 Primeira página > Programação > API de dados para Amazon Aurora Serverless com AWS SDK para Java - Parte Aurora Serverless vata API atende ao DevOps Guru ou não?
Primeira página > Programação > API de dados para Amazon Aurora Serverless com AWS SDK para Java - Parte Aurora Serverless vata API atende ao DevOps Guru ou não?
API de dados para Amazon Aurora Serverless com AWS SDK para Java - Parte Aurora Serverless vata API atende ao DevOps Guru ou não?
 Navegar:396
Navegar:396
Introdução
Em meu artigo Amazon DevOps Guru para aplicativos Serverless - Parte 10 Detecção de anomalias no Aurora Serverless v2, aprendemos que o DevOps Guru foi capaz de detectar anomalias com êxito com o banco de dados Aurora (Serverless v2) PostgreSQL no caso de função Lambda com Java 21 gerenciado o tempo de execução foi conectado a ele via JDBC. Escalamos nosso banco de dados apenas de 0,5 para 1 ACU e criamos uma carga muito alta no banco de dados invocando a função Lambda para recuperar o produto por ID várias centenas de vezes simultaneamente por vários minutos. Vimos que o DevOps Guru apontou corretamente para o aumento da soma de conexões de banco de dados e para a carga constantemente alta do banco de dados (CPU). Neste artigo, gostaria de descobrir se o DevOps Guru detectará a anomalia fazendo o mesmo experimento, mas usando a API de dados para Aurora Serverless v2 com AWS SDK para Java em vez de JDBC.
Detecção de anomalias no Aurora Serverless v2 com API de dados
Vamos dar uma olhada em nosso aplicativo de exemplo e usar o modelo SAM para criar infraestrutura e implantar o aplicativo descrito na imagem a seguir:
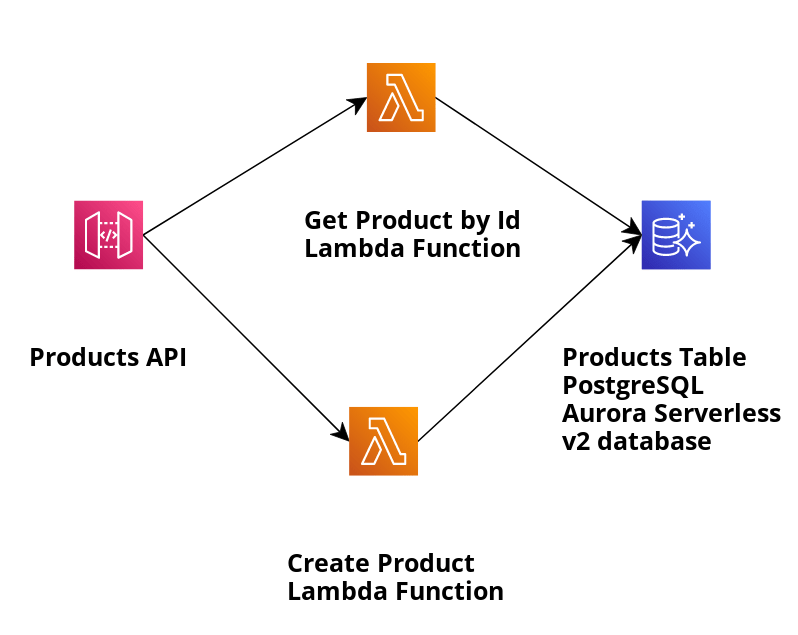
O aplicativo cria produtos armazenados no banco de dados Aurora Serverless v2 PostgreSQL e os recupera por ID usando a API de dados. A função Lambda relevante que usaremos para recuperar o produto por seu ID é GetProductByIdViaAuroraServerlessV2DataApi e sua implementação de manipulador é GetProductByIdViaAuroraServerlessV2DataApiHandler.
Como no artigo anterior, usamos a ferramenta hey para realizar o teste de estresse como este
hey -z 15m -c 300 -H "X-API-Key: XXXa6XXXX" https://XXX.execute-api.eu-central-1.amazonaws.com/prod/productsWithDataApi/1
Neste exemplo, invocamos o endpoint do API Gateway com 300 contêineres simultâneos por 15 minutos. Por trás do endpoint prod/productsWithoutDataApi, a função Lambda GetProductByIdViaAuroraServerlessV2WithoutDataApi será invocada, recuperando o produto pelo id 1 do banco de dados Aurora Serverless v2 PostgreSQL.
Configuramos em nosso [modelo SAM]((https://github.com/Vadym79/AWSLambdaJavaAuroraServerlessV2DataApi/blob/master/template.yaml) cluster de banco de dados Aurora para escalar da capacidade mínima de 0,5 para a capacidade máxima de 1 ACU (que é tamanho de banco de dados muito pequeno) no caso de aumento de carga para fins de redução de custos.
AuroraServerlessV2Cluster:
Type: 'AWS::RDS::DBCluster'
...
ServerlessV2ScalingConfiguration:
MinCapacity: 0.5
MaxCapacity: 1
O banco de dados Aurora (Serverless v2) gerencia o número máximo de conexões de banco de dados disponíveis proporcionalmente ao tamanho do banco de dados (em nosso caso, a configuração ACU) também com Data API para Aurora Serverless v2 (que é uma grande diferença para v1, que se tornará sem suporte no final do ano de 2024, onde havia uma cota rígida de 1.000 conexões de banco de dados por segundo). Para obter mais informações, leia a documentação sobre Conexões máximas para Aurora Serverless v2. Portanto, com o aumento do número de invocações, esperamos atingir em breve o número máximo de conexões de banco de dados disponíveis e alta carga de banco de dados (CPU), para que o banco de dados não seja capaz de responder às novas solicitações de função do Lambda para recuperar o produto por id (o Lambda também será executado). Com isso iremos provocar a anomalia e gostaríamos de saber se o DevOps Guru será capaz de detectá-la. E foi capaz, mais ou menos... O seguinte insight foi gerado:
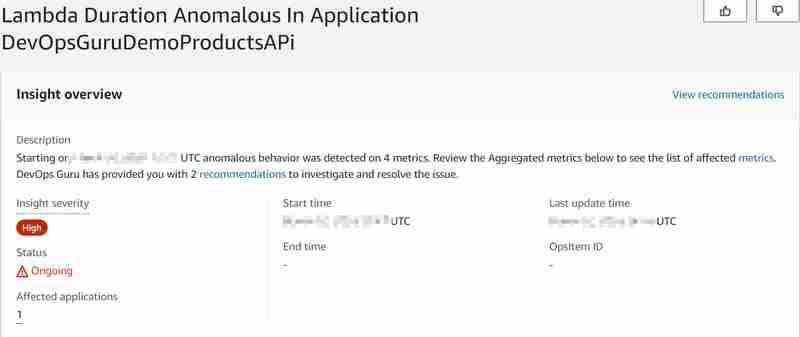
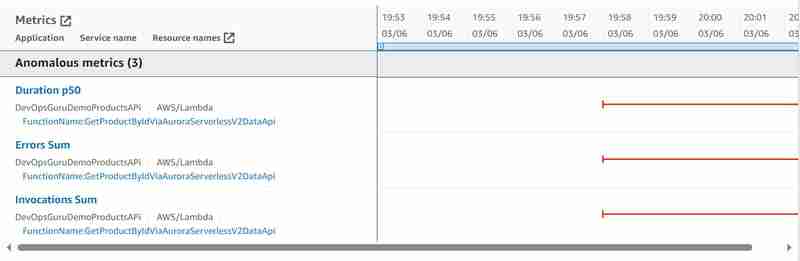
.
Em termos de utilização/escala da ACU, ambos parecem iguais:
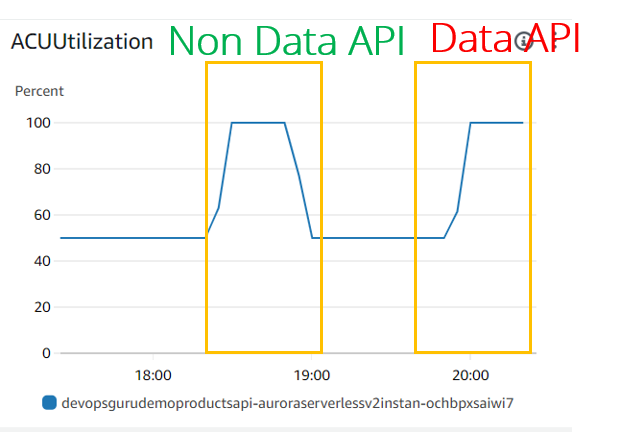
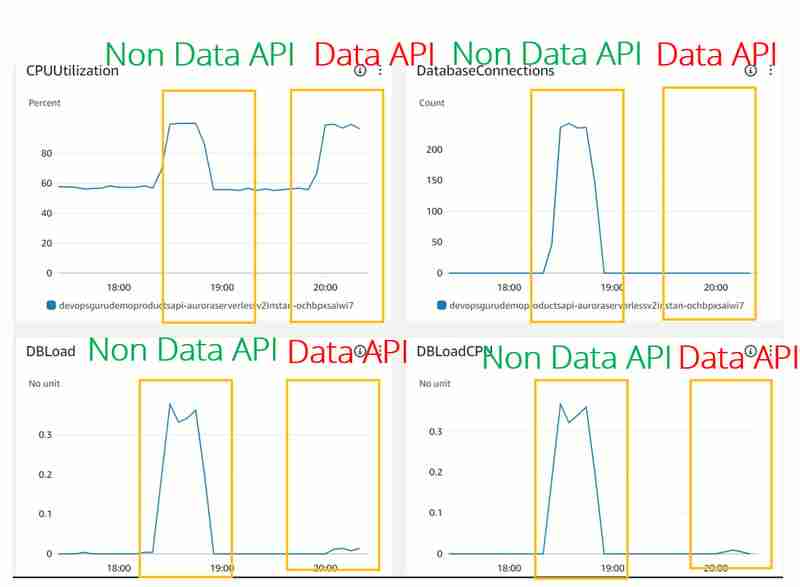
- A utilização da CPU parece a mesma para casos de JDBC (API não de dados) e API de dados. Mas o DevOps Guru parece não considerar essa métrica, pois não a vimos nem mesmo para o experimento JDBC
- DBLoad(CPU) que é muito baixo para uso da API de dados. Parece que para a API Dat existe algum Load Balancer na frente do banco de dados Aurora Serverless v2 que monitora o uso da conexão e protege o banco de dados contra sobrecarga.
- A métrica DatabaseConnection não é mostrada (ou mostrada como 0) para uso da API de dados. A razão para isso é que não gerenciamos a conexão do banco de dados para a API de dados, isso é feito do outro lado para nós. É claro que eles ainda desempenham um papel importante que aprendemos em Conexões máximas para Aurora Serverless v2, mas essa métrica parece estar exposta externamente nas métricas do CloudWatch e mesmo o DevOps Guru não tem acesso aos números reais.
- Com isso e DBLoad(CPU) muito baixo, nenhum insight do DevOps Guru para o cluster Aurora Serverless v2 com uso de API de dados foi gerado em comparação com o caso de uso JDBC.
Fiz o segundo experimento conectando-me diretamente ao cluster Aurora Serverless v2 e escrevi o script para criar o teste de carga escrevendo o script que busca o produto por ID várias centenas de vezes usando a maneira padrão (API sem dados). Semelhante ao que fizemos com a ferramenta hey, mas acessando o banco de dados diretamente em vez de invocar o Api Gateway. Depois de colocar o banco de dados sob carga, iniciei o mesmo experimento com a ferramenta hey conforme descrito acima e queria ver o que aconteceria. O mesmo insight foi gerado, mas desta vez com as seguintes métricas anômalas:
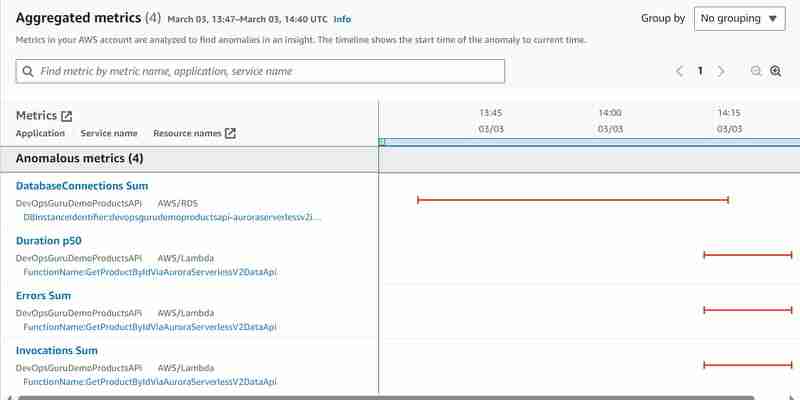 Agora vemos pelo menos uma métrica anômala de soma de conexão de banco de dados Aurora Serverless v2 adicional, mas as métricas DBLoad (CPU) ainda estão faltando.
Agora vemos pelo menos uma métrica anômala de soma de conexão de banco de dados Aurora Serverless v2 adicional, mas as métricas DBLoad (CPU) ainda estão faltando.
As anomalias gráficas têm esta aparência:
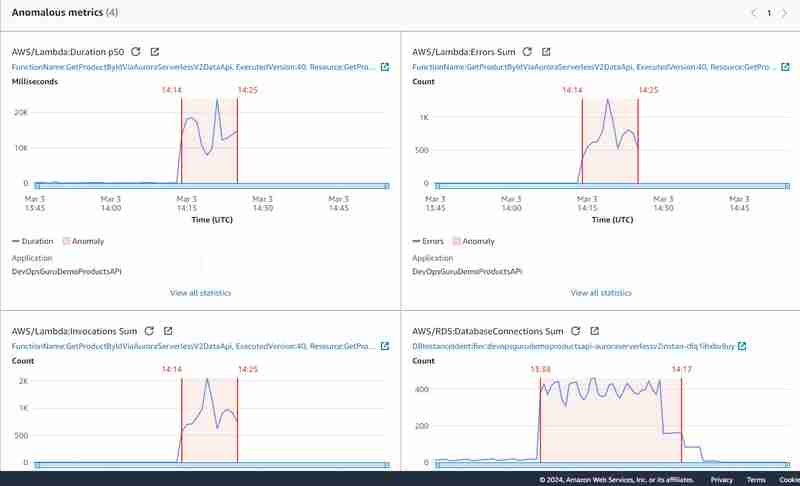 É claro que o experimento não foi limpo, pois fiz 2 testes de carga um após o outro e parcialmente em paralelo: o primeiro conectando-se ao banco de dados diretamente sem uso do API Gateway e o segundo usando Data API. Isso confirmou minha suposição inicial de que as métricas de soma de conexão do banco de dados são um critério muito importante para gerar insights do DevOps Guru para Aurora Serverless v2 (e para RDS em geral) e não são expostas em geral no caso de uso da API de dados.
É claro que o experimento não foi limpo, pois fiz 2 testes de carga um após o outro e parcialmente em paralelo: o primeiro conectando-se ao banco de dados diretamente sem uso do API Gateway e o segundo usando Data API. Isso confirmou minha suposição inicial de que as métricas de soma de conexão do banco de dados são um critério muito importante para gerar insights do DevOps Guru para Aurora Serverless v2 (e para RDS em geral) e não são expostas em geral no caso de uso da API de dados.
Conclusão
Neste artigo aprendi que o DevOps Guru pode detectar anomalias com sucesso com o banco de dados PostgreSQL Aurora (Serverless v2) no caso da função Lambda com tempo de execução gerenciado Java 21 conectado a ele via API de dados, mas só pode mostrar as métricas anômalas relacionadas à função Lambda sendo excedido porque o banco de dados não respondeu. A principal razão para isso parece ser que a conexão com o banco de dados como uma métrica do CloudWatch não é exposta (ou sempre exibida como 0) no caso de uso do Aurora Serverless v2 com API de dados. As métricas do banco de dados Aurora Serverless v2 (soma de conexões do banco de dados) só foram mostradas durante o segundo experimento artificial.
-
 Como combinar dois arrays associativos em PHP preservando IDs exclusivos e manipulando nomes duplicados?Combinando matrizes associativas em PHPEm PHP, combinar duas matrizes associativas em uma única matriz é uma tarefa comum. Considere a seguinte solici...Programação Publicado em 19/11/2024
Como combinar dois arrays associativos em PHP preservando IDs exclusivos e manipulando nomes duplicados?Combinando matrizes associativas em PHPEm PHP, combinar duas matrizes associativas em uma única matriz é uma tarefa comum. Considere a seguinte solici...Programação Publicado em 19/11/2024 -
Como corrigir “Configuração incorreta: Erro ao carregar o módulo MySQLdb” no Django no macOS?MySQL configurado incorretamente: o problema com caminhos relativosAo executar python manage.py runserver no Django, você pode encontrar o seguinte er...Programação Publicado em 19/11/2024
-
VariedadeMétodos são fns que podem ser chamados em objetos Arrays são objetos, portanto também possuem métodos em JS. slice(begin): extrai parte do arr...Programação Publicado em 19/11/2024
-
Posso dirigir? Codificando um testador de álcoolNa Dinamarca, onde moro, infelizmente detemos um recorde na Europa: nossos filhos são os que mais bebem álcool no continente. Por causa disso, há um f...Programação Publicado em 2024-11-18
-
Por que meu insert MySQL do Python não está funcionando?Python MySQL Insert Not FunctioningEm Python, utilizar a API MySQL para conectar-se a um banco de dados MySQL é uma abordagem popular. No entanto, pod...Programação Publicado em 2024-11-18
-
Usando WebSockets no Go para comunicação em tempo realCriar aplicativos que exigem atualizações em tempo real, como aplicativos de bate-papo, notificações ao vivo ou ferramentas colaborativas, requer um m...Programação Publicado em 2024-11-18
-
Corrigindo o erro “Não é possível usar a instrução de importação fora de um módulo”Como desenvolvedores de JavaScript e TypeScript, frequentemente encontramos erros inesperados ao trabalhar com diferentes sistemas de módulos. Um prob...Programação Publicado em 2024-11-18
-
Como se conectar a um contêiner Docker MySQL do Localhost?Conectando-se ao Docker MySQL Container a partir do LocalhostPara interagir com uma instância MySQL em execução em um contêiner Docker diretamente de ...Programação Publicado em 2024-11-18
-
Como definir relacionamentos de amizade em classes de modelo com diferentes argumentos de modelo?Aprofundando-se em modelos de classe com amigos de classe de modeloAo definir uma classe de árvore binária (BT) e sua classe de elemento (BE), é neces...Programação Publicado em 2024-11-18
-
Além das instruções `if`: onde mais um tipo com uma conversão `bool` explícita pode ser usado sem conversão?Conversão contextual para bool permitida sem conversãoSua classe define uma conversão explícita para bool, permitindo que você use sua instância '...Programação Publicado em 2024-11-18
-
## Construindo um back-end robusto de CMS: Como a estrutura OOP e MVC pode melhorar o gerenciamento de projetos?PHP OOP Core Framework: Implementando uma base sólida para um back-end CMSCompreender a programação orientada a objetos (OOP) é crucial ao desenvolv...Programação Publicado em 2024-11-18
-
Como std::string é implementado e como ele difere das strings de estilo C?Uma exploração da implementação de std::stringO enigmático std::string, um componente fundamental da biblioteca padrão C, gerou curiosidade sobre seu ...Programação Publicado em 2024-11-18
-
Por que (0 <5 <3) é avaliado como verdadeiro em JavaScript?O enigma comparativo do JavaScript: decifrando a verdade interior (0 < 5 < 3)No reino do JavaScript, surge uma observação peculiar: por que a expressã...Programação Publicado em 2024-11-18
-
Por que a solicitação POST não captura entrada em PHP apesar do código válido?Endereçando o mau funcionamento da solicitação POST em PHPNo trecho de código apresentado:action=''em vez de:action="<?php echo $_SERVER['PHP_...Programação Publicado em 2024-11-18
-
O que aconteceu com o deslocamento de coluna no Bootstrap 4 Beta?Bootstrap 4 Beta: A remoção e restauração do deslocamento de colunaBootstrap 4, em sua versão Beta 1, introduziu mudanças significativas na forma como...Programação Publicado em 2024-11-18















Estude chinês
- 1 Como se diz “andar” em chinês? 走路 Pronúncia chinesa, 走路 aprendizagem chinesa
- 2 Como se diz “pegar um avião” em chinês? 坐飞机 Pronúncia chinesa, 坐飞机 aprendizagem chinesa
- 3 Como se diz “pegar um trem” em chinês? 坐火车 Pronúncia chinesa, 坐火车 aprendizagem chinesa
- 4 Como se diz “pegar um ônibus” em chinês? 坐车 Pronúncia chinesa, 坐车 aprendizagem chinesa
- 5 Como se diz dirigir em chinês? 开车 Pronúncia chinesa, 开车 aprendizagem chinesa
- 6 Como se diz nadar em chinês? 游泳 Pronúncia chinesa, 游泳 aprendizagem chinesa
- 7 Como se diz andar de bicicleta em chinês? 骑自行车 Pronúncia chinesa, 骑自行车 aprendizagem chinesa
- 8 Como você diz olá em chinês? 你好Pronúncia chinesa, 你好Aprendizagem chinesa
- 9 Como você agradece em chinês? 谢谢Pronúncia chinesa, 谢谢Aprendizagem chinesa
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









