
Cogumelos Mágicos: explorando e tratando dados nulos com Mage
 Navegar:765
Navegar:765
Mage é uma poderosa ferramenta para tarefas de ETL, com features que possibilitando exploração e mineração de dados, visualizações rápidas através de templates de gráficos e diversas outras características que transformam seu trabalho com dados em algo magico.
No tratamento de dados, durante um processo de ETL é comum encontrarmos dados faltantes que podem gerar problemas no futuro, dependendo da atividade que vamos realizar com o dataset, os dados nulos podem atrapalhar bastante.
Para identificar a ausência de dados no nosso dataset, podemos utilizar Python e a biblioteca pandas para verificar os dados que apresentam valores nulos, além disso podemos montar gráficos que mostram com mais clareza ainda o impacto desses valores nulos em nosso dataset.
Nosso pipeline consiste de 4 passos: começando com a carga dos dados, duas etapas de tratamento e a exportação dos dados.
Data Loader
Nesse artigo vamos utilizar o dataset: Binary Prediction of Poisonous Mushrooms que esta disponível no Kaggle como parte de uma competição. Vamos uar o dataset de treino disponibilizado no site.
Vamos criar uma etapa de Data Loader usando python para poder carregar os dados que vamos usar. Antes deste passo criei uma tabela no banco de dados Postgres, que tenho localmente em minha maquina, para poder carregar os dados. Como os dados estão no Postgres, vamos usar o template de carga já definido do Postgres dentro do Mage.
from mage_ai.settings.repo import get_repo_path from mage_ai.io.config import ConfigFileLoader from mage_ai.io.postgres import Postgres from os import path if 'data_loader' not in globals(): from mage_ai.data_preparation.decorators import data_loader if 'test' not in globals(): from mage_ai.data_preparation.decorators import test @data_loader def load_data_from_postgres(*args, **kwargs): """ Template for loading data from a PostgreSQL database. Specify your configuration settings in 'io_config.yaml'. Docs: https://docs.mage.ai/design/data-loading#postgresql """ query = 'SELECT * FROM mushroom' # Specify your SQL query here config_path = path.join(get_repo_path(), 'io_config.yaml') config_profile = 'default' with Postgres.with_config(ConfigFileLoader(config_path, config_profile)) as loader: return loader.load(query) @test def test_output(output, *args) -> None: """ Template code for testing the output of the block. """ assert output is not None, 'The output is undefined'
Dentro da função load_data_from_postgres() vamos definir a query que vamos usar para carregar a tabela que está no banco. No meu caso configurei as informações do banco no arquivo io_config.yaml onde está definido como configuração default, por isso só precisamos passar o nome default para a variável config_profile.
Depois de executar o bloco, vamos usar a feature Add chart, que ira disponibilizar informações sobre os nosso dados através de templates já definidos. Basta clicar no icone de ao lado do botão play, sinalizado na imagem com a linha amarela.

Vamos selecionar duas opções para poder explorar mias o nosso dataset, as opções summay_overview e feature_profiles. Através do summary_overview, obtemos as informações sobre o número de colunas e e linhas do dataset, também podemos visualizar o total de colunas por tipo, por exemplo o total de colunas categóricas, numéricas e boleanas. Já o feature_profiles, apresentam informações mais descritivas sobre os dados, como por exemplo: tipo, valor mínimo, valor máximo, dentre outras informações, inclusive já podemos visualizar os valores faltantes, que são o foco do nosso tratamento.
Para podermos focar mais nos dados faltantes, vamos usar o template: % of missing values, um gráfico de barras com a porcentagem de dados que estão faltando, em cada uma das colunas.
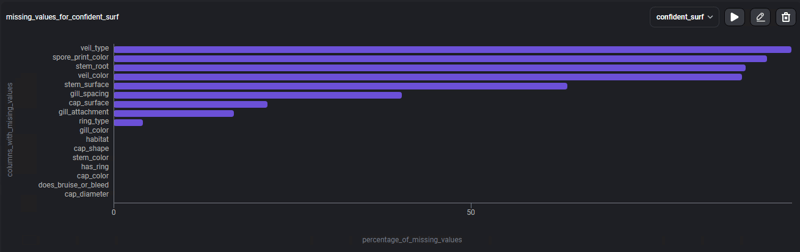
O gráfico apresenta 4 colunas onde os valores faltantes correspondem a mais de 80% de seu conteúdo, e outras colunas que apresentam valores faltantes mas em uma menor quantidade, essa informação já nós possibilita buscar diferentes estratégias para lidar com esses dados nulos.
Transformer Drop Columns
Para as colunas que possuem mais de 80% dos valores nulos, a estratégia que vamos seguir será a de realizar um drop colums no dataframe, selecionando as colunas que vamos excluir do dataframe. Usando o Bloco TRANSFORMER na linguagem Python, vamos selecionar a opção Colum removal .
from mage_ai.data_cleaner.transformer_actions.base import BaseAction from mage_ai.data_cleaner.transformer_actions.constants import ActionType, Axis from mage_ai.data_cleaner.transformer_actions.utils import build_transformer_action from pandas import DataFrame if 'transformer' not in globals(): from mage_ai.data_preparation.decorators import transformer if 'test' not in globals(): from mage_ai.data_preparation.decorators import test @transformer def execute_transformer_action(df: DataFrame, *args, **kwargs) -> DataFrame: """ Execute Transformer Action: ActionType.REMOVE Docs: https://docs.mage.ai/guides/transformer-blocks#remove-columns """ action = build_transformer_action( df, action_type=ActionType.REMOVE, arguments=['veil_type', 'spore_print_color', 'stem_root', 'veil_color'], axis=Axis.COLUMN, ) return BaseAction(action).execute(df) @test def test_output(output, *args) -> None: """ Template code for testing the output of the block. """ assert output is not None, 'The output is undefined'
Dentro da função execute_transformer_action() vamos inserir uma lista com o nome das colunas que queremos excluir do dataset, na variável arguments, depois deste passo, basta executar o bloco.
Transformer Fill in Missing Values
Agora para as colunas que possuem menos de 80% de valores nulos, vamos usar a estratégia Fill in Missing Values, pois em alguns casos a pesas de possuir dados faltantes a substituição destes por valores como média, ou moda, pode ser capas de suprir a necessidade dos dados sem causar muitas alterações ao dataset, dependendo de seu objetivo final.
Existem algumas tarefas, como a de classificação, onde a substituição dos dados faltantes por um valor que seja relevante (moda, média, mediana) para o dataset, possa contribuir com o algoritmo de classificação, que poderia chegar a outras conclusões caso o dados fossem apagados como na outra estratégia de utilizamos.
Para tomar uma decisão com relação a qual medida vamos utilizar, vamos recorrer novamente a funcionalidade Add chart do Mage. Usando o template Most frequent values podemos visualizar a moda e a frequência desse valor em cada uma das colunas.
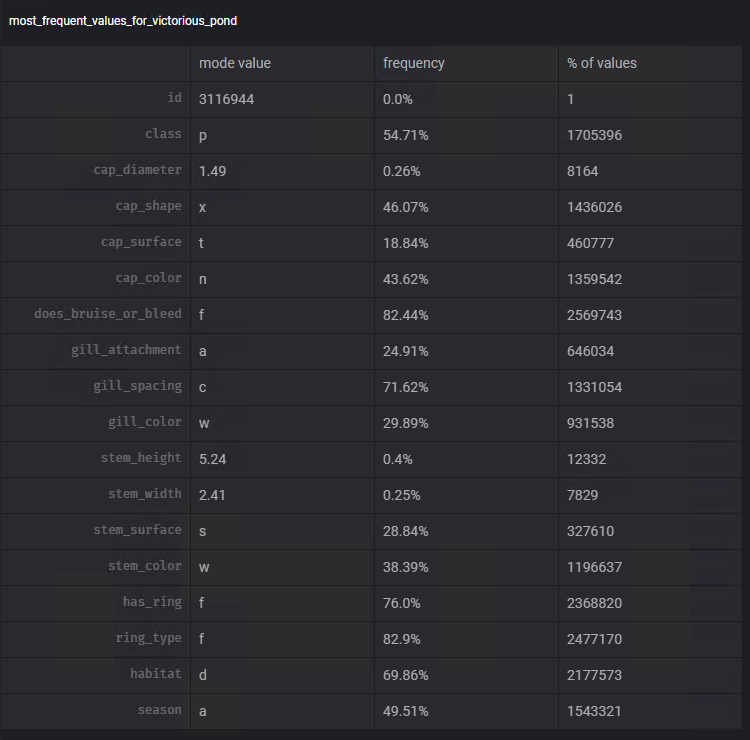
Seguindos passos semelhantes aos anteriores, vamos usar o tranformer Fill in missing values, para realizar a tarefa de subtiruir os dados faltantes usando a moda de cada uma das colunas: steam_surface, gill_spacing, cap_surface, gill_attachment, ring_type.
from mage_ai.data_cleaner.transformer_actions.constants import ImputationStrategy
from mage_ai.data_cleaner.transformer_actions.base import BaseAction
from mage_ai.data_cleaner.transformer_actions.constants import ActionType, Axis
from mage_ai.data_cleaner.transformer_actions.utils import build_transformer_action
from pandas import DataFrame
if 'transformer' not in globals():
from mage_ai.data_preparation.decorators import transformer
if 'test' not in globals():
from mage_ai.data_preparation.decorators import test
@transformer
def execute_transformer_action(df: DataFrame, *args, **kwargs) -> DataFrame:
"""
Execute Transformer Action: ActionType.IMPUTE
Docs: https://docs.mage.ai/guides/transformer-blocks#fill-in-missing-values
"""
action = build_transformer_action(
df,
action_type=ActionType.IMPUTE,
arguments=df.columns, # Specify columns to impute
axis=Axis.COLUMN,
options={'strategy': ImputationStrategy.MODE}, # Specify imputation strategy
)
return BaseAction(action).execute(df)
@test
def test_output(output, *args) -> None:
"""
Template code for testing the output of the block.
"""
assert output is not None, 'The output is undefined'
Na função execute_transformer_action() , definimos a estratégia para a substituição dos dados num dicionário do Python. Para mais opções de substituição, basta acessar a documentação do transformer: https://docs.mage.ai/guides/transformer-blocks#fill-in-missing-values.
Data Exporter
Ao realizar todas as transformações, vamos salvar nosso dataset agora tratado, na mesma base do Postgres mas agora com um nome diferente para podermos diferenciar. Usando o bloco Data Exporter e selecionando o Postgres, vamos definir o shema e a tabela onde queremos salvar, lembrando que as configurações do banco são salvas previamente no arquivo io_config.yaml.
from mage_ai.settings.repo import get_repo_path from mage_ai.io.config import ConfigFileLoader from mage_ai.io.postgres import Postgres from pandas import DataFrame from os import path if 'data_exporter' not in globals(): from mage_ai.data_preparation.decorators import data_exporter @data_exporter def export_data_to_postgres(df: DataFrame, **kwargs) -> None: """ Template for exporting data to a PostgreSQL database. Specify your configuration settings in 'io_config.yaml'. Docs: https://docs.mage.ai/design/data-loading#postgresql """ schema_name = 'public' # Specify the name of the schema to export data to table_name = 'mushroom_clean' # Specify the name of the table to export data to config_path = path.join(get_repo_path(), 'io_config.yaml') config_profile = 'default' with Postgres.with_config(ConfigFileLoader(config_path, config_profile)) as loader: loader.export( df, schema_name, table_name, index=False, # Specifies whether to include index in exported table if_exists='replace', #Specify resolution policy if table name already exists )
Obrigado e até a próxima ?
repo -> https://github.com/DeadPunnk/Mushrooms/tree/main
-
 Sistema de leilão on-line da semana HacktoberfestVisão geral Durante a semana 3 do Hacktoberfest, decidi contribuir para um projeto menor, mas promissor: um sistema de leilão online. Embora ...Programação Publicado em 2024-11-06
Sistema de leilão on-line da semana HacktoberfestVisão geral Durante a semana 3 do Hacktoberfest, decidi contribuir para um projeto menor, mas promissor: um sistema de leilão online. Embora ...Programação Publicado em 2024-11-06 -
Como você propaga exceções entre threads em C++ usando `exception_ptr`?Propagando exceções entre threads em C A tarefa de propagar exceções entre threads em C surge quando uma função chamada de um thread principal gera vá...Programação Publicado em 2024-11-06
-
Como consertar bordas irregulares no Firefox com transformações CSS 3D?Bordas irregulares no Firefox com transformações CSS 3DSemelhante ao problema de bordas irregulares no Chrome com transformações CSS, o Firefox também...Programação Publicado em 2024-11-06
-
Por que a função mail() do PHP apresenta desafios para entrega de e-mail?Por que a função mail() do PHP é insuficiente: limitações e armadilhasEmbora o PHP forneça a função mail() para envio de e-mails, ela falha curto em c...Programação Publicado em 2024-11-06
-
Simplifique suas conversões de arquivo NumPy com npyConverterSe você trabalha com arquivos .npy do NumPy e precisa convertê-los para os formatos .mat (MATLAB) ou .csv, npyConverter é a ferramenta para você! Esta...Programação Publicado em 2024-11-06
-
Como desabilitar regras Eslint para uma linha específica?Desativação de regra Eslint para uma linha específicaNo JSHint, as regras de linting podem ser desabilitadas para uma linha específica usando a sintax...Programação Publicado em 2024-11-06
-
Como inserir listas em células DataFrame do Pandas sem erros?Inserindo listas em células do PandasProblemaEm Python, tentar inserir uma lista em uma célula de um DataFrame do Pandas pode resultar em erros ou res...Programação Publicado em 2024-11-06
-
Quais são as principais diferenças entre `plt.plot`, `ax.plot` e `figure.add_subplot` no Matplotlib?Diferenças entre gráfico, eixos e figura no MatplotlibMatplotlib é uma biblioteca Python orientada a objetos para a criação de visualizações. Ele usa ...Programação Publicado em 2024-11-06
-
FireDucks: Obtenha desempenho além dos pandas com custo zero de aprendizado!Pandas é uma das bibliotecas mais populares, quando eu procurava uma maneira mais fácil de acelerar seu desempenho, descobri o FireDucks e me interess...Programação Publicado em 2024-11-06
-
Grade CSS: layouts de grade aninhadosIntrodução CSS Grid é um sistema de layout que rapidamente ganhou popularidade entre os desenvolvedores web por sua flexibilidade e eficiênci...Programação Publicado em 2024-11-06
-
Caderno Jupyter para JavaO poderoso do Jupyter Notebook Jupyter Notebooks são uma excelente ferramenta, originalmente desenvolvida para ajudar cientistas e engenheiro...Programação Publicado em 2024-11-06
-
Como compartilhar dados entre a janela principal e threads no PyQt: referência direta versus sinais e slots?Compartilhando dados entre a janela principal e o thread no PyQtAplicativos multithread geralmente precisam compartilhar dados entre o thread da janel...Programação Publicado em 2024-11-06
-
Atalhos de código VS mais úteis para desenvolvedores profissionais ?20 atalhos mais úteis no VS Code Navegação Geral Paleta de comandos: acesse todos os comandos disponíveis no VS Code. Ctrl Shift P (Windows/Linux) OU...Programação Publicado em 2024-11-06
-
Vamos criar uma entrada numérica melhor com ReactProgramação Publicado em 2024-11-06
-
Quando usar `composer update` vs. `composer install`?Explorando as diferenças entre a atualização do compositor e a instalação do compositorO Composer, um gerenciador de dependências PHP popular, oferece...Programação Publicado em 2024-11-06















Estude chinês
- 1 Como se diz “andar” em chinês? 走路 Pronúncia chinesa, 走路 aprendizagem chinesa
- 2 Como se diz “pegar um avião” em chinês? 坐飞机 Pronúncia chinesa, 坐飞机 aprendizagem chinesa
- 3 Como se diz “pegar um trem” em chinês? 坐火车 Pronúncia chinesa, 坐火车 aprendizagem chinesa
- 4 Como se diz “pegar um ônibus” em chinês? 坐车 Pronúncia chinesa, 坐车 aprendizagem chinesa
- 5 Como se diz dirigir em chinês? 开车 Pronúncia chinesa, 开车 aprendizagem chinesa
- 6 Como se diz nadar em chinês? 游泳 Pronúncia chinesa, 游泳 aprendizagem chinesa
- 7 Como se diz andar de bicicleta em chinês? 骑自行车 Pronúncia chinesa, 骑自行车 aprendizagem chinesa
- 8 Como você diz olá em chinês? 你好Pronúncia chinesa, 你好Aprendizagem chinesa
- 9 Como você agradece em chinês? 谢谢Pronúncia chinesa, 谢谢Aprendizagem chinesa
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









