
Como baixar e instalar o Llama 2 localmente
 Navegar:746
Navegar:746
Com isso em mente, criamos um guia passo a passo sobre como usar Text-Generation-WebUI para carregar um Llama 2 LLM quantizado localmente em seu computador.
Por que instalar o Llama 2 localmente
Há muitos motivos pelos quais as pessoas optam por executar o Llama 2 diretamente. Alguns fazem isso por questões de privacidade, alguns para personalização e outros para recursos offline. Se você estiver pesquisando, ajustando ou integrando o Llama 2 para seus projetos, acessar o Llama 2 via API pode não ser para você. O objetivo de executar um LLM localmente em seu PC é reduzir a dependência de ferramentas de IA de terceiros e usar IA a qualquer hora, em qualquer lugar, sem se preocupar com o vazamento de dados potencialmente confidenciais para empresas e outras organizações.
Dito isso, vamos começar com o guia passo a passo para instalar o Llama 2 localmente.
Etapa 1: Instale a ferramenta de compilação do Visual Studio 2019
Para simplificar as coisas, usaremos um instalador de um clique para Text-Generation-WebUI (o programa usado para carregar o Llama 2 com GUI) . Porém, para que este instalador funcione, você precisa baixar a ferramenta de compilação do Visual Studio 2019 e instalar os recursos necessários.
Download:Visual Studio 2019 (gratuito)
Vá em frente e baixe a edição comunitária do software. Agora instale o Visual Studio 2019 e abra o software. Depois de aberto, marque a caixa Desenvolvimento de desktop com C e clique em instalar.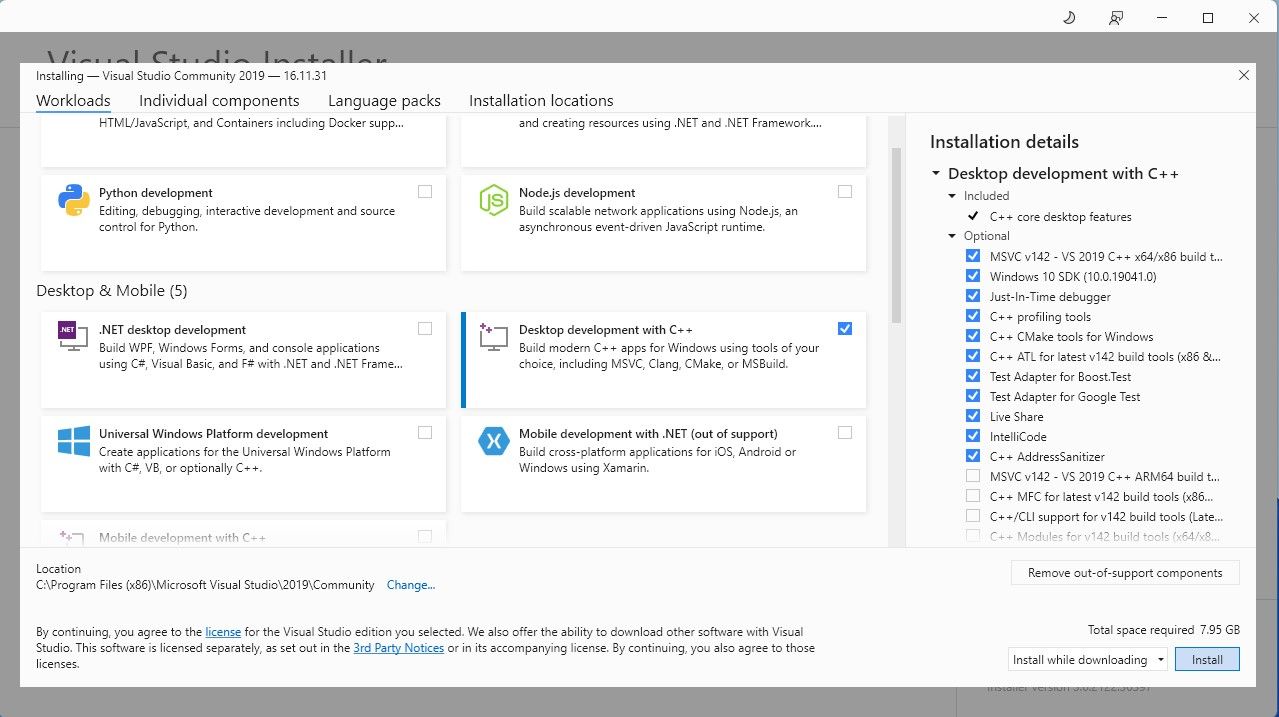
Agora que você tem o desenvolvimento de desktop com C instalado, é hora de baixar o instalador de um clique Text-Generation-WebUI.
Etapa 2: Instale Text-Generation-WebUI
O instalador de um clique Text-Generation-WebUI é um script que cria automaticamente as pastas necessárias e configura o ambiente Conda e todos os requisitos necessários para executar um modelo de IA.
Para instalar o script, baixe o instalador com um clique clicando em Código > Baixar ZIP.
Download:Text-Generation-WebUI Installer (gratuito)
Depois de baixado, extraia o arquivo ZIP para o local de sua preferência e abra a pasta extraída. Dentro da pasta, role para baixo e procure o programa de inicialização apropriado para o seu sistema operacional. Execute os programas clicando duas vezes no script apropriado. Se você estiver no Windows, selecione o arquivo em lote start_windows para MacOS, selecione o script de shell start_macos para Linux, script de shell start_linux.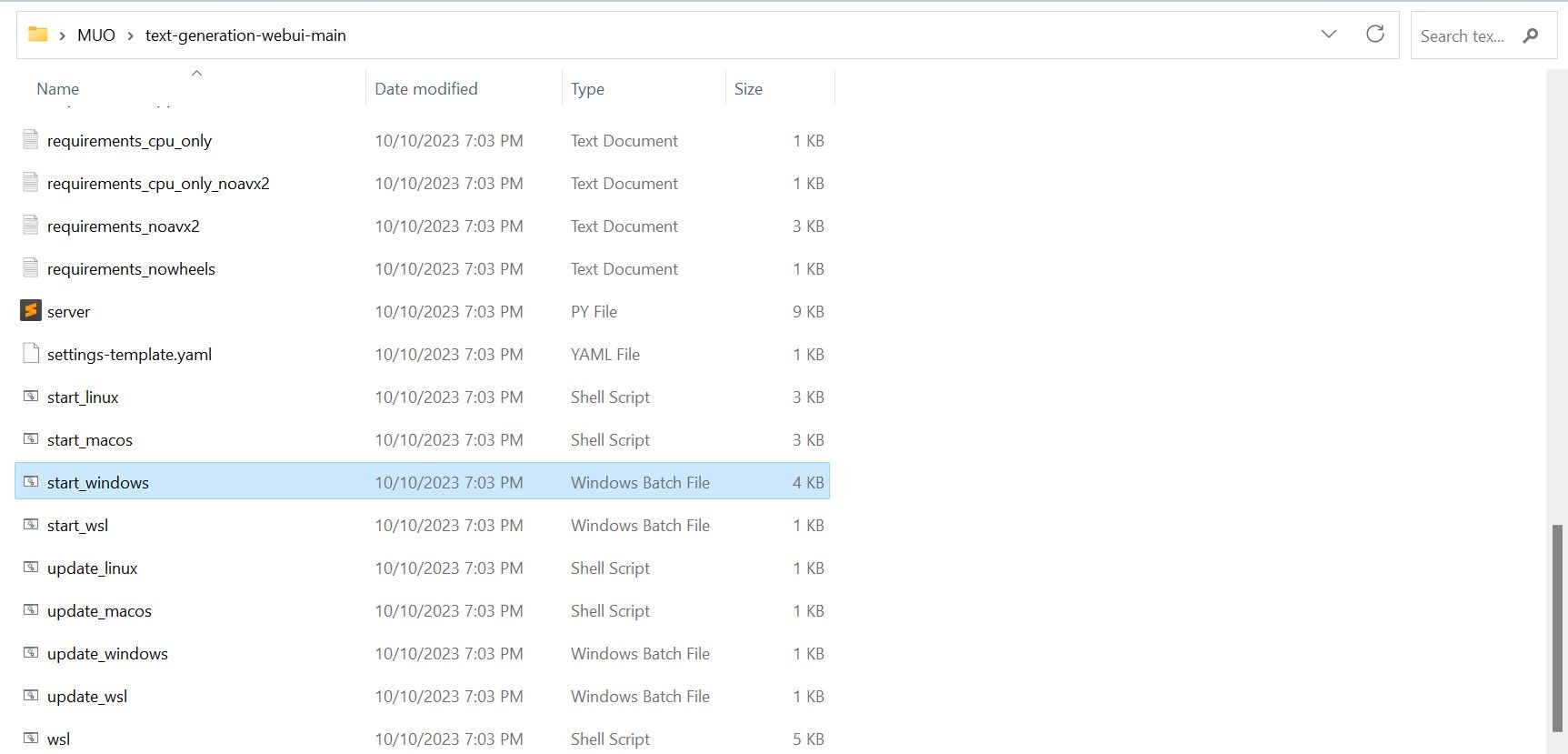
Seu antivírus pode criar um alerta; isso está bem. O prompt é apenas um falso positivo de antivírus para executar um arquivo em lote ou script. Clique em Executar mesmo assim. Um terminal será aberto e iniciará a configuração. No início, a configuração fará uma pausa e perguntará qual GPU você está usando. Selecione o tipo apropriado de GPU instalado em seu computador e pressione Enter. Para quem não tem placa gráfica dedicada, selecione Nenhum (quero rodar modelos no modo CPU). Tenha em mente que a execução no modo CPU é muito mais lenta quando comparada à execução do modelo com uma GPU dedicada.
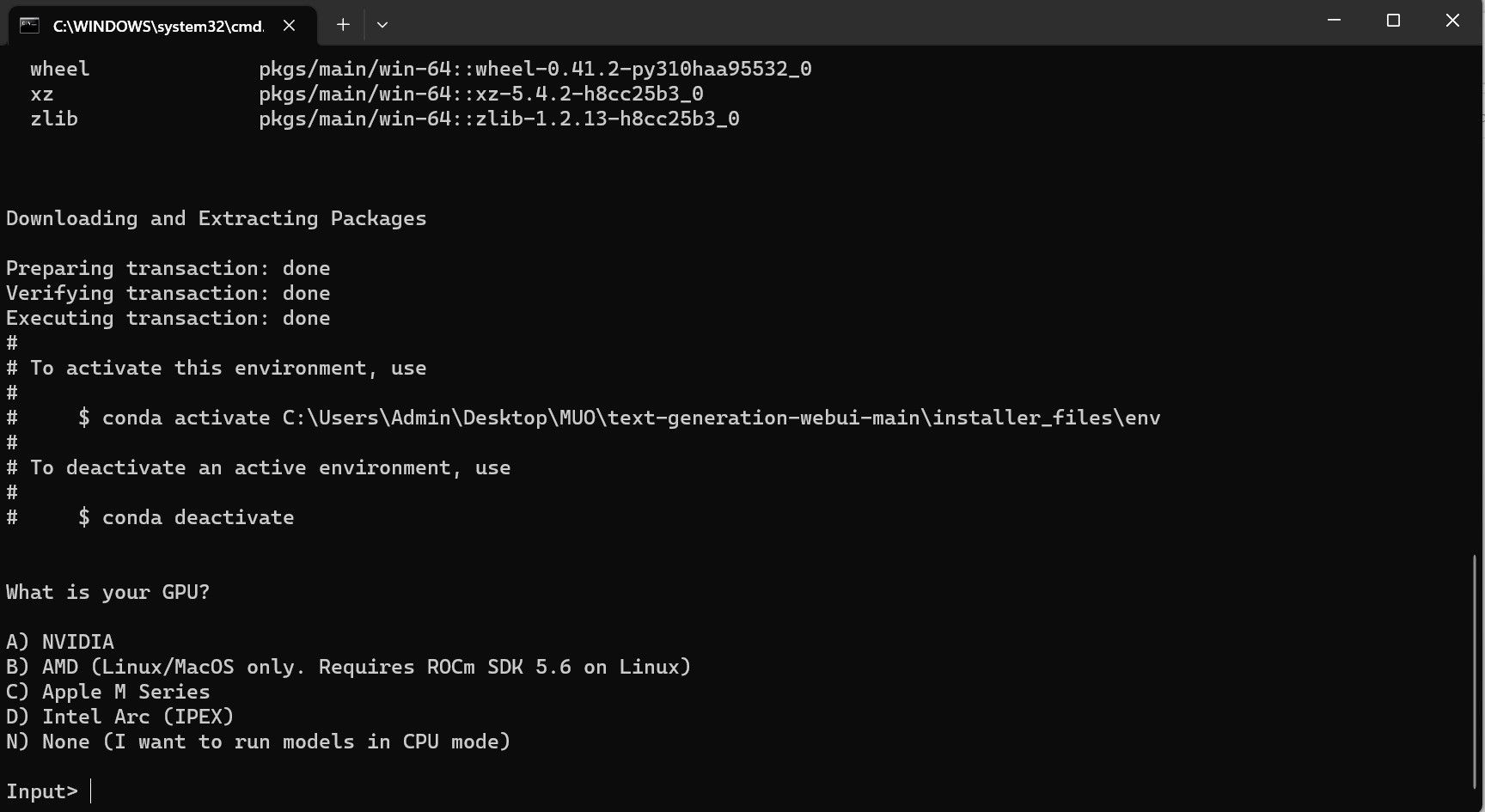 Assim que a configuração for concluída, agora você pode iniciar o Text-Generation-WebUI localmente. Você pode fazer isso abrindo seu navegador preferido e inserindo o endereço IP fornecido na URL.
Assim que a configuração for concluída, agora você pode iniciar o Text-Generation-WebUI localmente. Você pode fazer isso abrindo seu navegador preferido e inserindo o endereço IP fornecido na URL.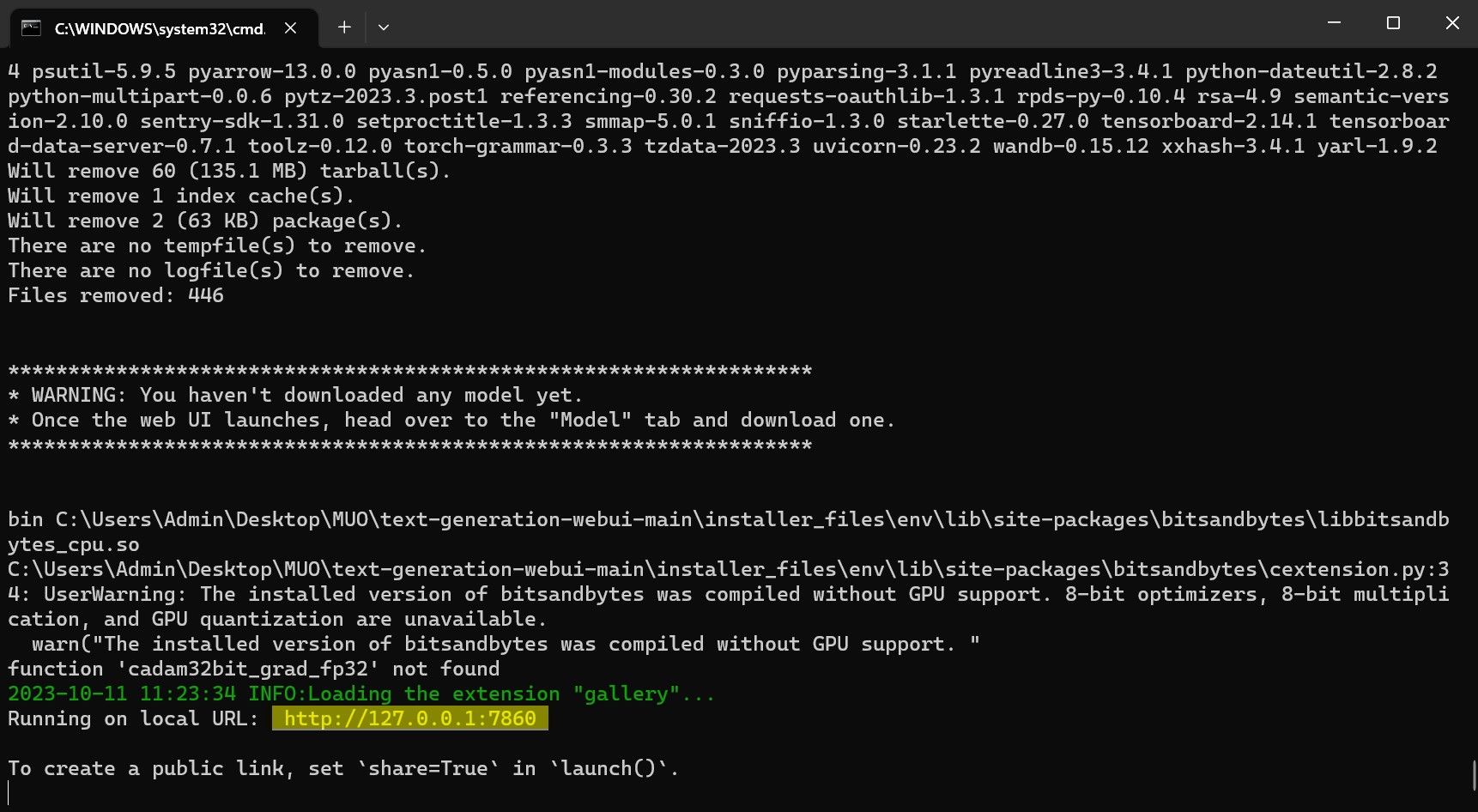 A WebUI agora está pronta para uso.
A WebUI agora está pronta para uso.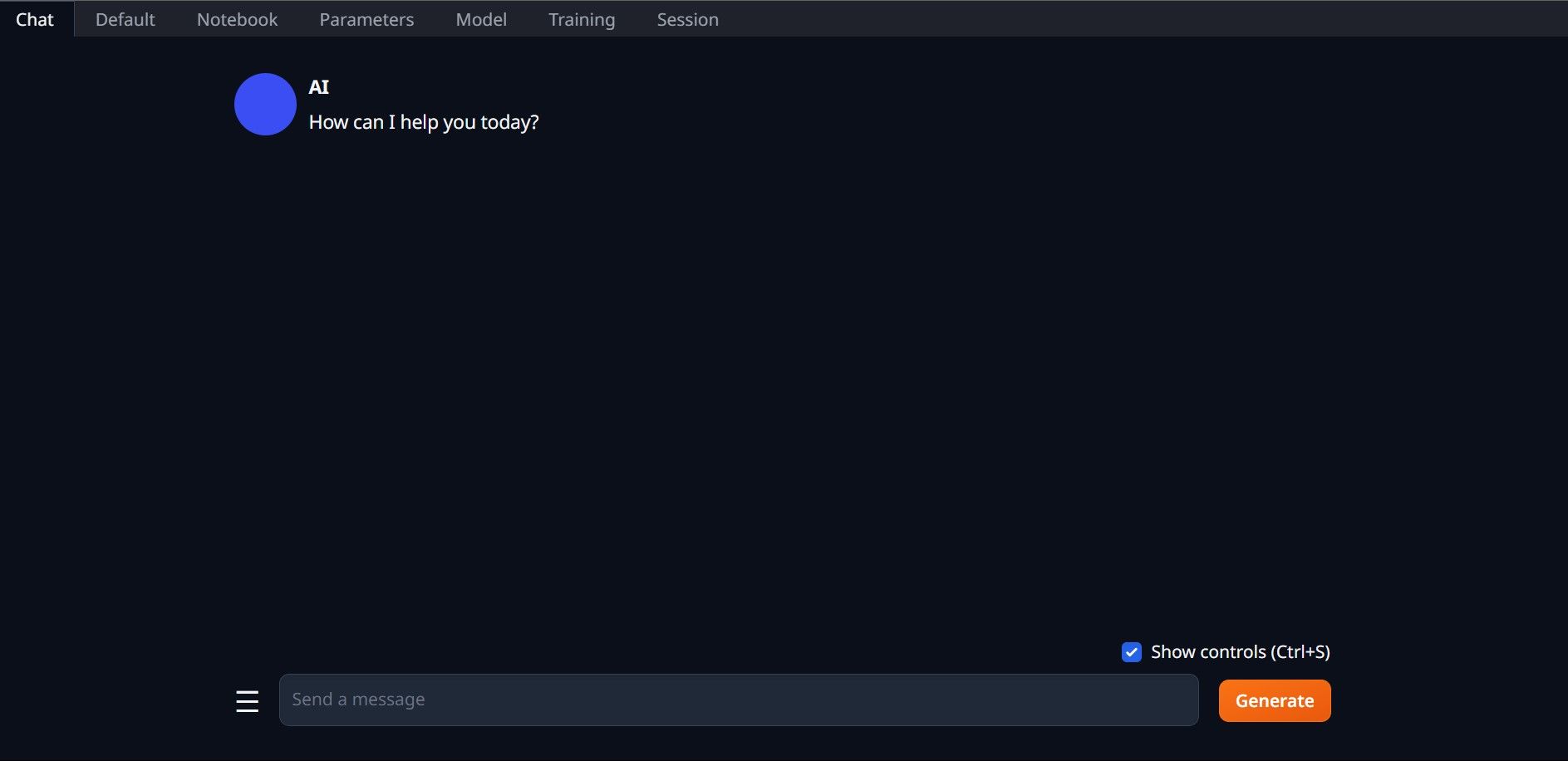
No entanto, o programa é apenas um carregador de modelo. Vamos baixar o Llama 2 para iniciar o carregador de modelo.
Etapa 3: Baixe o modelo do Llama 2
Há algumas coisas a serem consideradas ao decidir qual iteração do Llama 2 você precisa. Isso inclui parâmetros, quantização, otimização de hardware, tamanho e uso. Todas essas informações serão encontradas indicadas no nome do modelo.
Parâmetros: o número de parâmetros usados para treinar o modelo. Parâmetros maiores tornam modelos mais capazes, mas à custa do desempenho. Uso: Pode ser padrão ou chat. Um modelo de chat é otimizado para ser usado como um chatbot como o ChatGPT, enquanto o modelo padrão é o modelo padrão. Otimização de Hardware: Refere-se a qual hardware executa melhor o modelo. GPTQ significa que o modelo é otimizado para rodar em uma GPU dedicada, enquanto GGML é otimizado para rodar em uma CPU. Quantização: Denota a precisão dos pesos e ativações em um modelo. Para inferência, uma precisão de q4 é ideal. Tamanho: Refere-se ao tamanho do modelo específico.Observe que alguns modelos podem ser organizados de forma diferente e podem até não ter os mesmos tipos de informações exibidas. No entanto, esse tipo de convenção de nomenclatura é bastante comum na biblioteca do modelo HuggingFace, portanto, ainda vale a pena entendê-la.

Neste exemplo, o modelo pode ser identificado como um modelo Llama 2 de tamanho médio treinado em 13 bilhões de parâmetros otimizados para inferência de chat usando uma CPU dedicada.
Para quem roda em GPU dedicada, escolha um modelo GPTQ, enquanto para quem usa CPU, escolha GGML. Se você quiser bater um papo com o modelo como faria com o ChatGPT, escolha chat, mas se quiser experimentar o modelo com todos os seus recursos, use o modelo padrão. Quanto aos parâmetros, saiba que utilizar modelos maiores proporcionará melhores resultados em detrimento do desempenho. Eu pessoalmente recomendo que você comece com um modelo 7B. Quanto à quantização, use q4, pois serve apenas para inferência.
Download:GGML (grátis)
Download:GPTQ (grátis)
Agora que você sabe qual iteração do Llama 2 você precisa, vá em frente e baixe o modelo desejado .
No meu caso, como estou executando isso em um ultrabook, usarei um modelo GGML ajustado para chat, llama-2-7b-chat-ggmlv3.q4_K_S.bin.
Após a conclusão do download, coloque o modelo em text-generation-webui-main > models.
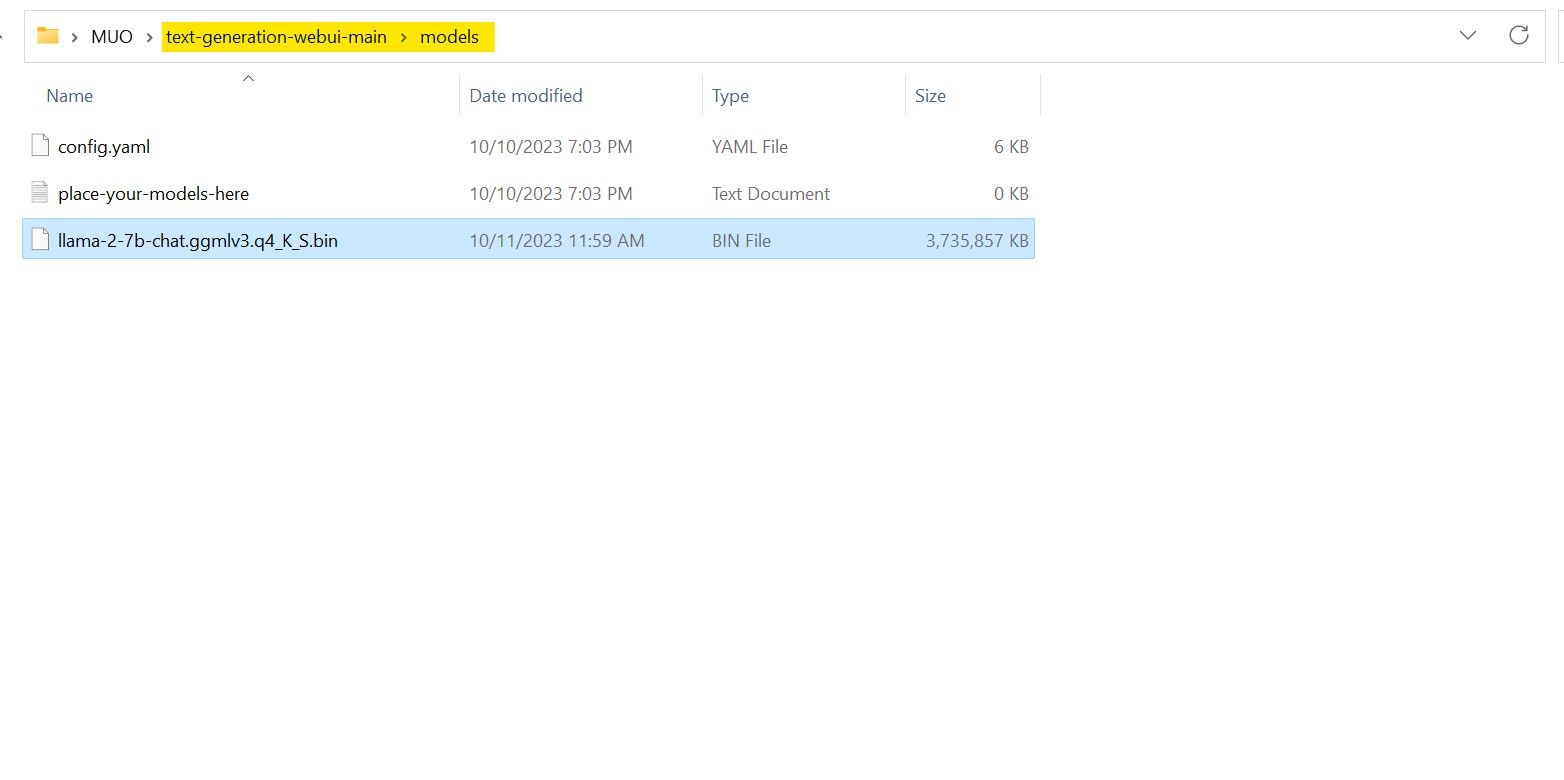
Agora que seu modelo foi baixado e colocado na pasta de modelos, é hora de configurar o carregador de modelo.
Etapa 4: Configurar Text-Generation-WebUI
Agora, vamos começar a fase de configuração.
Mais uma vez, abra Text-Generation-WebUI executando o arquivo start_(seu sistema operacional) (veja as etapas anteriores acima). Nas guias localizadas acima da GUI, clique em Modelo. Clique no botão atualizar no menu suspenso do modelo e selecione seu modelo. Agora clique no menu suspenso do carregador de modelo e selecione AutoGPTQ para quem usa um modelo GTPQ e ctransformers para quem usa um modelo GGML. Por fim, clique em Carregar para carregar seu modelo.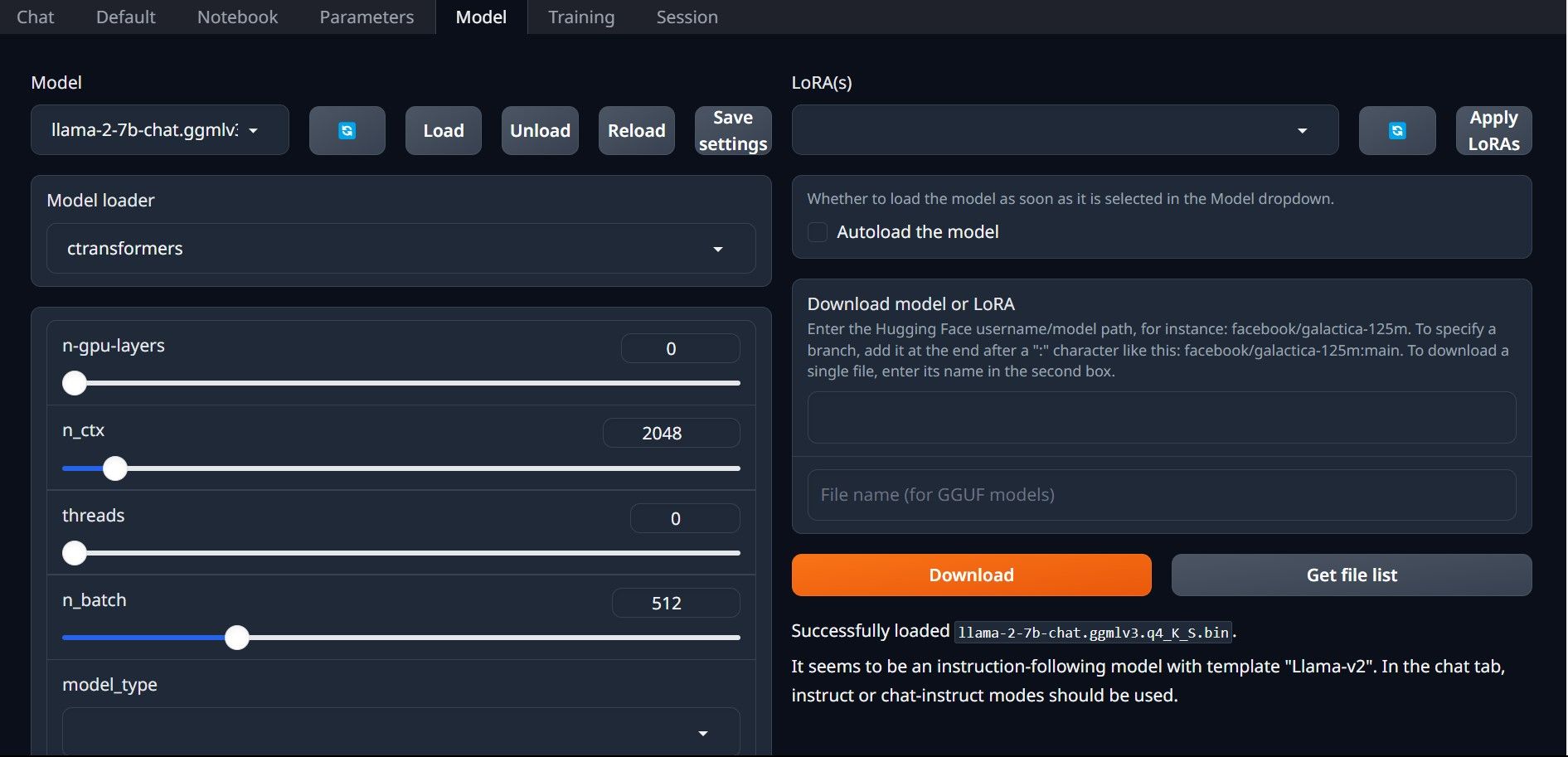 Para usar o modelo, abra a aba Chat e comece a testar o modelo.
Para usar o modelo, abra a aba Chat e comece a testar o modelo.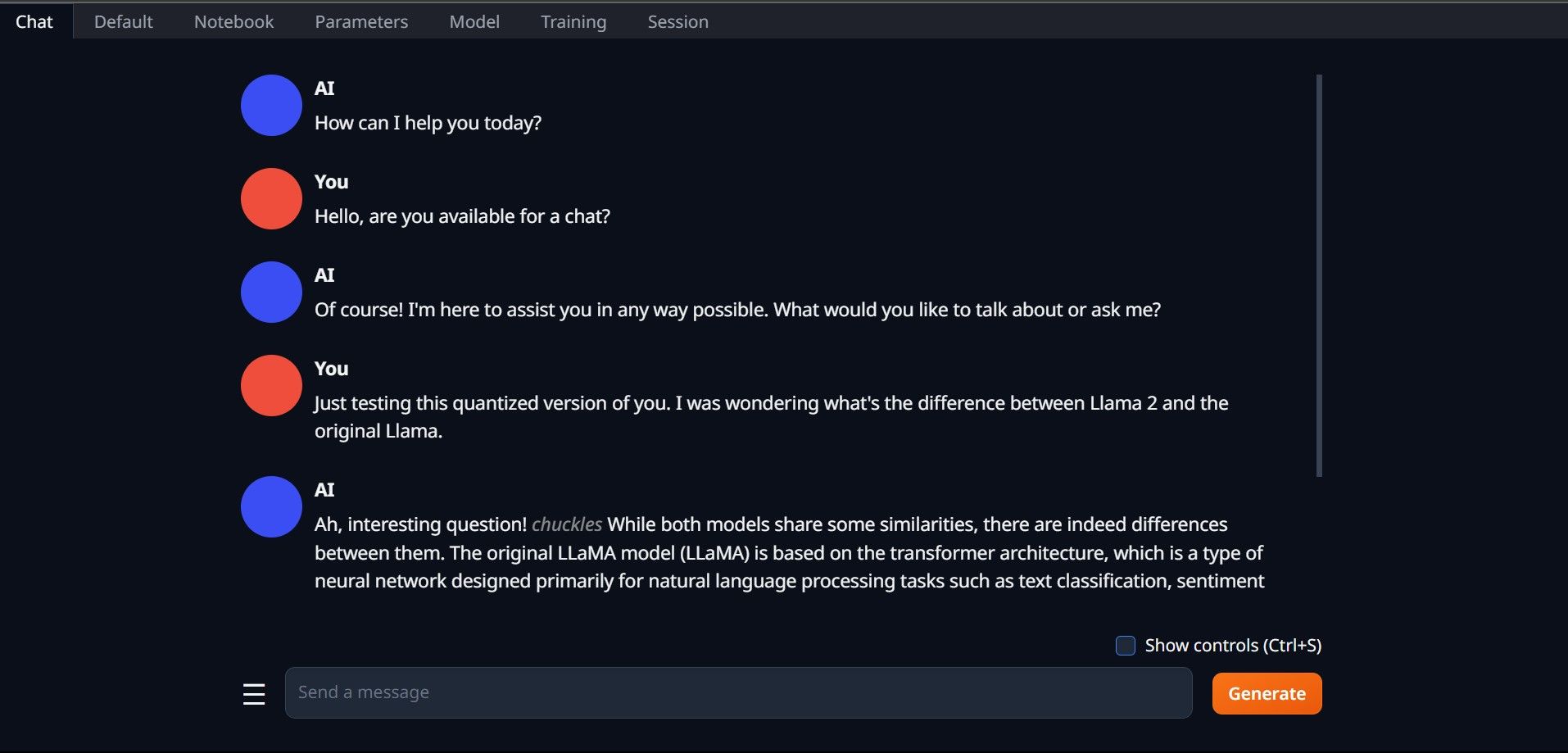
Parabéns, você carregou o Llama2 com sucesso em seu computador local!
Experimente outros LLMs
Agora que você sabe como executar o Llama 2 diretamente no seu computador usando Text-Generation-WebUI, você também deverá ser capaz de executar outros LLMs além do Llama. Basta lembrar as convenções de nomenclatura dos modelos e que apenas versões quantizadas de modelos (geralmente com precisão q4) podem ser carregadas em PCs normais. Muitos LLMs quantizados estão disponíveis no HuggingFace. Se você quiser explorar outros modelos, pesquise TheBloke na biblioteca de modelos do HuggingFace e você encontrará muitos modelos disponíveis.
-
 Deepseek-V3 vs. GPT-4O e LLAMA 3.3 70B: o modelo de IA mais forte reveladoThe evolution of AI language models has set new standards, especially in the coding and programming landscape. Leading the c...IA Postado em 2025-04-18
Deepseek-V3 vs. GPT-4O e LLAMA 3.3 70B: o modelo de IA mais forte reveladoThe evolution of AI language models has set new standards, especially in the coding and programming landscape. Leading the c...IA Postado em 2025-04-18 -
As 5 principais ferramentas de orçamento inteligentes da IAdesbloqueando a liberdade financeira com a IA: os principais aplicativos de orçamento na Índia Você está cansado de se perguntar constantemente par...IA Postado em 2025-04-17
-
Explicação detalhada da função do Excel Sumproduct - Escola de Análise de DadosFunção Sumproduct do Excel: uma análise de análise de dados desbloqueia o poder da função Sumproduct do Excel para análise de dados simplificada. E...IA Postado em 2025-04-16
-
Pesquisas aprofundadas estão totalmente abertas, os benefícios do usuário do ChatGPT PlusPesquisa profunda do OpenAI: um divisor de águas para pesquisa de IA o OpenAI lançou pesquisas profundas para todos os assinantes ChatGPT Plus, pro...IA Postado em 2025-04-16
-
Amazon Nova Today Experiência e Revisão Real - Analytics VidhyaAmazon revela a Nova: modelos de fundação de ponta para AI aprimorada e criação de conteúdo A Amazon Re: Invent 2024 Event mostrou Nova, seu conjun...IA Postado em 2025-04-16
-
5 maneiras de usar a função de tarefa de tempo de chatgptAs novas tarefas agendadas do chatgpt: automatize seu dia com ai O ChatGPT apresentou recentemente um recurso de mudança de jogo: tarefas agendadas...IA Postado em 2025-04-16
-
Qual dos três chatbots da IA responde ao mesmo aviso é o melhor?com opções como Claude, Chatgpt e Gemini, escolher um chatbot pode parecer esmagador. Para ajudar a cortar o ruído, coloquei todos os três à prova...IA Postado em 2025-04-15
-
ChatGPT é suficiente, nenhuma máquina de chat de IA dedicada é necessáriaEm um mundo com novos chatbots de AI lançados diariamente, pode ser esmagador decidir qual é o "único" certo. Mas, na minha experiência, o ...IA Postado em 2025-04-14
-
Momento indiano da IA: competição com a China e os Estados Unidos em IA generativaAmbições da AI da Índia: uma atualização de 2025 Com a China e os EUA investindo fortemente em IA generativa, a Índia está acelerando suas próprias...IA Postado em 2025-04-13
-
Automatando a importação de CSV para PostgreSQL usando o fluxo de ar e o dockerEste tutorial demonstra a criação de um pipeline de dados robusto usando o Apache Airflow, Docker e PostgreSQL para automatizar a transferência de da...IA Postado em 2025-04-12
-
Algoritmos de inteligência de enxames: três implementações do PythonImagine watching a flock of birds in flight. There's no leader, no one giving directions, yet they swoop and glide together in perfect harmony. It may...IA Postado em 2025-03-24
-
Como tornar seu LLM mais preciso com pano e ajuste finoImagine studying a module at university for a semester. At the end, after an intensive learning phase, you take an exam – and you can recall th...IA Postado em 2025-03-24
-
O que é o Google Gemini? Tudo o que você precisa saber sobre o rival ChatGPT do GoogleGoogle recently released its new Generative AI model, Gemini. It results from a collaborative effort by a range of teams at Google, including members ...IA Postado em 2025-03-23
-
Guia sobre solicitação com DSPYdspy: uma estrutura declarativa para a construção e melhoria de aplicativos LLM DSPY (programas de idiomas auto-improvantes declarativos) revolucio...IA Postado em 2025-03-22
-
Automatize o blog para o tópico do TwitterEste artigo detalha automatização da conversão de conteúdo de formato longo (como postagens de blog) em tópicos envolventes no Twitter usando o gemin...IA Postado em 2025-03-11















Estude chinês
- 1 Como se diz “andar” em chinês? 走路 Pronúncia chinesa, 走路 aprendizagem chinesa
- 2 Como se diz “pegar um avião” em chinês? 坐飞机 Pronúncia chinesa, 坐飞机 aprendizagem chinesa
- 3 Como se diz “pegar um trem” em chinês? 坐火车 Pronúncia chinesa, 坐火车 aprendizagem chinesa
- 4 Como se diz “pegar um ônibus” em chinês? 坐车 Pronúncia chinesa, 坐车 aprendizagem chinesa
- 5 Como se diz dirigir em chinês? 开车 Pronúncia chinesa, 开车 aprendizagem chinesa
- 6 Como se diz nadar em chinês? 游泳 Pronúncia chinesa, 游泳 aprendizagem chinesa
- 7 Como se diz andar de bicicleta em chinês? 骑自行车 Pronúncia chinesa, 骑自行车 aprendizagem chinesa
- 8 Como você diz olá em chinês? 你好Pronúncia chinesa, 你好Aprendizagem chinesa
- 9 Como você agradece em chinês? 谢谢Pronúncia chinesa, 谢谢Aprendizagem chinesa
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









