
深さ優先検索 (DFS)
 ブラウズ:921
ブラウズ:921
グラフの深さ優先検索は、グラフ内の頂点から開始し、バックトラックする前に可能な限りグラフ内のすべての頂点を訪問します。
グラフの深さ優先検索は、ツリー トラバーサル、ツリー トラバーサルで説明したツリーの深さ優先検索に似ています。ツリーの場合、ルートから検索が開始されます。グラフでは、任意の頂点から検索を開始できます。
ツリーの深さ優先検索では、まずルートにアクセスし、次にルートのサブツリーに再帰的にアクセスします。同様に、グラフの深さ優先検索は最初に頂点を訪問し、次にその頂点に隣接するすべての頂点を再帰的に訪問します。違いは、グラフにサイクルが含まれる可能性があり、無限再帰につながる可能性があることです。この問題を回避するには、すでに訪問した頂点を追跡する必要があります。
検索は、グラフ内で可能な限り「深く」検索するため、深さ優先と呼ばれます。検索はある頂点 v から始まります。v を訪問した後、v の未訪問の近傍を訪問します。v に未訪問の近傍がない場合、検索は v に到達した頂点に戻ります。グラフが接続されており、検索が開始されると仮定します。任意の頂点からすべての頂点に到達できます。
深さ優先検索アルゴリズム
深さ優先検索のアルゴリズムは、以下のコードで説明されています。
入力: G = (V, E) および開始頂点 v
出力: v
をルートとする DFS ツリー
1 ツリー dfs(頂点 v) {
2 訪問 v;
v
の近隣 w ごとに 3
4 if (w が訪問されていない) {
5 v をツリー内の w の親として設定します;
6 dfs(w);
7 }
8 }
isVisited という名前の配列を使用して、頂点が訪問されたかどうかを示すことができます。最初は、各頂点 i の isVisited[i] は false です。頂点、たとえば v が訪問されると、isVisited[v] は true に設定されます。
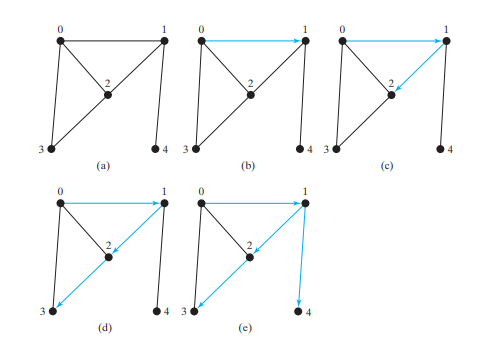
下の図 (a) のグラフを考えてみましょう。頂点 0 から深さ優先検索を開始するとします。最初に 0 を訪問し、次にその近隣のいずれか (たとえば 1) を訪問します。次の図 (b) に示すように、今度は 1 が訪問されます。頂点 1 には 3 つの近傍 (0、2、および 4) があります。0 はすでに訪問されているため、2 または 4 のいずれかを訪問します。2 を選択しましょう。次の図 (c) に示すように、現在 2 が訪問されています。頂点 2 には、0、1、および 3 という 3 つの近傍があります。0 と 1 はすでに訪問されているため、3 を選択します。下の図 (d) に示すように、3 が訪問されます。この時点で、頂点は次の順序で訪問されています:
0、1、2、3
3 の近傍をすべて訪問したので、2 に戻ります。2 の頂点をすべて訪問したので、1 に戻ります。4 は 1 に隣接していますが、4 は訪問されていません。したがって、次の図 (e) に示すように、4 にアクセスします。 4 の近隣すべてを訪問したので、1 に戻ります。
1 のすべての近傍を訪問したため、0 に戻ります。0 のすべての近傍を訪問したため、検索は終了します。
各エッジと各頂点は 1 回だけ訪問されるため、dfs メソッドの時間計算量は O(|E| |V|) になります。ここで、|E | はエッジの数を示し、|V| は頂点の数を示します。
深さ優先検索の実装
上記のコードの DFS のアルゴリズムは再帰を使用します。それを実装するには再帰を使用するのが自然です。あるいは、スタックを使用することもできます。
dfs(int v) メソッドは、AbstractGraph.java の 164 ~ 193 行目に実装されています。これは、頂点 v をルートとする Tree クラスのインスタンスを返します。このメソッドは、検索された頂点をリスト searchOrder (165 行目) に格納し、各頂点の親を配列 parent (166 行目) に格納し、isVisited 頂点が訪問されたかどうかを示す配列 (行 171)。これは、ヘルパー メソッド dfs(v,parent,searchOrder,isVisited) を呼び出して、深さ優先検索を実行します (174 行目)。
再帰ヘルパー メソッドでは、頂点u から検索が開始されます。 u は 184 行目で searchOrder に追加され、訪問済みとしてマークされます (185 行目)。 u の未訪問の各近傍に対して、このメソッドが再帰的に呼び出され、深さ優先検索が実行されます。頂点 e.v にアクセスすると、e.v の親が parent[e.v] に格納されます (189 行目)。このメソッドは、接続されたグラフまたは接続されたコンポーネントのすべての頂点にアクセスすると戻ります。
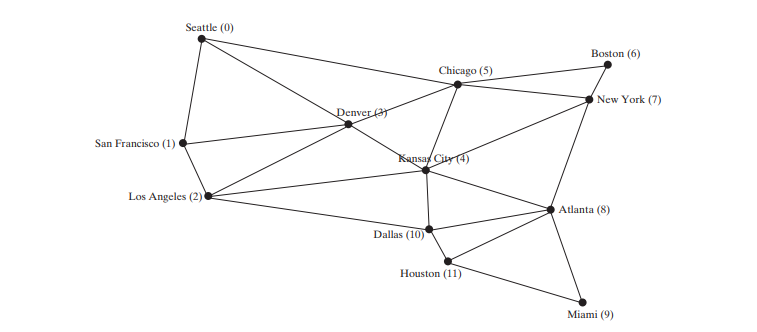
シカゴ シアトル サンフランシスコ ロサンゼルス デンバー
カンザスシティ ニューヨーク ボストン アトランタ マイアミ ヒューストン ダラス
シアトルの親はシカゴです
サンフランシスコの親はシアトルです
ロサンゼルスの親はサンフランシスコ
デンバーの親はロサンゼルスです
カンザスシティの親はデンバーです
ボストンの親はニューヨークです
ニューヨークの親はカンザスシティです
アトランタの親はニューヨーク
マイアミの親はアトランタです
ダラスの親はヒューストン
ヒューストンの親はマイアミです
深さ優先検索を使用すると、次のような多くの問題を解決できます:
- グラフがつながっているかどうかを検出します。任意の頂点からグラフを検索します。検索された頂点の数がグラフの頂点の数と同じ場合、グラフは接続されます。それ以外の場合、グラフは接続されません。
- 2 つの頂点間にパスがあるかどうかを検出します。
- 2 つの頂点間のパスを検索します。
- 接続されているすべてのコンポーネントを検索します。連結コンポーネントは、頂点のすべてのペアがパスによって接続されている最大連結部分グラフです。
- グラフに周期があるかどうかを検出します。
- グラフ内のサイクルを見つけます。
- ハミルトニアン パス/サイクルを検索します。グラフ内の
- ハミルトニアン パス は、グラフ内の各頂点を 1 回だけ訪問するパスです。 ハミルトニアン サイクルは、グラフ内の各頂点を正確に 1 回訪問し、開始頂点に戻ります。
-
 PHPの2つの等しいサイズの配列から値を同期して反復して印刷するにはどうすればよいですか?同じサイズの2つの配列の2つの配列から値を同期して反復して印刷する場合、同サイズの2つの配列、1つは対応する名前を含む2つのアレイを作成するとき、困難は不適切なsyntaxに起因する可能性があります。アレイ: foreach($ codes as $ code、$ names as $ na...プログラミング 2025-07-15に投稿されました
PHPの2つの等しいサイズの配列から値を同期して反復して印刷するにはどうすればよいですか?同じサイズの2つの配列の2つの配列から値を同期して反復して印刷する場合、同サイズの2つの配列、1つは対応する名前を含む2つのアレイを作成するとき、困難は不適切なsyntaxに起因する可能性があります。アレイ: foreach($ codes as $ code、$ names as $ na...プログラミング 2025-07-15に投稿されました -
ubuntu/linuxにmysql-pythonをインストールするときに\ "mysql_configが見つかりません\"エラーを修正する方法は?mysql-pythonインストールエラー: "mysql_config not obst" をubuntu/linuxボックスにインストールしようとする試みを試みます。このエラーは、MySQL開発ライブラリが欠落しているために発生します。 この問題を解決するには、...プログラミング 2025-07-15に投稿されました
-
GO言語でエクスポートパッケージタイプを動的に発見する方法は?エクスポートされたパッケージタイプを動的に見つける 反射パッケージの限られたタイプの発見機能とは対照的に、この記事では、ランタイムですべてのパッケージタイプ(特に構造体)を発見するための代替方法を説明します。後で) in go 1.5および後続のバージョンでは、タイプとインポーターパッ...プログラミング 2025-07-15に投稿されました
-
Firefoxバックボタンを使用すると、JavaScriptの実行が停止するのはなぜですか?navigational Historyの問題:JavaScriptは、Firefoxバックボタンを使用した後に実行を停止します ユーザーは、JavaScriptスクリプトが以前の訪問ページを介して回復したときに実行されない問題に遭遇する可能性があります。この問題は、ChromeやInt...プログラミング 2025-07-15に投稿されました
-
プログラムを終了する前に、C ++のヒープ割り当てを明示的に削除する必要がありますか?プログラム出口にもかかわらず、Cでの明示的な削除 次の例を考慮してください。 a* a = new a(); a-> dosomething(); a; 0を返します。 } この例では、「削除」ステートメントは、「a」ポインターに割り当てられたヒープメモ...プログラミング 2025-07-15に投稿されました
-
Go Webアプリケーションはいつデータベース接続を閉じますか?Go Webアプリケーションのデータベース接続の管理 PostgreSQLなどのデータベースを使用する単純なGO Webアプリケーションで、データベース接続の閉鎖のタイミングが考慮されます。これは、無期限に実行されるアプリケーションでこれをいつ、どのように処理するかを深く掘り下げます。 f...プログラミング 2025-07-15に投稿されました
-
ネストされた機能とPythonの閉鎖の違いは何ですかネストされた関数とpython の閉鎖と閉鎖は、表面的に閉鎖に似ている一方で、キー差のために根本的に異なります: [非閉ざされた Pythonのネストされた関数は、以下の要件を満たしていないため閉鎖とは見なされません: は、それらは、エンクルの外側に実行される場合、 に実行...プログラミング 2025-07-15に投稿されました
-
Javaの「DD/MM/YYYY HH:MM:SS.SS」形式で現在の日付と時刻を正しく表示するにはどうすればよいですか?「dd/mm/yyyy hh:mm:ss.ss」形式で現在の日付と時刻を表示する方法。異なるフォーマットパターンを持つさまざまなSimpleDateFormatインスタンスの使用にあります。 java.text.simpledateformat; java.util.calendarをインポ...プログラミング 2025-07-15に投稿されました
-
オブジェクトフィット:IEとEdgeでカバーが失敗します、修正方法は?object-fit:カバーがIEとEDGEで失敗します。 CSSでは、一貫した画像の高さを維持するために、ブラウザ全体でシームレスに動作します。ただし、IEとEdgeでは、独特の問題が発生します。ブラウザをスケーリングすると、画像は高さをズームするのではなく幅でサイズを変更し、外観を歪め...プログラミング 2025-07-15に投稿されました
-
匿名のJavaScriptイベントハンドラーをきれいに削除する方法は?匿名イベントリスナーを削除する]イベントリスナーを追加する要素を追加すると、柔軟性とシンプルさを提供しますが、要素自体を置き換えることなく挑戦をもたらすことができます。 element? element.addeventlistener(event、function(){/はここで動作し...プログラミング 2025-07-15に投稿されました
-
Microsoft Visual C ++が2フェーズテンプレートのインスタンス化を正しく実装できないのはなぜですか?Microsoft Visual Cの「壊れた」2フェーズテンプレートのインスタンス化の謎 問題声明: ユーザーは、Microsoft Visual C(MSVC)の懸念を表現する一般的な懸念を表明します。メカニズムの特定の側面は、予想どおりに動作できませんか?ただし、このチェックがテンプ...プログラミング 2025-07-15に投稿されました
-
Pandas DataFrame列を日付ごとにデータフレーム形式とフィルターに変換するにはどうすればよいですか?パンダのデータフレーム列をdatetime形式に変換 シナリオ: データは、ストリングを含むさまざまな形式でしばしば存在します。時間データを操作する場合、タイムスタンプは最初は文字列として表示されますが、正確な分析のためにデータタイム形式に変換する必要があります。この関数は、文字列列の予想...プログラミング 2025-07-15に投稿されました
-
PDOパラメーターを使用してクエリのように正しく使用する方法は?を使用してpdo PDOで同様のクエリを実装しようとすると、以下のクエリのような問題に遭遇する可能性があります: $query = "SELECT * FROM tbl WHERE address LIKE '%?%' OR address LIKE '%?%'";...プログラミング 2025-07-15に投稿されました
-
コンテナ内のdiv用のスムーズな左右のCSSアニメーションを作成する方法は?左右の動きのための一般的なCSSアニメーション この記事では、一般的なCSSアニメーションを作成して、その容器の端に到達する左右に移動することを探ります。このアニメーションは、その未知の長さに関係なく、絶対的なポジショニングで任意のdivに適用できます。これは、100%で、divの左のプロ...プログラミング 2025-07-15に投稿されました
-
AndroidはどのようにPHPサーバーに投稿データを送信しますか?をAndroid に送信します。これは、サーバー側の通信を扱う際の一般的なシナリオです。 apache httpclient(deprecated) httpclient httpclient = new defulthttpclient(); httppost httppost ...プログラミング 2025-07-15に投稿されました















中国語を勉強する
- 1 「歩く」は中国語で何と言いますか? 走路 中国語の発音、走路 中国語学習
- 2 「飛行機に乗る」は中国語で何と言いますか? 坐飞机 中国語の発音、坐飞机 中国語学習
- 3 「電車に乗る」は中国語で何と言いますか? 坐火车 中国語の発音、坐火车 中国語学習
- 4 「バスに乗る」は中国語で何と言いますか? 坐车 中国語の発音、坐车 中国語学習
- 5 中国語でドライブは何と言うでしょう? 开车 中国語の発音、开车 中国語学習
- 6 水泳は中国語で何と言うでしょう? 游泳 中国語の発音、游泳 中国語学習
- 7 中国語で自転車に乗るってなんて言うの? 骑自行车 中国語の発音、骑自行车 中国語学習
- 8 中国語で挨拶はなんて言うの? 你好中国語の発音、你好中国語学習
- 9 中国語でありがとうってなんて言うの? 谢谢中国語の発音、谢谢中国語学習
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









