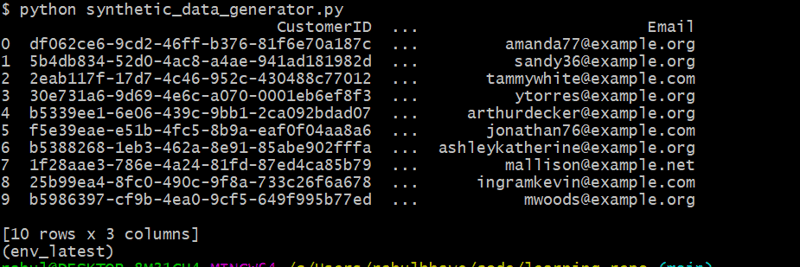
Este código gera 10 clientes aleatórios usando Faker para criar nomes e endereços de e-mail realistas.
Gerando a tabela de pedidos
Agora geramos a tabela Pedidos, onde cada pedido é associado a um cliente através do CustomerID.
def generate_orders(customers_df, num_orders):
orders = []
for _ in range(num_orders):
order_id = fake.uuid4()
customer_id = random.choice(customers_df['CustomerID'].tolist())
product = fake.random_element(elements=('Laptop', 'Phone', 'Tablet', 'Headphones'))
price = round(random.uniform(100, 2000), 2)
orders.append({'OrderID': order_id, 'CustomerID': customer_id, 'Product': product, 'Price': price})
return pd.DataFrame(orders)
orders_df = generate_orders(customers_df, 30)
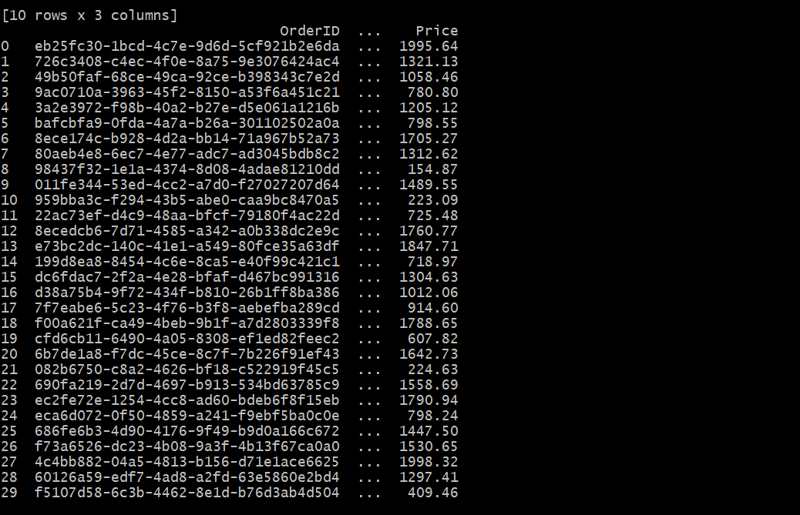
Nesse caso, a tabela Pedidos vincula cada pedido a um cliente usando o CustomerID. Cada cliente pode fazer vários pedidos, formando um relacionamento um-para-muitos.
Exemplo 2: Gerando dados hierárquicos para departamentos e funcionários
Os dados hierárquicos são frequentemente usados em ambientes organizacionais, onde os departamentos têm vários funcionários. Vamos simular uma organização com departamentos, cada um com vários funcionários.
Gerando a Tabela de Departamentos
A tabela Departamentos contém o DepartmentID, o nome e o gerente exclusivos de cada departamento.
def generate_departments(num_departments):
departments = []
for _ in range(num_departments):
department_id = fake.uuid4()
department_name = fake.company_suffix()
manager = fake.name()
departments.append({'DepartmentID': department_id, 'DepartmentName': department_name, 'Manager': manager})
return pd.DataFrame(departments)
departments_df = generate_departments(10)
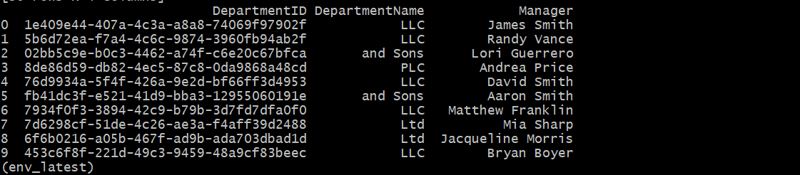
Gerando a Tabela de Funcionários
Em seguida, geramos a tabelaEmployeestable, onde cada funcionário é associado a um departamento via DepartmentID.
def generate_employees(departments_df, num_employees):
employees = []
for _ in range(num_employees):
employee_id = fake.uuid4()
employee_name = fake.name()
email = fake.email()
department_id = random.choice(departments_df['DepartmentID'].tolist())
salary = round(random.uniform(40000, 120000), 2)
employees.append({
'EmployeeID': employee_id,
'EmployeeName': employee_name,
'Email': email,
'DepartmentID': department_id,
'Salary': salary
})
return pd.DataFrame(employees)
employees_df = generate_employees(departments_df, 100)
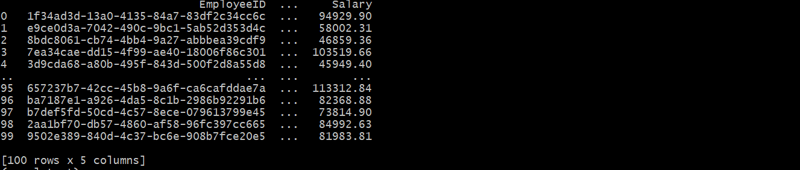
Essa estrutura hierárquica vincula cada funcionário a um departamento por meio do DepartmentID, formando um relacionamento pai-filho.
Exemplo 3: Simulação de relacionamentos muitos-para-muitos para inscrições em cursos
Em certos cenários, existem relacionamentos muitos-para-muitos, onde uma entidade se relaciona com muitas outras. Vamos simular isso com alunos matriculados em vários cursos, onde cada curso tem vários alunos.
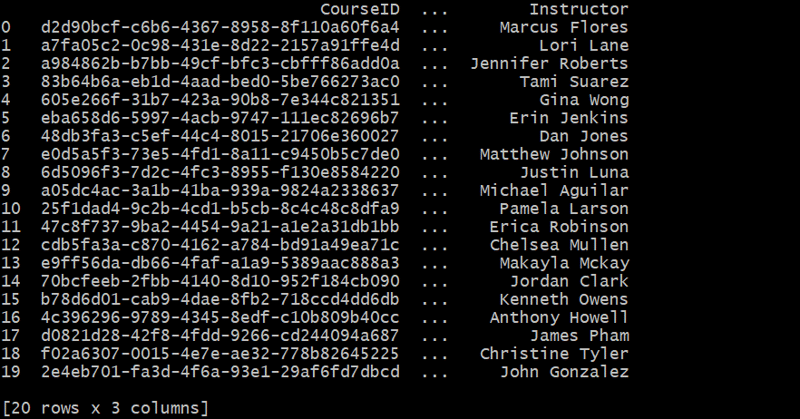
Gerando a Tabela de Cursos
def generate_courses(num_courses):
courses = []
for _ in range(num_courses):
course_id = fake.uuid4()
course_name = fake.bs().title()
instructor = fake.name()
courses.append({'CourseID': course_id, 'CourseName': course_name, 'Instructor': instructor})
return pd.DataFrame(courses)
courses_df = generate_courses(20)
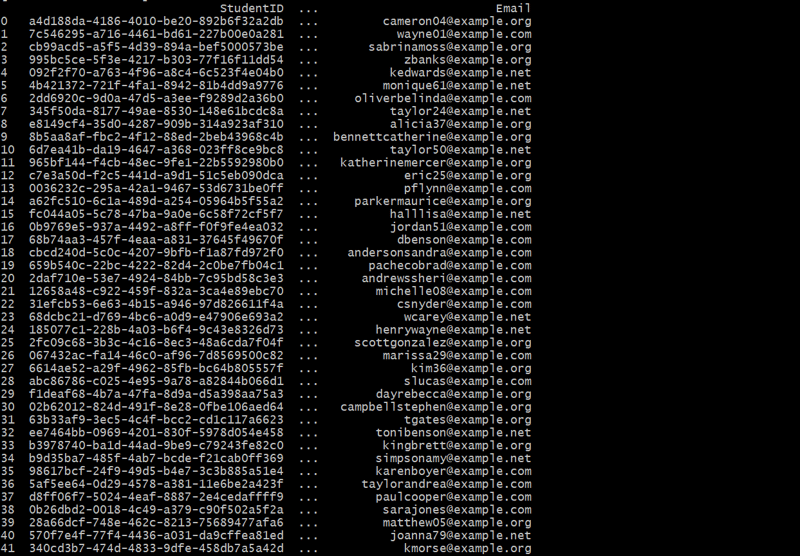
Gerando a tabela de alunos
def generate_students(num_students):
students = []
for _ in range(num_students):
student_id = fake.uuid4()
student_name = fake.name()
email = fake.email()
students.append({'StudentID': student_id, 'StudentName': student_name, 'Email': email})
return pd.DataFrame(students)
students_df = generate_students(50)
print(students_df)
Gerando a Tabela de Matrículas do Curso
A tabela CourseEnrollments captura o relacionamento muitos-para-muitos entre alunos e cursos.
def generate_course_enrollments(students_df, courses_df, num_enrollments):
enrollments = []
for _ in range(num_enrollments):
enrollment_id = fake.uuid4()
student_id = random.choice(students_df['StudentID'].tolist())
course_id = random.choice(courses_df['CourseID'].tolist())
enrollment_date = fake.date_this_year()
enrollments.append({
'EnrollmentID': enrollment_id,
'StudentID': student_id,
'CourseID': course_id,
'EnrollmentDate': enrollment_date
})
return pd.DataFrame(enrollments)
enrollments_df = generate_course_enrollments(students_df, courses_df, 200)
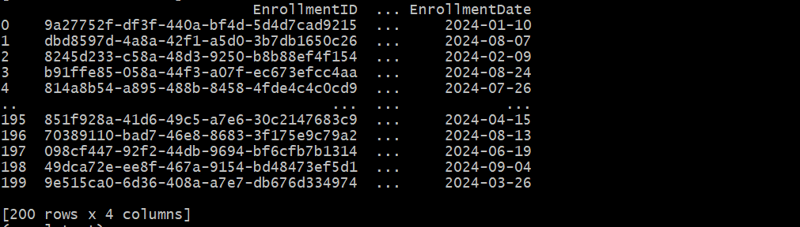
Neste exemplo, criamos uma tabela de ligação para representar relacionamentos muitos-para-muitos entre alunos e cursos.
Conclusão:
Usando Python e bibliotecas como Faker e Pandas, você pode gerar conjuntos de dados sintéticos diversificados e realistas para atender a uma variedade de necessidades de teste. Neste blog, cobrimos:
- Tabelas inter-relacionadas: demonstrando um relacionamento um-para-muitos entre clientes e pedidos.
- Dados hierárquicos: ilustrando uma relação pai-filho entre departamentos e funcionários.
- Relacionamentos Complexos: Simulando relacionamentos muitos-para-muitos entre alunos e cursos.
Esses exemplos estabelecem a base para a geração de dados sintéticos adaptados às suas necessidades. Aprimoramentos adicionais, como a criação de relacionamentos mais complexos, a personalização de dados para bancos de dados específicos ou o dimensionamento de conjuntos de dados para testes de desempenho, podem levar a geração de dados sintéticos ao próximo nível.
Esses exemplos fornecem uma base sólida para a geração de dados sintéticos. No entanto, melhorias adicionais podem ser feitas para aumentar a complexidade e especificidade, tais como:
- Dados específicos do banco de dados: personalização da geração de dados para diferentes sistemas de banco de dados (por exemplo, SQL vs. NoSQL).
- Relacionamentos mais complexos: criação de interdependências adicionais, como relacionamentos temporais, hierarquias de vários níveis ou restrições exclusivas.
- Escalonamento de dados: geração de conjuntos de dados maiores para testes de desempenho ou testes de estresse, garantindo que o sistema possa lidar com condições do mundo real em escala. Ao gerar dados sintéticos adaptados às suas necessidades, você pode simular condições realistas para desenvolver, testar e otimizar aplicativos sem depender de conjuntos de dados confidenciais ou difíceis de adquirir.
Se você gostou do artigo, compartilhe-o com seus amigos e colegas. Você pode se conectar comigo no LinkedIn para discutir outras ideias.
-
 Objetos-ajuste: a capa falha no IE e na borda, como consertar?object-fit: a capa falha no ie e borda, como corrigir? utilizando objeto-fit: cover; No CSS, para manter a altura consistente da imagem funcio...Programação Postado em 2025-04-08
Objetos-ajuste: a capa falha no IE e na borda, como consertar?object-fit: a capa falha no ie e borda, como corrigir? utilizando objeto-fit: cover; No CSS, para manter a altura consistente da imagem funcio...Programação Postado em 2025-04-08 -
Como exibir corretamente a data e a hora atuais em formato "dd/mm/yyyy hh: mm: ss.ss" em java?como exibir a data e a hora atuais em "dd/mm/yyyy hh: mm: ss.ss" formato no código java fornecido, o problema com a exibição da data...Programação Postado em 2025-04-08
-
Como posso substituir com eficiência várias substringas em uma string java?substituindo várias substâncias em uma string com eficiência em java quando confrontado com a necessidade de substituir várias substringas den...Programação Postado em 2025-04-08
-
Por que estou recebendo um erro "não consegui encontrar uma implementação do padrão de consulta" na minha consulta Silverlight Linq?ausência de implementação do padrão de consulta: resolvendo "não conseguiu encontrar" erros em um aplicativo Silverlight, uma tentat...Programação Postado em 2025-04-08
-
Como converter uma coluna Pandas Dataframe em formato e filtrar por data de tempo por data?transformar a coluna Pandas Dataframe em DateTime Format cenário: Dados em um dataframe de pandas frequentemente existe em vários formatos, ...Programação Postado em 2025-04-08
-
Como posso personalizar otimizações de compilação no compilador Go?personalizando otimizações de compilação no Go Compiler O processo de compilação padrão em Go segue uma estratégia de otimização específica. N...Programação Postado em 2025-04-08
-
Como combinar dados de três tabelas MySQL em uma nova tabela?mysql: Criando uma nova tabela a partir de dados e colunas de três tabelas pergunta: como eu posso criar uma tabela que a tabela se selecio...Programação Postado em 2025-04-08
-
Como remover os manipuladores anônimos de eventos JavaScript de maneira limpa?removendo os ouvintes anônimos do evento adicionando ouvintes de eventos anônimos a elementos fornece flexibilidade e simplicidade, mas quando é...Programação Postado em 2025-04-08
-
Qual método é mais eficiente para a detecção de ponto em polígono: rastreamento de raio ou path.contains_points?detecção de ponto-em-polígono eficiente em python determinar se um ponto está dentro de um polígono é uma tarefa frequente na geometria computac...Programação Postado em 2025-04-08
-
Por que o Firefox exibe imagens usando a propriedade CSS `Content`?exibindo imagens com URL de conteúdo em Firefox Um problema foi encontrado onde certos navegadores, especificamente Firefox, falham em exibir ...Programação Postado em 2025-04-08
-
Como verificar se um objeto tem um atributo específico no Python?Método para determinar o atributo de objeto Existence Esta consulta busca um método para verificar a presença de um atributo específico em um ...Programação Postado em 2025-04-08
-
Como recuperar com eficiência a última linha para cada identificador exclusivo no PostGresql?postGresql: Extraindo a última linha para cada identificador exclusivo em postgresql, você pode encontrar situações em que você precisa extrai...Programação Postado em 2025-04-08
-
Como remover emojis das cordas em Python: um guia para iniciantes para corrigir erros comuns?removendo os emojis de strings em python o código Python fornecido para remover emojis falha porque contém syntaxe erros. As cadeias de unicod...Programação Postado em 2025-04-08
-
Por que não está aparecendo na minha imagem de fundo do CSS?SOLHAÇÃO DE TRABALHO: CSS Imagem de fundo não apareceu Você encontrou um problema em que sua imagem em segundo plano falha, apesar das seguint...Programação Postado em 2025-04-08
-
Como posso concatenar com segurança o texto e os valores ao construir consultas SQL em Go?concatenando texto e valores em go sql Queries Ao construir uma consulta SQL texth e, em codificação, e a signa e a consulta de syntax e a sín...Programação Postado em 2025-04-08















Estude chinês
- 1 Como se diz “andar” em chinês? 走路 Pronúncia chinesa, 走路 aprendizagem chinesa
- 2 Como se diz “pegar um avião” em chinês? 坐飞机 Pronúncia chinesa, 坐飞机 aprendizagem chinesa
- 3 Como se diz “pegar um trem” em chinês? 坐火车 Pronúncia chinesa, 坐火车 aprendizagem chinesa
- 4 Como se diz “pegar um ônibus” em chinês? 坐车 Pronúncia chinesa, 坐车 aprendizagem chinesa
- 5 Como se diz dirigir em chinês? 开车 Pronúncia chinesa, 开车 aprendizagem chinesa
- 6 Como se diz nadar em chinês? 游泳 Pronúncia chinesa, 游泳 aprendizagem chinesa
- 7 Como se diz andar de bicicleta em chinês? 骑自行车 Pronúncia chinesa, 骑自行车 aprendizagem chinesa
- 8 Como você diz olá em chinês? 你好Pronúncia chinesa, 你好Aprendizagem chinesa
- 9 Como você agradece em chinês? 谢谢Pronúncia chinesa, 谢谢Aprendizagem chinesa
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









