
Snowflake(SiS)のStreamlitを使ったトークン数チェックアプリを作ってみた
 ブラウズ:171
ブラウズ:171
導入
こんにちは、私は Snowflake のセールス エンジニアです。さまざまな投稿を通じて、私の経験や実験の一部を皆さんと共有したいと思います。この記事では、Snowflake で Streamlit を使用してトークン数を確認し、Cortex LLM のコストを見積もるアプリを作成する方法を説明します。
注: この投稿は私の個人的な見解を表すものであり、Snowflake の見解ではありません。
Snowflake (SiS) の Streamlit とは何ですか?
Streamlit は、HTML/CSS/JavaScript を必要とせずに、単純な Python コードで Web UI を作成できる Python ライブラリです。アプリ ギャラリーで例をご覧ください。
Snowflake の Streamlit を使用すると、Snowflake 上で Streamlit Web アプリを直接開発して実行できます。 Snowflake アカウントだけで簡単に使用でき、Snowflake テーブル データを Web アプリに統合するのに最適です。
Snowflake の Streamlit について (Snowflake 公式ドキュメント)
スノーフレーク コーテックスとは何ですか?
Snowflake Cortex は、Snowflake の生成 AI 機能のスイートです。 Cortex LLM を使用すると、SQL または Python の単純な関数を使用して、Snowflake 上で実行されている大規模な言語モデルを呼び出すことができます。
大規模言語モデル (LLM) 関数 (Snowflake Cortex) (Snowflake 公式ドキュメント)
機能の概要
画像
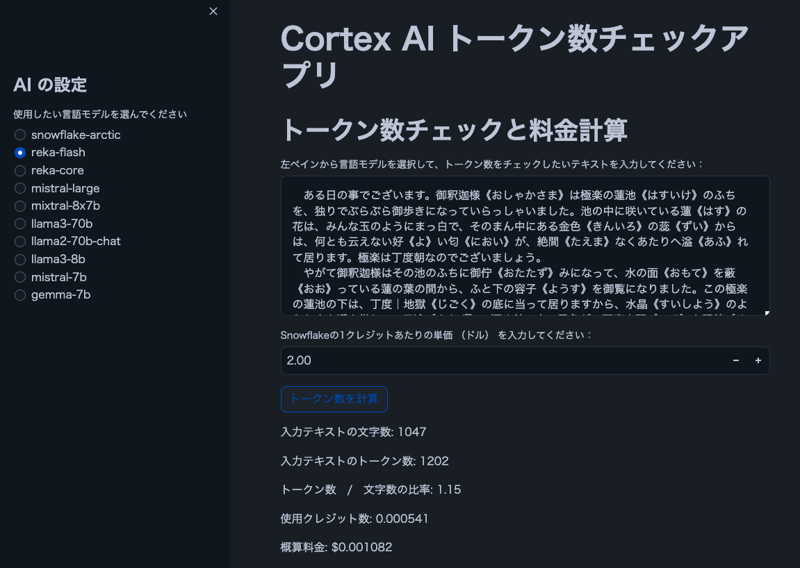
注: 画像内のテキストは、芥川龍之介の「蜘蛛の糸」からのものです。
特徴
- ユーザーは Cortex LLM モデルを選択できます
- ユーザー入力テキストの表示文字数とトークン数
- 文字に対するトークンの比率を表示します
- Snowflake クレジット価格に基づいて推定コストを計算します
注: Cortex LLM 価格表 (PDF)
前提条件
- Cortex LLM アクセス権を持つ Snowflake アカウント
- snowflake-ml-python 1.1.2 以降
注: Cortex LLM リージョンの可用性 (公式 Snowflake ドキュメント)
ソースコード
import streamlit as st
from snowflake.snowpark.context import get_active_session
import snowflake.snowpark.functions as F
# Get current session
session = get_active_session()
# Application title
st.title("Cortex AI Token Count Checker")
# AI settings
st.sidebar.title("AI Settings")
lang_model = st.sidebar.radio("Select the language model you want to use",
("snowflake-arctic", "reka-core", "reka-flash",
"mistral-large2", "mistral-large", "mixtral-8x7b", "mistral-7b",
"llama3.1-405b", "llama3.1-70b", "llama3.1-8b",
"llama3-70b", "llama3-8b", "llama2-70b-chat",
"jamba-instruct", "gemma-7b")
)
# Function to count tokens (using Cortex's token counting function)
def count_tokens(model, text):
result = session.sql(f"SELECT SNOWFLAKE.CORTEX.COUNT_TOKENS('{model}', '{text}') as token_count").collect()
return result[0]['TOKEN_COUNT']
# Token count check and cost calculation
st.header("Token Count Check and Cost Calculation")
input_text = st.text_area("Select a language model from the left pane and enter the text you want to check for token count:", height=200)
# Let user input the price per credit
credit_price = st.number_input("Enter the price per Snowflake credit (in dollars):", min_value=0.0, value=2.0, step=0.01)
# Credits per 1M tokens for each model (as of 2024/8/30, mistral-large2 is not supported)
model_credits = {
"snowflake-arctic": 0.84,
"reka-core": 5.5,
"reka-flash": 0.45,
"mistral-large2": 1.95,
"mistral-large": 5.1,
"mixtral-8x7b": 0.22,
"mistral-7b": 0.12,
"llama3.1-405b": 3,
"llama3.1-70b": 1.21,
"llama3.1-8b": 0.19,
"llama3-70b": 1.21,
"llama3-8b": 0.19,
"llama2-70b-chat": 0.45,
"jamba-instruct": 0.83,
"gemma-7b": 0.12
}
if st.button("Calculate Token Count"):
if input_text:
# Calculate character count
char_count = len(input_text)
st.write(f"Character count of input text: {char_count}")
if lang_model in model_credits:
# Calculate token count
token_count = count_tokens(lang_model, input_text)
st.write(f"Token count of input text: {token_count}")
# Ratio of tokens to characters
ratio = token_count / char_count if char_count > 0 else 0
st.write(f"Token count / Character count ratio: {ratio:.2f}")
# Cost calculation
credits_used = (token_count / 1000000) * model_credits[lang_model]
cost = credits_used * credit_price
st.write(f"Credits used: {credits_used:.6f}")
st.write(f"Estimated cost: ${cost:.6f}")
else:
st.warning("The selected model is not supported by Snowflake's token counting feature.")
else:
st.warning("Please enter some text.")
結論
このアプリを使用すると、特に文字数とトークン数の間にギャップがある日本語のような言語を扱う場合に、LLM ワークロードのコストを簡単に見積もることができます。お役に立てば幸いです!
お知らせ
Snowflake X の最新情報
X に関する Snowflake の新着情報を共有しています。ご興味がございましたら、お気軽にフォローしてください。
英語版
Snowflake 新着情報ボット (英語版)
https://x.com/snow_new_ja
日本語版
Snowflake 新着情報ボット (日本語版)
https://x.com/snow_new_jp
変更履歴
(20240914) 最初の投稿
日本語オリジナル記事
https://zenn.dev/tsubasa_tech/articles/4dd80c91508ec4
-
 Microsoft Visual C ++が2フェーズテンプレートのインスタンス化を正しく実装できないのはなぜですか?Microsoft Visual Cの「壊れた」2フェーズテンプレートのインスタンス化の謎 問題声明: ユーザーは、Microsoft Visual C(MSVC)の懸念を表現する一般的な懸念を表明します。メカニズムの特定の側面は、予想どおりに動作できませんか?ただし、このチェックがテンプ...プログラミング 2025-03-12に投稿されました
Microsoft Visual C ++が2フェーズテンプレートのインスタンス化を正しく実装できないのはなぜですか?Microsoft Visual Cの「壊れた」2フェーズテンプレートのインスタンス化の謎 問題声明: ユーザーは、Microsoft Visual C(MSVC)の懸念を表現する一般的な懸念を表明します。メカニズムの特定の側面は、予想どおりに動作できませんか?ただし、このチェックがテンプ...プログラミング 2025-03-12に投稿されました -
UTF-8対ラテン-1:キャラクターエンコードの秘密!utf-8およびlatin1 を識別するとき、2つの顕著な選択肢が出現します:UTF-8とラテン語。彼らのアプリケーションの中で、基本的な疑問が生じます:どの識別特性がこれらの2つのエンコーディングを区別しますか? Latin1は特にラテン語のキャラクターに対応していますが、UTF-8...プログラミング 2025-03-12に投稿されました
-
Java文字列に複数のサブストリングを効率的に交換するにはどうすればよいですか?java で複数のサブストリングを弦の複数のサブストリングを置き換えると、文字列内の複数のサブストリングを置き換える必要性に直面すると、弦楽列の方法を繰り返し担当するブルートのアプローチに頼ることに魅力的です。ただし、これは大きな文字列や多数の文字列を使用する場合は非効率的です。正規表...プログラミング 2025-03-12に投稿されました
-
パートSQLインジェクションシリーズ:高度なSQL注入技術の詳細な説明著者:trix cyrus WayMap Pentestingツール:ここをクリック TrixSec Github:ここをクリック TrixSec Telegram:ここをクリックしてください 高度なSQLインジェクションエクスプロイト - パート7:最先端のテクニック...プログラミング 2025-03-12に投稿されました
-
データ挿入時の「一般エラー: 2006 MySQL サーバーが消えました」を修正するにはどうすればよいですか?レコードの挿入中に「一般エラー: 2006 MySQL サーバーが消えました」を解決する方法はじめに:MySQL データベースにデータを挿入すると、「一般エラー: 2006 MySQL サーバーが消えました。」というエラーが発生することがあります。このエラーは、通常、MySQL 構成内の 2 つの変...プログラミング 2025-03-12に投稿されました
-
悪意のあるコンテンツに対してファイルアップロードを保護するにはどうすればよいですか?ファイルアップロードに関するセキュリティの懸念 ファイルをサーバーにアップロードすると、ユーザーが提供する可能性のある悪意のあるコンテンツのために重要なセキュリティリスクを導入できます。これらの脅威を理解し、効果的な緩和戦略を実装することは、アプリケーションのセキュリティを維持するために重...プログラミング 2025-03-12に投稿されました
-
JavaScriptの正規表現を使用して、文字列からラインブレークを取り外す方法は?文字列からの行の破損を削除します このコードシナリオでは、目標は.value属性を使用してTextareaから読み取られたテキスト文字列から行の破損を排除することです。疑問が生じます:.replaceメソッド内の正規表現でラインブレークをどのように表現できますか? Windowsは「\ r \...プログラミング 2025-03-12に投稿されました
-
Firefoxバックボタンを使用すると、JavaScriptの実行が停止するのはなぜですか?navigational Historyの問題:JavaScriptは、Firefoxバックボタンを使用した後に実行を停止します ユーザーは、JavaScriptスクリプトが以前の訪問ページを介して回復したときに実行されない問題に遭遇する可能性があります。この問題は、ChromeやInt...プログラミング 2025-03-12に投稿されました
-
PHPを使用してBlob(画像)をMySQLに適切に挿入する方法は?php mysqlデータベースを持つmysqlデータベースにブロブを挿入すると、mysqlデータベースに画像を保存しようとすると、遭遇するかもしれません問題。このガイドは、画像データを正常に保存するためのソリューションを提供します。 ImageId、image) values( &...プログラミング 2025-03-12に投稿されました
-
McRyptからOpenSSLに暗号化を移行し、OpenSSLを使用してMcRyptで暗号化されたデータを復号化できますか?暗号化ライブラリをMcRyptからOpenSSL にアップグレードして、暗号化ライブラリをMcRyptからOpenSLにアップグレードできますか? OpenSSLでは、McRyptで暗号化されたデータを復号化することは可能ですか? 2つの異なる投稿は矛盾する情報を提供します。もしそうなら...プログラミング 2025-03-12に投稿されました
-
Javaのコレクショントラバーサルのために、for-for-eachループとイテレーターを使用することにパフォーマンスの違いはありますか?vs. Iterator:コレクショントラバーサルの効率この記事では、これら2つのアプローチの効率の違いを調査します。内部的にiteratorを使用します: list a = new ArrayList (); for(整数整数:a){ integer.toString(); } ...プログラミング 2025-03-12に投稿されました
-
オブジェクトがPythonに特定の属性を持っているかどうかを確認する方法は?メソッドオブジェクト属性の存在を決定するメソッド この問い合わせは、オブジェクト内の特定の属性の存在を検証する方法を求めています。未定義のプロパティにアクセスしようとする試みがエラーを提起する次の例を考えてみましょう: >>> a = SomeClass() >&g...プログラミング 2025-03-12に投稿されました
-
Java Hashset/LinkedHashsetランダム要素取得方法の詳細な説明セット のランダムな要素を見つけると、セットなどのコレクションからランダム要素を選択すると便利です。 Javaは、HashsetやLinkedhashsetを含む複数のタイプのセットを提供します。この記事では、これらの特定のセット実装からランダムな要素を選択する方法について説明します。 Lin...プログラミング 2025-03-12に投稿されました
-
CSSはいつユニットなしでピクセル(PX)に属性を与えますか?ユニットのないCSS属性のフォールバック:ケーススタディ css属性は、しばしば単位(例えば、px、em、%)を必要とします。ただし、特定のシナリオでは、これらのユニットが省略される場合があります。これは、そのような状況におけるフォールバックメカニズムとユーザーエージェント(UAS)の動作...プログラミング 2025-03-12に投稿されました















中国語を勉強する
- 1 「歩く」は中国語で何と言いますか? 走路 中国語の発音、走路 中国語学習
- 2 「飛行機に乗る」は中国語で何と言いますか? 坐飞机 中国語の発音、坐飞机 中国語学習
- 3 「電車に乗る」は中国語で何と言いますか? 坐火车 中国語の発音、坐火车 中国語学習
- 4 「バスに乗る」は中国語で何と言いますか? 坐车 中国語の発音、坐车 中国語学習
- 5 中国語でドライブは何と言うでしょう? 开车 中国語の発音、开车 中国語学習
- 6 水泳は中国語で何と言うでしょう? 游泳 中国語の発音、游泳 中国語学習
- 7 中国語で自転車に乗るってなんて言うの? 骑自行车 中国語の発音、骑自行车 中国語学習
- 8 中国語で挨拶はなんて言うの? 你好中国語の発音、你好中国語学習
- 9 中国語でありがとうってなんて言うの? 谢谢中国語の発音、谢谢中国語学習
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









