 मुखपृष्ठ > प्रोग्रामिंग > PyMuPDFM और उसके मूल्यांकन का उपयोग करके PDF को मार्कडाउन में कैसे परिवर्तित करें
मुखपृष्ठ > प्रोग्रामिंग > PyMuPDFM और उसके मूल्यांकन का उपयोग करके PDF को मार्कडाउन में कैसे परिवर्तित करें
PyMuPDFM और उसके मूल्यांकन का उपयोग करके PDF को मार्कडाउन में कैसे परिवर्तित करें
 ब्राउज़ करें:629
ब्राउज़ करें:629
PyMuPDF4LLM एक लाइब्रेरी है जिसे पीडीएफ को मार्कडाउन प्रारूप में परिवर्तित करने के लिए डिज़ाइन किया गया है। यहां, मैं इस लाइब्रेरी का परीक्षण करने का अपना अनुभव साझा करूंगा।
इंस्टालेशन
निम्न आदेश का उपयोग करके लाइब्रेरी स्थापित करके प्रारंभ करें:
pip install pymupdf4llm
प्रयोग
मूल उपयोग काफी सरल है, पीडीएफ को मार्कडाउन में बदलने के लिए कोड की केवल तीन पंक्तियों की आवश्यकता होती है:
import pymupdf4llm
md_text = pymupdf4llm.to_markdown("input.pdf")
print(md_text)
आप सामग्री निकालने के तरीके को समायोजित करने के लिए तर्क निर्दिष्ट कर सकते हैं।
पेज द्वारा टेक्स्ट निकालना
डिफ़ॉल्ट रूप से, संपूर्ण पीडीएफ एक एकल टेक्स्ट आउटपुट में परिवर्तित हो जाता है। हालाँकि, आप page_chunks=True निर्दिष्ट करके पृष्ठ दर पृष्ठ टेक्स्ट निकाल सकते हैं।
md_text = pymupdf4llm.to_markdown("input.pdf", page_chunks=True)
छवियाँ निकालना
छवियों को फ़ाइलों के रूप में निकालने के लिए, write_images=True विकल्प का उपयोग करें:
md_text = pymupdf4llm.to_markdown("input.pdf", write_images=True)
बेस64 एन्कोडिंग का उपयोग करके छवियों को सीधे मार्कडाउन में एम्बेड करना भी संभव है:
md_text = pymupdf4llm.to_markdown("input.pdf", embed_images=True)
रूपांतरण परिणामों का मूल्यांकन
परीक्षण के लिए, विभिन्न मार्कडाउन तत्वों के साथ विभिन्न पीडीएफ का उपयोग किया गया था।

शीर्षलेख रूपांतरण
हेडर सही ढंग से मार्कडाउन प्रारूप में परिवर्तित हो गए हैं। यहां परिणाम का एक भाग है:
# Sample Markdown Guide This is a sample markdown file that includes various features for quick reference. ## 1. Headers ... ## 3. Lists
बोल्ड और इटैलिक टेक्स्ट
बोल्ड और इटैलिक फ़ॉर्मेटिंग को भी ठीक से रूपांतरित किया गया है:
**Bold: **Bold Text**** _Italic: *Italic Text*_ **_Bold and Italic: ***Bold and Italic***_**
सूची रूपांतरण
पहले स्तर पर ऑर्डर की गई सूचियां बिना किसी समस्या के परिवर्तित हो जाती हैं, लेकिन नेस्टेड सूचियां और अव्यवस्थित सूचियां सटीक रूप से परिवर्तित नहीं होती हैं।
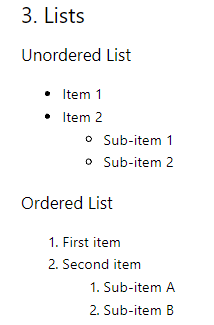
## 3. Lists ### Unordered List Item 1 Item 2 Sub-item 1 Sub-item 2 ### Ordered List 1. First item 2. Second item 1. Sub-item A 2. Sub-item B
लिंक रूपांतरण
लिंक के यूआरएल निकाले जाते हैं, लेकिन लिंक वाली पूरी लाइन मूल प्रारूप से हटकर हाइपरलिंक बन जाती है।
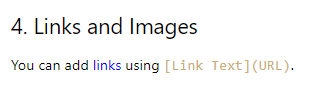
## 4. Links and Images [You can add links using [Link Text](URL).](https://www.example.com/)
छवि निष्कर्षण
छवियां डिफ़ॉल्ट रूप से नहीं निकाली जाती हैं, लेकिन write_images=True के साथ स्थानीय रूप से सहेजी जा सकती हैं।
md_text = pymupdf4llm.to_markdown("input.pdf", write_images=True)
सहेजी गई छवियों को मार्कडाउन में निम्नानुसार संदर्भित किया गया है:
### Image Example

तालिका रूपांतरण
ऊर्ध्वाधर सीमाओं के बिना सरल तालिकाओं को सटीक रूप से परिवर्तित नहीं किया जाता है (संभवतः क्योंकि अस्पष्ट स्तंभ सीमाओं के परिणामस्वरूप तालिकाओं को सादे पाठ के रूप में माना जाता है)।

## 5. Tables
**Column 1** **Column 2** **Column 3**
Row 1 Data A Data B
Row 2 Data C Data D
कोड रूपांतरण
कोड ब्लॉक सही ढंग से परिवर्तित किए गए हैं, लेकिन भाषा विनिर्देश (उदाहरण के लिए, पायथन) बरकरार नहीं रखा गया है। इनलाइन कोड रूपांतरण में भी समस्याएं हैं।

## 6. Code
### Inline Code
Use backticks for inline code: print("Hello, world!")
### Code Block
Use triple backticks for code blocks:
```
def greet(name):
return f"Hello, {name}!"
print(greet("Markdown"))
```
बहु-पंक्ति पाठ
बहु-पंक्ति पाठ के लिए, पंक्ति विराम उसी प्रकार संरक्षित किए जाते हैं जैसे वे मूल पीडीएफ में दिखाई देते हैं।

Markdown is a lightweight and versatile markup language favored by developers, writers, and bloggers alike
due to its simplicity in formatting text, enabling users to create readable and well-structured documents—
whether for documentation, blog posts, or articles—without the complexity of HTML, while also offering the
ability to convert content seamlessly into other formats like HTML, PDF, and even slideshows, making it an
ideal choice for projects that require both clarity and flexibility in presentation.
निष्कर्ष
सूचियों और लिंक को सटीक रूप से परिवर्तित करने में चुनौतियों के बावजूद, PyMuPDF4LLM पीडीएफ को मार्कडाउन में परिवर्तित करने के लिए एक उपयोगी उपकरण है। यह बाहरी भाषा मॉडल की आवश्यकता के बिना स्थानीय रूप से काम कर सकता है, जिससे यह उन वातावरणों के लिए उपयुक्त हो जाता है जहां इंटरनेट पहुंच अनुपलब्ध है।
-
 पायथन मल्टीप्रोसेसिंग पूल में कीबोर्ड इंटरप्ट को खूबसूरती से कैसे संभालें?पायथन मल्टीप्रोसेसिंग पूल में कीबोर्ड इंटरप्ट की शानदार हैंडलिंगपायथन के मल्टीप्रोसेसिंग पूल के साथ काम करते समय, कीबोर्डइंटरप्ट घटनाओं को संभालना हमे...प्रोग्रामिंग 2024-11-08 को प्रकाशित
पायथन मल्टीप्रोसेसिंग पूल में कीबोर्ड इंटरप्ट को खूबसूरती से कैसे संभालें?पायथन मल्टीप्रोसेसिंग पूल में कीबोर्ड इंटरप्ट की शानदार हैंडलिंगपायथन के मल्टीप्रोसेसिंग पूल के साथ काम करते समय, कीबोर्डइंटरप्ट घटनाओं को संभालना हमे...प्रोग्रामिंग 2024-11-08 को प्रकाशित -
वाइट के साथ चरण-दर-चरण सेटअप प्रतिक्रियावाइट एक आधुनिक बिल्ड टूल्स है, जो विशेष रूप से रिएक्ट, व्यू और अन्य जैसे जावास्क्रिप्ट-आधारित अनुप्रयोगों के लिए एक तेज़ और कुशल विकास अनुभव प्रदान कर...प्रोग्रामिंग 2024-11-08 को प्रकाशित
-
जावास्क्रिप्ट में रूपांतरित तत्व की सटीक चौड़ाई और ऊंचाई कैसे प्राप्त करें?परिवर्तन के बाद चौड़ाई और ऊंचाई पुनर्प्राप्त करनाकिसी तत्व पर रोटेट (45 डिग्री) जैसे परिवर्तन को लागू करते समय, उस तत्व के दृश्य आयाम परिवर्तन। हालाँक...प्रोग्रामिंग 2024-11-08 को प्रकाशित
-
पायथन के साथ अटलांटा, जॉर्जिया में अटॉर्नी डेटा को स्क्रैप करने के लिए एक तकनीकी गाइडइस गाइड में, हम अटलांटा, जॉर्जिया में वकीलों पर ध्यान केंद्रित करते हुए, कानूनी वेबसाइटों से वकील डेटा को स्क्रैप करने के लिए पायथन का उपयोग कैसे करें...प्रोग्रामिंग 2024-11-08 को प्रकाशित
-
स्क्रिप्ट टैग में महारत हासिल करना: सटीक स्क्रिप्ट नियंत्रण के लिए Async और Defer का उपयोग करनावेब विकास की दुनिया में, पेज लोड समय को अनुकूलित करना महत्वपूर्ण है। टैग की दो शक्तिशाली विशेषताएँ - async और defer - आपकी वेबसाइट के प्रदर्शन पर महत...प्रोग्रामिंग 2024-11-08 को प्रकाशित
-
जावास्क्रिप्ट में +=_ ऑपरेटर के पीछे का रहस्य क्या है?जावास्क्रिप्ट में रहस्यमय =_ ऑपरेटर को डिकोड करनाजावास्क्रिप्ट में असामान्य ऑपरेटर =_ ने डेवलपर्स को भ्रमित कर दिया है, जिससे वे इसकी वास्तविक प्रकृति...प्रोग्रामिंग 2024-11-08 को प्रकाशित
-
सीएसएस फ्लेक्सबॉक्स: एक मूल्य निर्धारण तालिका बनानापरिचय सीएसएस फ्लेक्सबॉक्स वेब डेवलपर्स के लिए लचीला और उत्तरदायी लेआउट बनाने का एक शक्तिशाली उपकरण है। फ्लेक्सबॉक्स के सबसे आम उपयोग मामलों म...प्रोग्रामिंग 2024-11-08 को प्रकाशित
-
जावास्क्रिप्ट में विशिष्ट दशमलव स्थानों के साथ फ़्लोट्स को कैसे प्रारूपित करें?फ़्लोट्स को विशिष्ट दशमलव स्थानों पर फ़ॉर्मेट करनाजावास्क्रिप्ट में, फ़्लोट से स्ट्रिंग में कनवर्ट करने से दशमलव अंक पीछे आ सकते हैं। दशमलव बिंदु के ब...प्रोग्रामिंग 2024-11-08 को प्रकाशित
-
मैंने Django के लिए पायथन फ्लास्क को क्यों छोड़ दिया: वेब फ्रेमवर्क शोडाउनजब आप पायथन वेब डेवलपमेंट के साथ शुरुआत कर रहे हैं, तो आपको शीर्ष विकल्पों में से दो के रूप में Django और Python फ्लास्क के सामने आने की संभावना है। द...प्रोग्रामिंग 2024-11-08 को प्रकाशित
-
रिएक्ट स्रोत कोड में MessageChannel का उपयोगइस आलेख में, हम रिएक्ट स्रोत कोड में MessageChannel उपयोग का विश्लेषण करते हैं। आइए पहले समझें कि मैसेजचैनल क्या है। संदेशचैनल चैनल मैसेजिंग ए...प्रोग्रामिंग 2024-11-08 को प्रकाशित
-
जावा के लिए इकाई परीक्षण में महारत हासिल करना: 'छात्र वर्ग परीक्षण' परियोजनाLabEx के स्टूडेंट क्लास टेस्ट प्रोजेक्ट के साथ यूनिट टेस्टिंग की दुनिया में उतरकर जावा डेवलपर के रूप में अपनी क्षमता को अनलॉक करें। यह व्यापक पाठ्यक्र...प्रोग्रामिंग 2024-11-08 को प्रकाशित
-
जावास्क्रिप्ट में गुणों के लिए noSuchMethod फ़ीचर का अनुकरण कैसे करें?जावास्क्रिप्ट में गुणों के लिए noSuchMethod फ़ीचर को कैसे कार्यान्वित करेंजावास्क्रिप्ट में, noSuchMethod राइनो और स्पाइडरमंकी जैसे कार्यान्वयन में सु...प्रोग्रामिंग 2024-11-08 को प्रकाशित
-
मेरा GoLang वेबसर्वर बड़े MP4 वीडियो पेश करने में विफल क्यों है?GoLang HTTP वेबसर्वर MP4 वीडियो परोसता हैChallengeGoLang का उपयोग करके एक वेबसर्वर बनाया गया था जो HTML/JS/CSS और छवियों को परोसता है। जब सर्वर ने MP4...प्रोग्रामिंग 2024-11-08 को प्रकाशित
-
HTML फॉर्म का उपयोग किए बिना किसी वेबपेज को रीडायरेक्ट कैसे करें और PHP के साथ POST डेटा कैसे भेजें?PHP के साथ POST डेटा को रीडायरेक्ट करना और भेजनाइस प्रश्न में, हमें एक अनूठी चुनौती का सामना करना पड़ता है: एक वेबपेज को रीडायरेक्ट कैसे करें और इसके ...प्रोग्रामिंग 2024-11-08 को प्रकाशित
-
जेएसएफ फॉर्म सबमिशन के दौरान प्राधिकरण विफलताओं से कैसे निपटें?जेएसएफ फॉर्म सबमिशन के दौरान प्राधिकरण विफलताएं: एक व्यापक विश्लेषणजेएसएफ अनुप्रयोगों में कस्टम प्राधिकरण तंत्र लागू करते समय, पेज नेविगेशन और फॉर्म स...प्रोग्रामिंग 2024-11-08 को प्रकाशित















चीनी भाषा का अध्ययन करें
- 1 आप चीनी भाषा में "चलना" कैसे कहते हैं? #का चीनी उच्चारण, #का चीनी सीखना
- 2 आप चीनी भाषा में "विमान ले लो" कैसे कहते हैं? #का चीनी उच्चारण, #का चीनी सीखना
- 3 आप चीनी भाषा में "ट्रेन ले लो" कैसे कहते हैं? #का चीनी उच्चारण, #का चीनी सीखना
- 4 आप चीनी भाषा में "बस ले लो" कैसे कहते हैं? #का चीनी उच्चारण, #का चीनी सीखना
- 5 चीनी भाषा में ड्राइव को क्या कहते हैं? #का चीनी उच्चारण, #का चीनी सीखना
- 6 तैराकी को चीनी भाषा में क्या कहते हैं? #का चीनी उच्चारण, #का चीनी सीखना
- 7 आप चीनी भाषा में साइकिल चलाने को क्या कहते हैं? #का चीनी उच्चारण, #का चीनी सीखना
- 8 आप चीनी भाषा में नमस्ते कैसे कहते हैं? 你好चीनी उच्चारण, 你好चीनी सीखना
- 9 आप चीनी भाषा में धन्यवाद कैसे कहते हैं? 谢谢चीनी उच्चारण, 谢谢चीनी सीखना
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









