
指定されたスタックから重複を削除する Java プログラム
2024 年 9 月 2 日に公開
 ブラウズ:790
ブラウズ:790
この記事では、Java のスタックから重複要素を削除する 2 つの方法を検討します。 ネストされたループ を使用した単純なアプローチと、HashSet を使用したより効率的な方法を比較します。目標は、重複の削除を最適化する方法を実証し、各アプローチのパフォーマンスを評価することです。
問題ステートメント
重複した要素をスタックから削除する Java プログラムを作成します。
入力
Stackdata = initData(10L);
出力
Unique elements using Naive Approach: [1, 4, 3, 2, 8, 7, 5] Time spent for Naive Approach: 18200 nanoseconds Unique elements using Optimized Approach: [1, 4, 3, 2, 8, 7, 5] Time spent for Optimized Approach: 34800 nanoseconds
特定のスタックから重複を削除するには、2 つのアプローチがあります -
- 単純なアプローチ: 2 つの ネストされたループを作成して、どの要素が既に存在するかを確認し、結果スタックの戻り値に要素が追加されるのを防ぎます。
- HashSet アプローチ: Set を使用して一意の要素を保存し、その O(1) 複雑性を利用して要素が存在するかどうかを確認します。
ランダムなスタックの生成とクローン作成
以下は、Java プログラムが最初にランダムなスタックを構築し、その後使用するためにその複製を作成します -
private static Stack initData(Long size) {
Stack stack = new Stack ();
Random random = new Random();
int bound = (int) Math.ceil(size * 0.75);
for (int i = 0; i manualCloneStack(Stack stack) {
Stack newStack = new Stack ();
for (Integer item: stack) {
newStack.push(item);
}
return newStack;
}
initData は、指定されたサイズと 1 ~ 100 の範囲のランダムな要素を持つスタックの作成に役立ちます。
manualCloneStack は、別のスタックからデータをコピーしてデータを生成し、それを 2 つのアイデア間のパフォーマンス比較に使用します。
Naïve アプローチを使用して特定のスタックから重複を削除します
以下は、素朴なアプローチを使用して特定のスタックから重複を削除するステップです -
- タイマーを開始します。
- 一意の要素を格納するために空のスタックを作成します。
- while ループを使用して繰り返し、元のスタックが空になるまで続行し、最上位の要素をポップします。
- resultStack.contains(element) を使用して重複をチェックし、要素がすでに結果スタックにあるかどうかを確認します。
- 要素が結果スタックにない場合は、結果スタックに追加します。
- 終了時刻を記録し、費やした合計時間を計算します。
- 返される結果
例
以下は、素朴なアプローチを使用して特定のスタックから重複を削除する Java プログラムです -
public static Stack idea1(Stack stack) {
long start = System.nanoTime();
Stack resultStack = new Stack ();
while (!stack.isEmpty()) {
int element = stack.pop();
if (!resultStack.contains(element)) {
resultStack.add(element);
}
}
System.out.println("Time spent for idea1 is %d nanosecond".formatted(System.nanoTime() - start));
return resultStack;
}
素朴なアプローチの場合、
を使用しますwhile (!stack.isEmpty()) です。
resultStack.contains(element)
要素が既に存在するかどうかを確認します。最適化されたアプローチ (HashSet) を使用して、指定されたスタックから重複を削除します。
以下は、最適化されたアプローチを使用して特定のスタックから重複を削除する手順です-
- タイマーをスタート
- 表示された要素を追跡するためのセットを作成します (O(1) 複雑さチェック用)。
- 固有の要素を保存するための一時スタックを作成します。
- を使用して繰り返し、ループ はスタックが空になるまで継続します。
- スタックから一番上の要素を削除します。
- 重複を確認するには、seen.contains(element) を使用して、要素がすでにセット内にあるかどうかを確認します。
- 要素がセットにない場合は、表示されているスタックと一時スタックの両方に追加します。
- 終了時刻を記録し、費やした合計時間を計算します。
- 結果を返します
例
以下は、HashSet を使用して指定されたスタックから重複を削除する Java プログラムです -
public static Stackidea2(Stack stack) { long start = System.nanoTime(); Set seen = new HashSet(); Stack tempStack = new Stack(); while (!stack.isEmpty()) { int element = stack.pop(); if (!seen.contains(element)) { seen.add(element); tempStack.push(element); } } System.out.println("Time spent for idea2 is %d nanosecond".formatted(System.nanoTime() - start)); return tempStack; }
最適化されたアプローチには
を使用しますSet seen 両方のアプローチを併用する
以下は、上記の両方のアプローチを使用して、特定のスタックから重複を削除する手順です-
- データを初期化します。
- initData(Long size) メソッドを使用して、ランダムな整数で満たされたスタックを作成します。
スタックのクローンを作成します。 - cloneStack(スタック スタック) メソッドを使用して、元のスタックの正確なコピーを作成します。
- initData. で初期スタックを生成します
- cloneStack を使用してこのスタックのクローンを作成します。
- 単純なアプローチ を適用して、元のスタックから重複を削除します。
- 最適化されたアプローチを適用して、複製されたスタックから重複を削除します。 各方法にかかる時間と、両方のアプローチによって生成される固有の要素を表示します
例
以下は、上記の両方のアプローチを使用してスタックから重複要素を削除する Java プログラムです -
インポート java.util.HashSet; java.util.Randomをインポートします。 java.util.Setをインポートします。 java.util.Stackをインポートします。 パブリック クラス DuplicateStackElements { private static Stack
import java.util.HashSet;
import java.util.Random;
import java.util.Set;
import java.util.Stack;
public class DuplicateStackElements {
private static Stack initData(Long size) {
Stack stack = new Stack();
Random random = new Random();
int bound = (int) Math.ceil(size * 0.75);
for (int i = 0; i cloneStack(Stack stack) {
Stack newStack = new Stack();
newStack.addAll(stack);
return newStack;
}
public static Stack idea1(Stack stack) {
long start = System.nanoTime();
Stack resultStack = new Stack();
while (!stack.isEmpty()) {
int element = stack.pop();
if (!resultStack.contains(element)) {
resultStack.add(element);
}
}
System.out.printf("Time spent for idea1 is %d nanoseconds%n", System.nanoTime() - start);
return resultStack;
}
public static Stack idea2(Stack stack) {
long start = System.nanoTime();
Set seen = new HashSet();
Stack tempStack = new Stack();
while (!stack.isEmpty()) {
int element = stack.pop();
if (!seen.contains(element)) {
seen.add(element);
tempStack.push(element);
}
}
System.out.printf("Time spent for idea2 is %d nanoseconds%n", System.nanoTime() - start);
return tempStack;
}
public static void main(String[] args) {
Stack data1 = initData(10L);
Stack data2 = cloneStack(data1);
System.out.println("Unique elements using idea1: " idea1(data1));
System.out.println("Unique elements using idea2: " idea2(data2));
}
} 出力
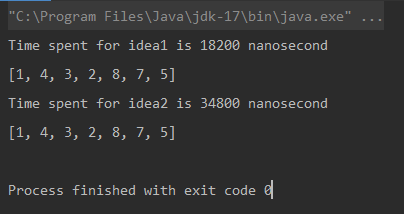
* 測定単位はナノ秒です。
public static void main(String[] args) {
Stack data1 = initData();
Stack data2 = manualCloneStack(data1);
idea1(data1);
idea2(data2);
}
| 100 個の要素 | 1000 個の要素 | 10000 要素 | 100000 要素 | 1000000 要素 |
|
| 693100 | |||||
| 135800 | 36456100
|
リリースステートメント
この記事は次の場所に転載されています: https://www.tutorialspoint.com/java-program-to-remove-duplicates-from-a-given-stack 侵害がある場合は、[email protected] に連絡して削除してください。
最新のチュートリアル
もっと>
-
 MySQL を使用して今日が誕生日のユーザーを見つけるにはどうすればよいですか?MySQL を使用して今日の誕生日を持つユーザーを識別する方法MySQL を使用して今日がユーザーの誕生日かどうかを判断するには、誕生日が一致するすべての行を検索する必要があります。今日の日付。これは、UNIX タイムスタンプとして保存されている誕生日と今日の日付を比較する単純な MySQL クエリ...プログラミング 2025 年 1 月 5 日に公開
MySQL を使用して今日が誕生日のユーザーを見つけるにはどうすればよいですか?MySQL を使用して今日の誕生日を持つユーザーを識別する方法MySQL を使用して今日がユーザーの誕生日かどうかを判断するには、誕生日が一致するすべての行を検索する必要があります。今日の日付。これは、UNIX タイムスタンプとして保存されている誕生日と今日の日付を比較する単純な MySQL クエリ...プログラミング 2025 年 1 月 5 日に公開 -
「if」ステートメントを超えて: 明示的な「bool」変換を伴う型をキャストせずに使用できる場所は他にありますか?キャストなしで bool へのコンテキスト変換が可能クラスは bool への明示的な変換を定義し、そのインスタンス 't' を条件文で直接使用できるようにします。ただし、この明示的な変換では、キャストなしで bool として 't' を使用できる場所はどこですか?コン...プログラミング 2025 年 1 月 5 日に公開
-
macOS 上の Django で「ImproperlyConfigured: MySQLdb モジュールのロード中にエラーが発生しました」を修正する方法?MySQL の不適切な構成: 相対パスの問題Django で python manage.py runserver を実行すると、次のエラーが発生する場合があります:ImproperlyConfigured: Error loading MySQLdb module: dlopen(/Library...プログラミング 2025 年 1 月 5 日に公開
-
Go で WebSocket を使用してリアルタイム通信を行うチャット アプリケーション、ライブ通知、共同作業ツールなど、リアルタイムの更新が必要なアプリを構築するには、従来の HTTP よりも高速でインタラクティブな通信方法が必要です。そこで WebSocket が登場します。今日は、アプリケーションにリアルタイム機能を追加できるように、Go で WebSo...プログラミング 2025 年 1 月 5 日に公開
-
一意の ID を保持し、重複した名前を処理しながら、PHP で 2 つの連想配列を結合するにはどうすればよいですか?PHP での連想配列の結合PHP では、2 つの連想配列を 1 つの配列に結合するのが一般的なタスクです。次のリクエストを考えてみましょう:問題の説明:提供されたコードは 2 つの連想配列 $array1 と $array2 を定義します。目標は、両方の配列のすべてのキーと値のペアを統合する新しい配...プログラミング 2025 年 1 月 5 日に公開
-
データ挿入時の「一般エラー: 2006 MySQL サーバーが消えました」を修正するにはどうすればよいですか?レコードの挿入中に「一般エラー: 2006 MySQL サーバーが消えました」を解決する方法はじめに:MySQL データベースにデータを挿入すると、「一般エラー: 2006 MySQL サーバーが消えました。」というエラーが発生することがあります。このエラーは、通常、MySQL 構成内の 2 つの変...プログラミング 2025 年 1 月 5 日に公開
-
Bootstrap 4 ベータ版の列オフセットはどうなりましたか?Bootstrap 4 ベータ: 列オフセットの削除と復元Bootstrap 4 は、ベータ 1 リリースで、その方法に大幅な変更を導入しました。列がオフセットされました。ただし、その後の Beta 2 リリースでは、これらの変更は元に戻されました。offset-md-* から ml-autoBoo...プログラミング 2025 年 1 月 5 日に公開
-
Pandas DataFrame 列から Null 値を含む行を削除するにはどうすればよいですか?Pandas DataFrame 列からの Null 値の削除特定の列の Null 値に基づいて Pandas DataFrame から行を削除するには、次の手順に従います手順:1.列を特定します:削除する null 値を含む DataFrame 内の列を特定します。この場合、それは「EPS」列です...プログラミング 2025 年 1 月 1 日に公開
-
Go でインターフェイス値のスライスを正しく入力するにはどうすればよいですか?インターフェイス値のスライスを型アサートするプログラミングでは、インターフェイス値のスライスを型アサートする必要がある状況に遭遇することがよくあります。ただし、これによりエラーが発生する場合があります。インターフェイス値のスライスのアサートが常に実行可能であるとは限らない理由を詳しく見てみましょう。...プログラミング 2025 年 1 月 1 日に公開
-
`list.sort()` が `None` を返すのはなぜですか? ソートされたリストを取得するにはどうすればよいですか?Sort() メソッドとその戻り値について一意の単語のリストを並べ替えて返そうとすると、よくある問題: 「return list.sort()」構文では、期待どおりにソートされたリストが返されません。これは、sort() メソッドの目的と矛盾しているように見えるため、混乱を招く可能性があります。明確...プログラミング 2025 年 1 月 1 日に公開
-
「preg_match」正規表現で大文字と小文字を区別しないようにするにはどうすればよいですか?preg_match の大文字と小文字を区別しないようにする質問に示されているコード スニペットでは、大文字と小文字の区別により、意図した結果が得られません。これを修正するには、正規表現で i 修飾子を使用して、大文字と小文字が区別されないようにすることができます。コードを変更する方法は次のとおりで...プログラミング 2025 年 1 月 1 日に公開
-
DocumentFilter はどのようにして JTextField 入力を整数に効果的に制限できるのでしょうか?JTextField 入力を整数にフィルタリング: DocumentFilter を使用した効果的なアプローチキー リスナーを使用して JTextField の数値入力を検証するのは直感的ではありますが、不十分です。代わりに、より包括的なアプローチは、DocumentFilter を採用することです...プログラミング 2025 年 1 月 1 日に公開
-
Go プログラムから `ulimit -n` を設定するにはどうすればよいですか?Golang プログラムから ulimit -n を設定する方法Go の syscall.Setrlimit 関数を使用すると、Go プログラム内から ulimit -n を設定できます。これにより、グローバルな変更を加えずにプログラム内でリソース制限をカスタマイズできます。setrlimit につ...プログラミング 2024 年 12 月 31 日公開
-
Java が配列を異常に出力するのはなぜですか?その内容を正しく出力するにはどうすればよいですか?Java での奇妙な配列印刷Java では、配列は単なる値のコレクションではありません。これらは、特定の動作と表現を持つオブジェクトです。 System.out.println(arr) を使用して配列を印刷する場合、実際にはその内容ではなくオブジェクト自体を印刷します。このデフォルトの表現では、配...プログラミング 2024 年 12 月 31 日公開
-
Lithe を使用した PHP でのセッション管理: 基本的なセットアップから高度な使用法までWeb アプリケーションについて話すとき、最初のニーズの 1 つは、ユーザーがページ間を移動するときにユーザー情報を維持することです。そこで、Lithe の セッション管理 が登場し、ログイン情報やユーザー設定などのデータを保存できるようになります。 シンプルで素早いインストール L...プログラミング 2024 年 12 月 31 日公開















中国語を勉強する
- 1 「歩く」は中国語で何と言いますか? 走路 中国語の発音、走路 中国語学習
- 2 「飛行機に乗る」は中国語で何と言いますか? 坐飞机 中国語の発音、坐飞机 中国語学習
- 3 「電車に乗る」は中国語で何と言いますか? 坐火车 中国語の発音、坐火车 中国語学習
- 4 「バスに乗る」は中国語で何と言いますか? 坐车 中国語の発音、坐车 中国語学習
- 5 中国語でドライブは何と言うでしょう? 开车 中国語の発音、开车 中国語学習
- 6 水泳は中国語で何と言うでしょう? 游泳 中国語の発音、游泳 中国語学習
- 7 中国語で自転車に乗るってなんて言うの? 骑自行车 中国語の発音、骑自行车 中国語学習
- 8 中国語で挨拶はなんて言うの? 你好中国語の発音、你好中国語学習
- 9 中国語でありがとうってなんて言うの? 谢谢中国語の発音、谢谢中国語学習
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









