 Primeira página > Programação > FireDucks: Obtenha desempenho além dos pandas com custo zero de aprendizado!
Primeira página > Programação > FireDucks: Obtenha desempenho além dos pandas com custo zero de aprendizado!
FireDucks: Obtenha desempenho além dos pandas com custo zero de aprendizado!
 Navegar:447
Navegar:447
Pandas é uma das bibliotecas mais populares, quando eu procurava uma maneira mais fácil de acelerar seu desempenho, descobri o FireDucks e me interessei por ele!
Comparação com pandas: Por que FireDucks?
Um programa Pandas pode encontrar um sério problema de desempenho dependendo de como foi escrito. No entanto, sendo um cientista de dados, quero gastar cada vez mais tempo analisando dados em vez de melhorar o desempenho do meu código. Então, seria ótimo se pudesse fazer algo como trocar a ordem dos processos e acelerar o desempenho do programa automaticamente. Por exemplo, Processo A =>Processo B será mais lento, então iremos substituí-lo como Processo B =>Processo A. (Claro, o resultado com certeza será o mesmo.) Diz-se que os cientistas de dados gastam cerca de 45% de seu tempo preparando os dados, e quando estava pensando em fazer algo para acelerar o processo, me deparei com um módulo chamado FireDucks.
Na documentação do FireDucks, parece ser compatível apenas com plataformas Linux. Como uso Windows na minha máquina principal, gostaria de experimentá-lo no WSL2 (Windows Subsystem for Linux), um ambiente que pode rodar Linux no Windows.
O ambiente que experimentei é o seguinte.
- SO Microsoft Windows 11 Pro
- Versão 10.0.22631 Compilação 22631
- Modelo de sistema Z690 Pro RS
- Tipo de sistema baseado em x64
- Processador para PC Intel(R) Core(TM) i3–12100 de 12ª geração, 3300 MHz, 4 núcleos, 8 processadores lógicos
- Produto de rodapé Z690 Pro RS
- Função da plataforma Desktop
- Memória física instalada (RAM)64,0 GB
Instalando e configurando FireDucks
Instale WSL
WSL foi instalado com a ajuda da seguinte documentação da Microsoft; a distribuição Linux é Ubuntu 22.04.1 LTS.
Instale FireDucks
Em seguida, instale o FireDucks. No entanto, é muito fácil de instalar.
pip instalar fireducks
A instalação do FireDucks levará alguns minutos (junto com pyarrow, pandas e outras bibliotecas).
Tentei executar o código abaixo, a velocidade de carregamento foi tão rápida que o pandas demorou 4 segundos e o fireDucks demorou apenas 74,5 ns.
# 1. analysis based on time period and creative duration # convert timestamp to date/time object df['timestamp_converted'] = pd.to_datetime(df['timestamp'], unit='s ') # define time period def get_part_of_day(hour): if 5Todo o pré-processamento e análise de dados levou cerca de 8 segundos no pandas, enquanto poderia ser concluído em 4 segundos ao usar o FireDucks. Quase 2 vezes mais rápido pode ser alcançado.
Desempenho aprimorado
Uma das coisas mais estressantes sobre o uso do pandas é esperar ao carregar grandes conjuntos de dados, e então tenho que esperar por operações complexas como groupby. Por outro lado, como o FireDucks faz avaliação lenta, o carregamento em si não leva tempo algum, então o processamento é feito onde é necessário, e achei que foi muito significativo com uma grande redução no tempo total de espera.
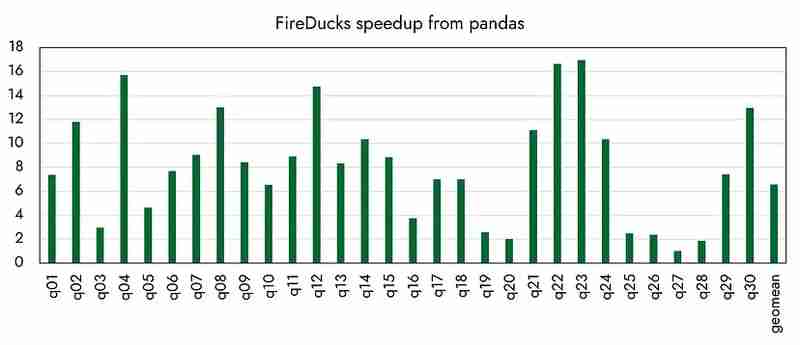
Quanto a outros desempenhos, parece que foi alcançado até 16 vezes mais rápido em comparação com os pandas, conforme anunciado oficialmente pela organização. (Vou comparar o desempenho com várias bibliotecas concorrentes na próxima vez.)
custo zero de aprendizagem
A capacidade de seguir a notação exata do pandas sem ter que pensar em nada é uma grande vantagem. Além do FireDucks, existem outras bibliotecas de aceleração de quadros de dados, mas elas são muito caras para aprender e fáceis de esquecer.
Por exemplo, se você deseja adicionar colunas com polares, você deve escrever algo assim.
# pandas df["new_col"] = df["A"] 1 # polars df = df.with_columns((pl.col("A") 1).alias("new_col"))Quase não há necessidade de alterar um código existente
Tenho vários ETLs e outros projetos que usam pandas, e seria bom ver uma melhoria de desempenho apenas instalando e substituindo a instrução import por FireDucks.
Se você quiser adicionar mais, sinta-se à vontade para comentar abaixo.
-
 Como converter com eficiência fusos horários em PHP?Conversão eficiente do fuso horário em php No PHP, o manuseio dos fusos horários pode ser uma tarefa direta. Este guia fornecerá um método fácil...Programação Postado em 2025-07-13
Como converter com eficiência fusos horários em PHP?Conversão eficiente do fuso horário em php No PHP, o manuseio dos fusos horários pode ser uma tarefa direta. Este guia fornecerá um método fácil...Programação Postado em 2025-07-13 -
Implementação dinâmica reflexiva da interface GO para exploração de método RPCreflexão para a implementação da interface dinâmica em go A reflexão em Go é uma ferramenta poderosa que permite a inspeção e manipulação do c...Programação Postado em 2025-07-13
-
Como exibir corretamente a data e a hora atuais em formato "dd/mm/yyyy hh: mm: ss.ss" em java?como exibir a data e a hora atuais em "dd/mm/yyyy hh: mm: ss.ss" formato no código java fornecido, o problema com a exibição da data...Programação Postado em 2025-07-13
-
Por que as expressões lambda exigem variáveis "final" ou "final válida" em Java?expressões lambda requerem "final" ou "efetivamente" variáveis a mensagem de erro "BEATILE Utilizada na expressão lam...Programação Postado em 2025-07-13
-
Como posso unindo tabelas de banco de dados com diferentes números de colunas?tabelas combinadas com diferentes colunas ] pode encontrar desafios ao tentar mesclar tabelas de banco de dados com colunas diferentes. Uma man...Programação Postado em 2025-07-13
-
Por que o Firefox exibe imagens usando a propriedade CSS `Content`?exibindo imagens com URL de conteúdo em Firefox Um problema foi encontrado onde certos navegadores, especificamente Firefox, falham em exibir ...Programação Postado em 2025-07-13
-
Como corrigir “Erro geral: o servidor MySQL 2006 desapareceu” ao inserir dados?Como resolver "Erro geral: o servidor MySQL de 2006 desapareceu" ao inserir registrosIntrodução:A inserção de dados em um banco de dados MyS...Programação Postado em 2025-07-13
-
Como resolver o erro \ "Uso inválido da função do grupo \" no MySQL ao encontrar a contagem máxima?como recuperar a contagem máxima usando o mysql em mysql, você pode encontrar um problema enquanto tenta encontrar a contagem máxima de valore...Programação Postado em 2025-07-13
-
Quando um aplicativo Go Go fecha a conexão do banco de dados?Gerenciando conexões de banco de dados em Applications Go Web em aplicativos simples Go Web que utilizam bancos de dados como PostGresql, o mome...Programação Postado em 2025-07-13
-
Por que o DateTime :: Modify do PHP ('+1 mês') produz resultados inesperados?Modificando meses com php dateTime: descobrindo o comportamento pretendido Ao trabalhar com a classe DateTime do PHP, adicionar ou subtrair me...Programação Postado em 2025-07-13
-
Como posso gerar com eficiência as lesmas amigáveis ao URL a partir de strings unicode no PHP?criando uma função para geração de lesmas eficientes criando lesmas, representações simplificadas de strings unicode usadas nos URLs, podem se...Programação Postado em 2025-07-13
-
Razões para o Codeigniter se conectar ao banco de dados MySQL depois de mudar para MySqliUnable to Connect to MySQL Database: Troubleshooting Error MessageWhen attempting to switch from the MySQL driver to the MySQLi driver in CodeIgniter,...Programação Postado em 2025-07-13
-
Como ignorar os blocos de sites com os pedidos da Python e os agentes de usuários falsos?como simular o comportamento do navegador com as solicitações de Python e os agentes de usuário falsos Python's Solicts Library é uma ferr...Programação Postado em 2025-07-13
-
O erro do compilador "usr/bin/ld: não pode encontrar -l" soluçãoErro encontrado: "usr/bin/ld: não é possível encontrar -l " Ao tentar compilar um programa, você pode encontrar a seguinte mensagem ...Programação Postado em 2025-07-13
-
Futuro do PHP: adaptação e inovaçãoO futuro do PHP será alcançado adaptando -se a novas tendências de tecnologia e introduzindo recursos inovadores: 1) adaptação à computação em nuvem,...Programação Postado em 2025-07-13















Estude chinês
- 1 Como se diz “andar” em chinês? 走路 Pronúncia chinesa, 走路 aprendizagem chinesa
- 2 Como se diz “pegar um avião” em chinês? 坐飞机 Pronúncia chinesa, 坐飞机 aprendizagem chinesa
- 3 Como se diz “pegar um trem” em chinês? 坐火车 Pronúncia chinesa, 坐火车 aprendizagem chinesa
- 4 Como se diz “pegar um ônibus” em chinês? 坐车 Pronúncia chinesa, 坐车 aprendizagem chinesa
- 5 Como se diz dirigir em chinês? 开车 Pronúncia chinesa, 开车 aprendizagem chinesa
- 6 Como se diz nadar em chinês? 游泳 Pronúncia chinesa, 游泳 aprendizagem chinesa
- 7 Como se diz andar de bicicleta em chinês? 骑自行车 Pronúncia chinesa, 骑自行车 aprendizagem chinesa
- 8 Como você diz olá em chinês? 你好Pronúncia chinesa, 你好Aprendizagem chinesa
- 9 Como você agradece em chinês? 谢谢Pronúncia chinesa, 谢谢Aprendizagem chinesa
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









