
Web スクレイピングの最適化: JSDOM を使用した認証データのスクレイピング
 ブラウズ:169
ブラウズ:169
スクレイピング開発者として、タスクを実行するために一時キーなどの認証データを抽出する必要がある場合があります。しかし、それはそれほど単純ではありません。通常、これは HTML または XHR ネットワーク リクエスト内にありますが、認証データが計算される場合もあります。その場合、スクリプトの難読化を解除するのに多くの時間がかかる計算をリバースエンジニアリングするか、計算を行う JavaScript を実行することができます。通常ブラウザを使用しますが、それは高価です。 Crawlee は、ブラウザ スクレイパーと Cheerio Scraper を並行して実行するためのサポートを提供しますが、これはコンピューティング リソースの使用量の点で非常に複雑で高価です。 JSDOM は、ブラウザより少ないリソースで、Cheerio よりわずかに高いリソースでページ JavaScript を実行するのに役立ちます。
この記事では、実際にブラウザを実行せず、代わりに JSDOM を使用して、ブラウザ Web アプリケーションによって生成された TikTok 広告クリエイティブ センターから認証データを取得するために、アクターの 1 つで使用する新しいアプローチについて説明します。
ウェブサイトを分析する
この URL にアクセスすると:
https://ads.tiktok.com/business/creativecenter/inspire/popular/hashtag/pc/en
ライブランキング、投稿数、トレンドチャート、作成者、分析を含むハッシュタグのリストが表示されます。また、業界をフィルターしたり、期間を設定したり、チェック ボックスを使用してトレンドがトップ 100 に新しいものであるかどうかをフィルターしたりできることにも注目してください。
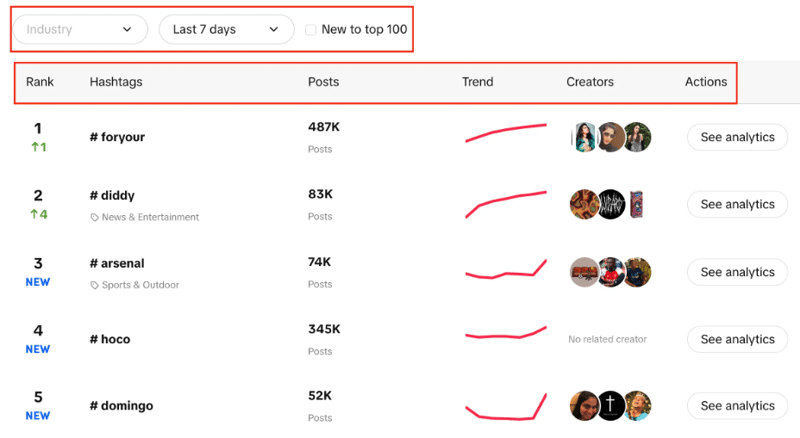
ここでの目標は、指定されたフィルターを使用してリストから上位 100 個のハッシュタグを抽出することです。
考えられるアプローチは 2 つあり、CheerioCrawler を使用するもので、2 つ目はブラウザベースのスクレイピングです。 Cheerio は結果をより速く表示しますが、JavaScript でレンダリングされた Web サイトでは機能しません。
クリエイティブ センターは Web アプリケーションであり、データ ソースは API であるため、ここでは Cheerio は最良の選択肢ではありません。そのため、HTML 構造に最初に存在するハッシュタグのみを取得できますが、必要な 100 個のハッシュタグをそれぞれ取得することはできません。
2 番目のアプローチは、Puppeteer、Playwright などのライブラリを使用してブラウザベースのスクレイピングを実行し、自動化を使用してすべてのハッシュタグをスクレイピングする方法ですが、以前の経験では、このような小さなタスクには多くの時間がかかります。
このプロセスをブラウザ ベースよりもはるかに優れ、CheerioCrawler ベースのクロールに非常に近づけるために開発した新しいアプローチが登場します。
JSDOMのアプローチ
このアプローチについて詳しく説明する前に、このアプローチの開発について、Apify の Web オートメーション エンジニアである Alexey Udovydchenko の功績を認めたいと思います。彼に敬意を表します!
このアプローチでは、https://ads.tiktok.com/creative_radar_api/v1/popular_trend/hashtag/list への API 呼び出しを行って、必要なデータを取得します。
この API を呼び出す前に、必要なヘッダー (認証データ) がいくつか必要になるため、最初に https://ads.tiktok.com/business/creativecenter/inspire/popular/hashtag/pad を呼び出します。 /en.
このアプローチは、API 呼び出しの URL を作成し、呼び出しを行ってデータを取得する関数を作成することから始めます。
export const createStartUrls = (input) => {
const {
days = '7',
country = '',
resultsLimit = 100,
industry = '',
isNewToTop100,
} = input;
const filterBy = isNewToTop100 ? 'new_on_board' : '';
return [
{
url: `https://ads.tiktok.com/creative_radar_api/v1/popular_trend/hashtag/list?page=1&limit=50&period=${days}&country_code=${country}&filter_by=${filterBy}&sort_by=popular&industry_id=${industry}`,
headers: {
// required headers
},
userData: { resultsLimit },
},
];
};
上記の関数では、前に説明したさまざまなパラメーターを含む API 呼び出しの開始 URL を作成します。パラメータに従って URL を作成した後、creative_radar_api を呼び出し、すべての結果を取得します。
しかし、ヘッダーを取得するまでは機能しません。そこで、まず sessionPool と proxyConfiguration.
を使用してセッションを作成する関数を作成しましょう。
export const createSessionFunction = async (
sessionPool,
proxyConfiguration,
) => {
const proxyUrl = await proxyConfiguration.newUrl(Math.random().toString());
const url =
'https://ads.tiktok.com/business/creativecenter/inspiration/popular/hashtag/pad/en';
// need url with data to generate token
const response = await gotScraping({ url, proxyUrl });
const headers = await getApiUrlWithVerificationToken(
response.body.toString(),
url,
);
if (!headers) {
throw new Error(`Token generation blocked`);
}
log.info(`Generated API verification headers`, Object.values(headers));
return new Session({
userData: {
headers,
},
sessionPool,
});
};
この関数の主な目的は、https://ads.tiktok.com/business/creativecenter/inspire/popular/hashtag/pad/en を呼び出し、ヘッダーを返すことです。ヘッダーを取得するには、getApiUrlWithVerificationToken 関数を使用します。
先に進む前に、Crawlee は JSDOM Crawler を使用して JSDOM をネイティブにサポートしていることに言及したいと思います。これは、プレーンな HTTP リクエストと jsdom DOM 実装を使用して Web ページを並列クロールするためのフレームワークを提供します。生の HTTP リクエストを使用して Web ページをダウンロードするため、データ帯域幅が非常に高速かつ効率的です。
getApiUrlWithVerificationToken 関数を作成する方法を見てみましょう:
const getApiUrlWithVerificationToken = async (body, url) => {
log.info(`Getting API session`);
const virtualConsole = new VirtualConsole();
const { window } = new JSDOM(body, {
url,
contentType: 'text/html',
runScripts: 'dangerously',
resources: 'usable' || new CustomResourceLoader(),
// ^ 'usable' faster than custom and works without canvas
pretendToBeVisual: false,
virtualConsole,
});
virtualConsole.on('error', () => {
// ignore errors cause by fake XMLHttpRequest
});
const apiHeaderKeys = ['anonymous-user-id', 'timestamp', 'user-sign'];
const apiValues = {};
let retries = 10;
// api calls made outside of fetch, hack below is to get URL without actual call
window.XMLHttpRequest.prototype.setRequestHeader = (name, value) => {
if (apiHeaderKeys.includes(name)) {
apiValues[name] = value;
}
if (Object.values(apiValues).length === apiHeaderKeys.length) {
retries = 0;
}
};
window.XMLHttpRequest.prototype.open = (method, urlToOpen) => {
if (
['static', 'scontent'].find((x) =>
urlToOpen.startsWith(`https://${x}`),
)
)
log.debug('urlToOpen', urlToOpen);
};
do {
await sleep(4000);
retries--;
} while (retries > 0);
await window.close();
return apiValues;
};
この関数では、CustomResourceLoader を使用してバックグラウンド プロセスを実行し、ブラウザを JSDOM に置き換える仮想コンソールを作成しています。
この特定の例では、API 呼び出しを行うために 3 つの必須ヘッダーが必要です。それらは anonymous-user-id、timestamp、および user-sign です。
XMLHttpRequest.prototype.setRequestHeader を使用して、前述のヘッダーが応答に含まれているかどうかを確認し、含まれている場合はそれらのヘッダーの値を取得し、すべてのヘッダーを取得するまで再試行を繰り返します。
次に、最も重要な部分は、実際にブラウザを使用したりボットのアクティビティを公開したりせずに、XMLHttpRequest.prototype.open を使用して認証データを抽出し、呼び出しを行うことです。
createSessionFunction の最後に、必要なヘッダーを含むセッションが返されます。
メイン コードに移ります。CheerioCrawler を使用し、prenavigationHooks を使用して、前の関数から取得したヘッダーを requestHandler に挿入します。
const crawler = new CheerioCrawler({
sessionPoolOptions: {
maxPoolSize: 1,
createSessionFunction: async (sessionPool) =>
createSessionFunction(sessionPool, proxyConfiguration),
},
preNavigationHooks: [
(crawlingContext) => {
const { request, session } = crawlingContext;
request.headers = {
...request.headers,
...session.userData?.headers,
};
},
],
proxyConfiguration,
});
最後に、リクエスト ハンドラーでヘッダーを使用して呼び出しを行い、ページネーションを処理するすべてのデータを取得するために必要な呼び出しの数を確認します。
async requestHandler(context) {
const { log, request, json } = context;
const { userData } = request;
const { itemsCounter = 0, resultsLimit = 0 } = userData;
if (!json.data) {
throw new Error('BLOCKED');
}
const { data } = json;
const items = data.list;
const counter = itemsCounter items.length;
const dataItems = items.slice(
0,
resultsLimit && counter > resultsLimit
? resultsLimit - itemsCounter
: undefined,
);
await context.pushData(dataItems);
const {
pagination: { page, total },
} = data;
log.info(
`Scraped ${dataItems.length} results out of ${total} from search page ${page}`,
);
const isResultsLimitNotReached =
counter
ここで注意すべき重要な点は、API 呼び出しをいくつでも実行できるようにこのコードを作成していることです。
この特定の例では、1 つのリクエストと 1 つのセッションを作成しただけですが、必要に応じてさらに作成することもできます。最初の API 呼び出しが完了すると、2 番目の API 呼び出しが作成されます。繰り返しますが、必要に応じてさらに電話をかけることもできますが、ここでは 2 つで停止しました。
物事をより明確にするために、コード フローは次のようになります:
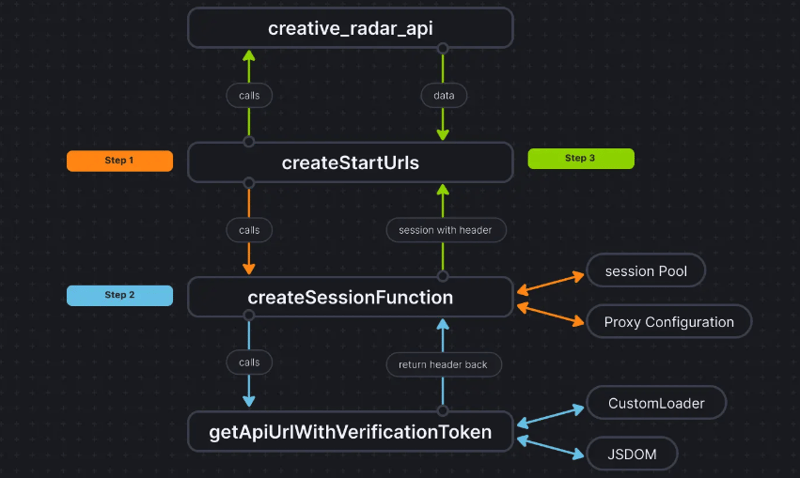
結論
このアプローチは、実際にブラウザを使用せずに認証データを抽出し、そのデータを CheerioCrawler に渡す 3 番目の方法を取得するのに役立ちます。これにより、パフォーマンスが大幅に向上し、RAM 要件が 50% 削減されます。ブラウザベースのスクレイピング パフォーマンスは純粋な Cheerio よりも 10 倍遅いのに対し、JSDOM はわずか 3 ~ 4 倍遅いので、ブラウザより 2 ~ 3 倍高速になります。ベースのスクレイピング。
プロジェクトのコードベースはすでにここにアップロードされています。コードは Apify アクターとして記述されます。詳細については、こちらをご覧ください。ただし、Apify SDK を使用せずに実行することもできます。
このアプローチについて疑問や質問がある場合は、Discord サーバーまでご連絡ください。
-
 formdata()で複数のファイルアップロードを処理するにはどうすればよいですか?formdata() を使用して複数のファイルアップロードを処理すると、複数のファイルアップロードを処理する必要があることがよくあります。 fd.append("fileToUpload[]", files[x]);メソッドはこの目的に使用でき、単一のリクエストで複数...プログラミング 2025-04-20に投稿しました
formdata()で複数のファイルアップロードを処理するにはどうすればよいですか?formdata() を使用して複数のファイルアップロードを処理すると、複数のファイルアップロードを処理する必要があることがよくあります。 fd.append("fileToUpload[]", files[x]);メソッドはこの目的に使用でき、単一のリクエストで複数...プログラミング 2025-04-20に投稿しました -
さまざまな数の列を持つデータベーステーブルを結合するにはどうすればよいですか?異なる列とのテーブルを組み合わせた ] は、データベーステーブルを異なる列とマージしようとする場合に課題に遭遇する可能性があります。簡単な方法は、列が少ないテーブルに欠落している列にnull値を追加することです。 たとえば、テーブルAと表Bの2つの表Aと表AがテーブルBよりも多くの列がある...プログラミング 2025-04-20に投稿しました
-
GO言語ガベージコレクションでスライスメモリを処理する方法は?Go slices:aftertial analysis *q =(*q)[1:len(*q)] rを返します } FUNCプッシュバック(Q *[]文字列、文字列){ *q = append(*q、a) } この場合、要素が正面からポップされると、スライスが...プログラミング 2025-04-20に投稿しました
-
匿名のJavaScriptイベントハンドラーをきれいに削除する方法は?匿名イベントリスナーを削除する]イベントリスナーを追加する要素を追加すると、柔軟性とシンプルさを提供しますが、要素自体を置き換えることなく挑戦をもたらすことができます。 element? element.addeventlistener(event、function(){/はここで動作し...プログラミング 2025-04-20に投稿しました
-
PHPの配列からランダムな要素をどのように抽出しますか?配列からのランダム選択 は、配列からランダムなアイテムを取得することができます。次の配列を検討してください: $items = [523, 3452, 334, 31, 5346]; この配列からランダムなアイテムを取得するために、array_rand()関数を利用することは効果的なソリューシ...プログラミング 2025-04-20に投稿しました
-
すべてのブラウザでテキストを左調整するスラッシュメソッドを実装する] ] text line background background を斜めのラインで左に並べたテキストを達成することは、課題を引き起こす可能性があります。互換性(IE9に戻る)。 .lop((@i -1)); .space@{i} { 幅:floor(@i*@hsize...プログラミング 2025-04-20に投稿しました
-
UTF8 MySQLテーブルでLATIN1文字をUTF8に正しく変換する方法latin1文字をUTF8テーブル内のutf8に変換する diaCriticsのキャラクターが遭遇した問題に遭遇しました( "Jáuòiñe")がUTF8テーブルで存在していないために、utf8テーブルが不足しているために存在していませんでした。 「mysql_se...プログラミング 2025-04-20に投稿しました
-
Laravel Bladeテンプレートの変数をエレガントに定義するにはどうすればよいですか?Laravel Bladeテンプレートの変数を優雅さで定義する ブレードテンプレートに変数を割り当てる方法を理解することは、後で使用するためにデータを保存するために重要です。 「{{{{}}}」を使用して変数を割り当てるのは簡単ですが、常に最もエレガントなソリューションであるとは限りませ...プログラミング 2025-04-20に投稿しました
-
Javaのコレクショントラバーサルのために、for-for-eachループとイテレーターを使用することにパフォーマンスの違いはありますか?vs. Iterator:コレクショントラバーサルの効率この記事では、これら2つのアプローチの効率の違いを調査します。内部的にiteratorを使用します: list a = new ArrayList (); for(整数整数:a){ integer.toString(); } ...プログラミング 2025-04-20に投稿しました
-
セル編集後にカスタムJTableセルレンダリングを維持するにはどうすればよいですか?セル編集後のjtableセルレンダリングの維持 は、カスタムセルのレンダリングと編集機能を実装することでユーザーエクスペリエンスを向上させることができます。ただし、操作を編集した後でも目的のフォーマットが保存されることを保証することが重要です。このようなシナリオでは、編集がコミットされた後...プログラミング 2025-04-20に投稿しました
-
なぜ有効なコードにもかかわらず、PHPで入力をキャプチャするリクエストを要求するのはなぜですか?アドレス指定Php action='' を使用して、フォームの提出後に$ _POSTアレイの内容を確認します。適切に: if(empty($ _ server ['content_type'])) { $ _Server ['content_typ...プログラミング 2025-04-20に投稿しました
-
非同期操作を同時に実行し、JavaScriptでエラーを正しく処理する方法は?並行操作実行を待つ 問題のコードスニペットは非同期操作を実行する際の問題に遭遇します: この実装は、次の操作を開始する前に各操作の完了を順次待ちます。同時実行を有効にするには、修正されたアプローチが必要です。 getValue2async(); const value1 = awa...プログラミング 2025-04-20に投稿しました
-
なぜ画像はまだChromeに境界があるのですか? `border:none;`無効な解決策cromeの画像境界を削除する 1つの頻繁な問題は、chromeとie9の画像を操作する際に遭遇する頻繁な問題です。と「国境:なし;」 CSSで。この問題を解決するには、次のアプローチを検討してください。スタイル。これを回避するには、次のCSS IDブロックを使用して、目的のパディング...プログラミング 2025-04-20に投稿しました
-
なぜ `body {margin:0; } `常にCSSの上限を削除しますか?css の扱います。多くの場合、「ボディ{マージン:0;}」などの提供されたコードは、目的の結果を生成しません。これは、コンテンツの親要素が正のパディング値を持っている場合に発生する可能性があります。特定のマージンの問題に対処することをお勧めします。親要素にパディングがある場合、それを...プログラミング 2025-04-20に投稿しました
-
なぜJavaに署名されていない整数がないのですか?Javaが署名されていない腸の不在を理解する は、オーバーフロー、自己文書化、効率的なゲイン、&& Javaのクリエイターの1人であるGoslingは、シンプルさを主な理由として引用しました。ゴスリングは、ほとんどの人が完全に把握するのに苦労するコーナーケースとニュアンスを追加することに...プログラミング 2025-04-20に投稿しました















中国語を勉強する
- 1 「歩く」は中国語で何と言いますか? 走路 中国語の発音、走路 中国語学習
- 2 「飛行機に乗る」は中国語で何と言いますか? 坐飞机 中国語の発音、坐飞机 中国語学習
- 3 「電車に乗る」は中国語で何と言いますか? 坐火车 中国語の発音、坐火车 中国語学習
- 4 「バスに乗る」は中国語で何と言いますか? 坐车 中国語の発音、坐车 中国語学習
- 5 中国語でドライブは何と言うでしょう? 开车 中国語の発音、开车 中国語学習
- 6 水泳は中国語で何と言うでしょう? 游泳 中国語の発音、游泳 中国語学習
- 7 中国語で自転車に乗るってなんて言うの? 骑自行车 中国語の発音、骑自行车 中国語学習
- 8 中国語で挨拶はなんて言うの? 你好中国語の発音、你好中国語学習
- 9 中国語でありがとうってなんて言うの? 谢谢中国語の発音、谢谢中国語学習
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









