
import streamlit as stimport numpy as npimport pandas as pdimport joblib
stremlit は、機械学習およびデータ サイエンス プロジェクト用のカスタム Web アプリケーションを簡単に作成して共有できるようにする Python ライブラリです。
numpy は、数値計算用の基本的な Python ライブラリです。これは、大規模な多次元配列と行列のサポートと、これらの配列を効率的に操作するための数学関数のコレクションを提供します。
data = { \\\"island\\\": island, \\\"bill_length_mm\\\": bill_length_mm, \\\"bill_depth_mm\\\": bill_depth_mm, \\\"flipper_length_mm\\\": flipper_length_mm, \\\"body_mass_g\\\": body_mass_g, \\\"sex\\\": sex,}input_df = pd.DataFrame(data, index=[0])encode = [\\\"island\\\", \\\"sex\\\"]input_encoded_df = pd.get_dummies(input_df, prefix=encode)入力値は Stremlit によって作成された入力フォームから取得され、カテゴリ変数はモデルの作成時と同じルールを使用してエンコードされます。各データの順序もモデル作成時と同じである必要があることに注意してください。順序が異なる場合、モデルを使用して予測を実行するとエラーが発生します。
clf = joblib.load(\\\"penguin_classifier_model.pkl\\\")
「penguin_classifier_model.pkl」は、以前に保存したモデルが保存されているファイルです。このファイルには、トレーニングされた RandomForestClassifier がバイナリ形式で含まれています。このコードを実行すると、モデルが clf にロードされ、新しいデータの予測と評価に使用できるようになります。
prediction = clf.predict(input_encoded_df)prediction_proba = clf.predict_proba(input_encoded_df)
clf.predict(input_encoded_df): トレーニングされたモデルを使用して、新しいエンコードされた入力データのクラスを予測し、結果を予測に保存します。
clf.predict_proba(input_encoded_df): 各クラスの確率を計算し、結果をprediction_proba.
Stremlit Community Cloud (https://streamlit.io/cloud) にアクセスし、GitHub リポジトリの URL を指定することで、開発したアプリケーションをインターネット上に公開できます。

@allison_horst によるアートワーク (https://github.com/allisonhorst)
モデルは、機械学習手法を実践するためのデータセットとして広く認識されているパーマー ペンギン データセットを使用してトレーニングされます。このデータセットは、南極のパーマー諸島の 3 種のペンギン (アデリー、ヒゲゼンマイ、ジェンツー) に関する情報を提供します。主な機能は次のとおりです:
このデータセットは Kaggle から提供されており、ここからアクセスできます。特徴の多様性により、分類モデルを構築し、種の予測における各特徴の重要性を理解するのに優れた選択肢となります。
","image":"http://www.luping.net/uploads/20241006/17282217676702924713227.png","datePublished":"2024-11-02T21:56:21+08:00","dateModified":"2024-11-02T21:56:21+08:00","author":{"@type":"Person","name":"luping.net","url":"https://www.luping.net/articlelist/0_1.html"}} ブラウズ:631
ブラウズ:631
機械学習モデルは本質的に、予測を行ったり、データ内のパターンを見つけたりするために使用される一連のルールまたはメカニズムです。非常に簡単に言うと (単純化しすぎることを恐れずに)、Excel の最小二乗法を使用して計算された傾向線もモデルです。ただし、実際のアプリケーションで使用されるモデルはそれほど単純ではありません。単純な方程式だけでなく、より複雑な方程式やアルゴリズムが含まれることがよくあります。
この投稿では、プロセスの雰囲気をつかむために、非常に単純な機械学習モデルを構築し、それを非常に単純な Web アプリとしてリリースすることから始めます。
ここでは、ML モデル自体ではなく、プロセスのみに焦点を当てます。また、Streamlit と Streamlit Community Cloud を使用して、Python Web アプリケーションを簡単にリリースします。
機械学習用の人気のある Python ライブラリである scikit-learn を使用すると、データを迅速にトレーニングし、単純なタスク用のわずか数行のコードでモデルを作成できます。その後、モデルは joblib を使用して再利用可能なファイルとして保存できます。この保存されたモデルは、Web アプリケーションの通常の Python ライブラリと同様にインポート/ロードできるため、アプリはトレーニングされたモデルを使用して予測を行うことができます!
アプリURL: https://yh-machine-learning.streamlit.app/
GitHub: https://github.com/yoshan0921/yh-machine-learning.git
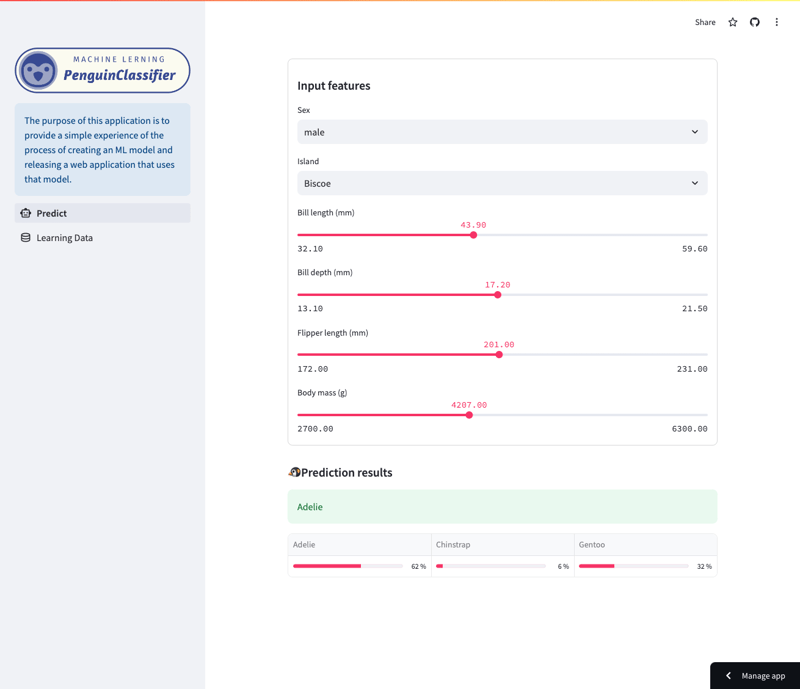
このアプリを使用すると、パーマー ペンギン データセットでトレーニングされたランダム フォレスト モデルによって行われた予測を調べることができます。 (トレーニング データの詳細については、この記事の最後を参照してください。)
具体的には、このモデルは、種、島、くちばしの長さ、足ひれの長さ、体の大きさ、性別などのさまざまな特徴に基づいてペンギンの種を予測します。ユーザーはアプリを操作して、さまざまな機能がモデルの予測にどのような影響を与えるかを確認できます。
予測画面
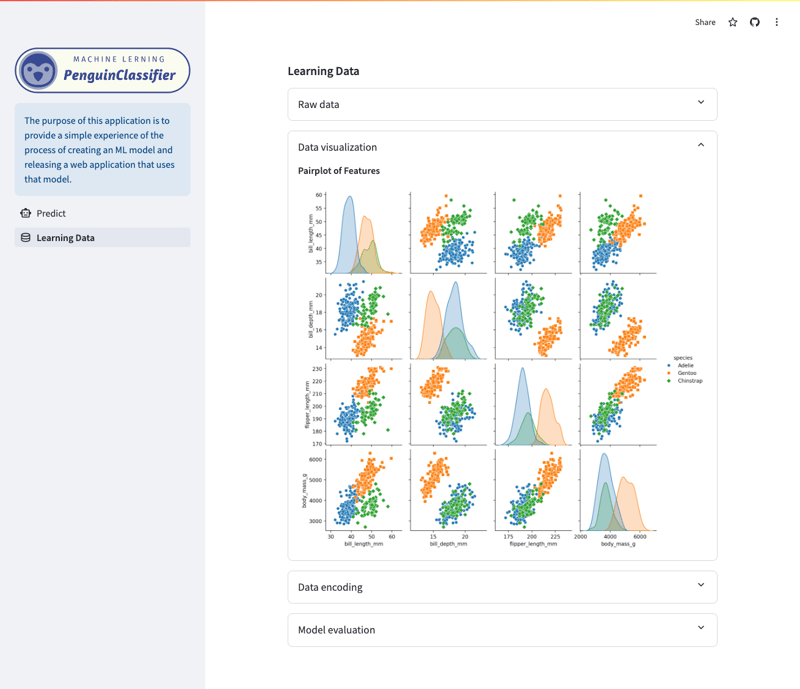
学習データ・可視化画面
import pandas as pd from sklearn.model_selection import train_test_split from sklearn.ensemble import RandomForestClassifier from sklearn.metrics import accuracy_score import joblib
pandas は、データ操作と分析に特化した Python ライブラリです。 DataFrame を使用したデータの読み込み、前処理、構造化をサポートし、機械学習モデル用のデータを準備します。
sklearn は、トレーニングと評価のためのツールを提供する機械学習用の包括的な Python ライブラリです。この記事では、ランダムフォレストと呼ばれる学習手法を使用してモデルを構築します。
joblib は、機械学習モデルなどの Python オブジェクトを非常に効率的な方法で保存およびロードするのに役立つ Python ライブラリです。
df = pd.read_csv("./dataset/penguins_cleaned.csv")
X_raw = df.drop("species", axis=1)
y_raw = df.species
データセット (トレーニング データ) を読み込み、特徴 (X) とターゲット変数 (y) に分割します。
encode = ["island", "sex"]
X_encoded = pd.get_dummies(X_raw, columns=encode)
target_mapper = {"Adelie": 0, "Chinstrap": 1, "Gentoo": 2}
y_encoded = y_raw.apply(lambda x: target_mapper[x])
カテゴリ変数は、ワンホット エンコーディング (X_encoded) を使用して数値形式に変換されます。たとえば、「island」にカテゴリ「Biscoe」、「Dream」、および「Torgersen」が含まれている場合、それぞれに新しい列が作成されます (island_Biscoe、island_Dream、island_Torgersen)。セックスでも同じことが行われます。元のデータが「Biscoe」の場合、island_Biscoe 列は 1 に設定され、その他の列は 0 に設定されます。
ターゲット変数の種は数値 (y_encoded) にマッピングされます。
x_train, x_test, y_train, y_test = train_test_split(
X_encoded, y_encoded, test_size=0.3, random_state=1
)
モデルを評価するには、トレーニングに使用されていないデータに対するモデルのパフォーマンスを測定する必要があります。 7:3 は、機械学習の一般的な手法として広く使用されています。
clf = RandomForestClassifier() clf.fit(x_train, y_train)
fit メソッドはモデルのトレーニングに使用されます。
x_train は説明変数のトレーニング データを表し、y_train はターゲット変数を表します。
このメソッドを呼び出すと、学習データに基づいて学習されたモデルが clf.
joblib.dump(clf, "penguin_classifier_model.pkl")
joblib.dump() は、Python オブジェクトをバイナリ形式で保存する関数です。モデルをこの形式で保存すると、モデルをファイルからロードして、再度トレーニングすることなくそのまま使用できます。
import streamlit as st import numpy as np import pandas as pd import joblib
stremlit は、機械学習およびデータ サイエンス プロジェクト用のカスタム Web アプリケーションを簡単に作成して共有できるようにする Python ライブラリです。
numpy は、数値計算用の基本的な Python ライブラリです。これは、大規模な多次元配列と行列のサポートと、これらの配列を効率的に操作するための数学関数のコレクションを提供します。
data = {
"island": island,
"bill_length_mm": bill_length_mm,
"bill_depth_mm": bill_depth_mm,
"flipper_length_mm": flipper_length_mm,
"body_mass_g": body_mass_g,
"sex": sex,
}
input_df = pd.DataFrame(data, index=[0])
encode = ["island", "sex"]
input_encoded_df = pd.get_dummies(input_df, prefix=encode)
入力値は Stremlit によって作成された入力フォームから取得され、カテゴリ変数はモデルの作成時と同じルールを使用してエンコードされます。各データの順序もモデル作成時と同じである必要があることに注意してください。順序が異なる場合、モデルを使用して予測を実行するとエラーが発生します。
clf = joblib.load("penguin_classifier_model.pkl")
「penguin_classifier_model.pkl」は、以前に保存したモデルが保存されているファイルです。このファイルには、トレーニングされた RandomForestClassifier がバイナリ形式で含まれています。このコードを実行すると、モデルが clf にロードされ、新しいデータの予測と評価に使用できるようになります。
prediction = clf.predict(input_encoded_df) prediction_proba = clf.predict_proba(input_encoded_df)
clf.predict(input_encoded_df): トレーニングされたモデルを使用して、新しいエンコードされた入力データのクラスを予測し、結果を予測に保存します。
clf.predict_proba(input_encoded_df): 各クラスの確率を計算し、結果をprediction_proba.
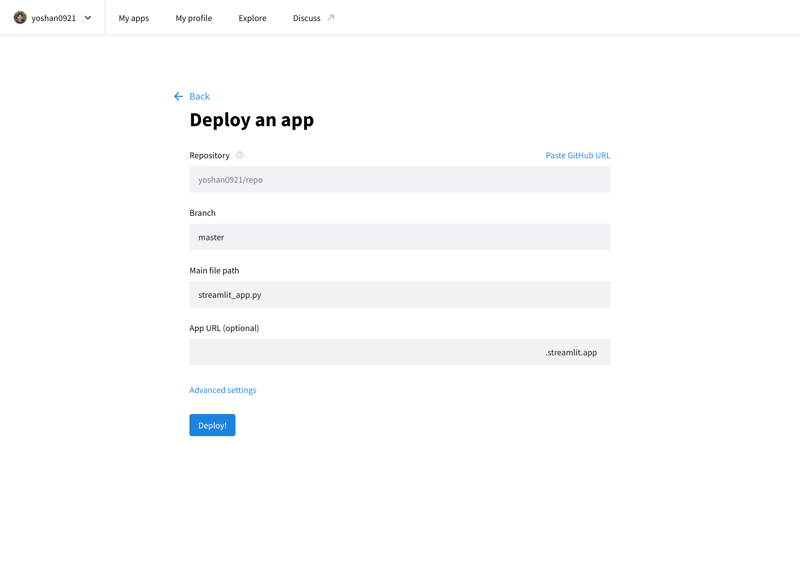
Stremlit Community Cloud (https://streamlit.io/cloud) にアクセスし、GitHub リポジトリの URL を指定することで、開発したアプリケーションをインターネット上に公開できます。

@allison_horst によるアートワーク (https://github.com/allisonhorst)
モデルは、機械学習手法を実践するためのデータセットとして広く認識されているパーマー ペンギン データセットを使用してトレーニングされます。このデータセットは、南極のパーマー諸島の 3 種のペンギン (アデリー、ヒゲゼンマイ、ジェンツー) に関する情報を提供します。主な機能は次のとおりです:
このデータセットは Kaggle から提供されており、ここからアクセスできます。特徴の多様性により、分類モデルを構築し、種の予測における各特徴の重要性を理解するのに優れた選択肢となります。















免責事項: 提供されるすべてのリソースの一部はインターネットからのものです。お客様の著作権またはその他の権利および利益の侵害がある場合は、詳細な理由を説明し、著作権または権利および利益の証拠を提出して、電子メール [email protected] に送信してください。 できるだけ早く対応させていただきます。
Copyright© 2022 湘ICP备2022001581号-3










