
import streamlit as stimport numpy as npimport pandas as pdimport joblib
stremlit est une bibliothèque Python qui facilite la création et le partage d'applications Web personnalisées pour les projets d'apprentissage automatique et de science des données.
numpy est une bibliothèque Python fondamentale pour le calcul numérique. Il prend en charge de grands tableaux et matrices multidimensionnels, ainsi qu'un ensemble de fonctions mathématiques pour fonctionner efficacement sur ces tableaux.
data = { \\\"island\\\": island, \\\"bill_length_mm\\\": bill_length_mm, \\\"bill_depth_mm\\\": bill_depth_mm, \\\"flipper_length_mm\\\": flipper_length_mm, \\\"body_mass_g\\\": body_mass_g, \\\"sex\\\": sex,}input_df = pd.DataFrame(data, index=[0])encode = [\\\"island\\\", \\\"sex\\\"]input_encoded_df = pd.get_dummies(input_df, prefix=encode)Les valeurs d'entrée sont récupérées à partir du formulaire de saisie créé par Stremlit et les variables catégorielles sont codées en utilisant les mêmes règles que lors de la création du modèle. Notez que l'ordre de chaque donnée doit également être le même que lors de la création du modèle. Si l'ordre est différent, une erreur se produira lors de l'exécution d'une prévision à l'aide du modèle.
clf = joblib.load(\\\"penguin_classifier_model.pkl\\\")
\\\"penguin_classifier_model.pkl\\\" est le fichier dans lequel le modèle précédemment enregistré est stocké. Ce fichier contient un RandomForestClassifier formé au format binaire. L'exécution de ce code charge le modèle dans clf, vous permettant de l'utiliser pour des prédictions et des évaluations sur de nouvelles données.
prediction = clf.predict(input_encoded_df)prediction_proba = clf.predict_proba(input_encoded_df)
clf.predict(input_encoded_df) : utilise le modèle entraîné pour prédire la classe pour les nouvelles données d'entrée codées, en stockant le résultat dans la prédiction.
clf.predict_proba(input_encoded_df) : calcule la probabilité pour chaque classe, en stockant les résultats dans prédiction_proba.
Vous pouvez publier votre application développée sur Internet en accédant au Stremlit Community Cloud (https://streamlit.io/cloud) et en spécifiant l'URL du référentiel GitHub.

Oeuvre de @allison_horst (https://github.com/allisonhorst)
Le modèle est entraîné à l'aide de l'ensemble de données Palmer Penguins, un ensemble de données largement reconnu pour la pratique des techniques d'apprentissage automatique. Cet ensemble de données fournit des informations sur trois espèces de manchots (Adélie, à jugulaire et papou) de l'archipel Palmer en Antarctique. Les principales fonctionnalités incluent :
Cet ensemble de données provient de Kaggle et est accessible ici. La diversité des caractéristiques en fait un excellent choix pour créer un modèle de classification et comprendre l'importance de chaque caractéristique dans la prédiction des espèces.
","image":"http://www.luping.net/uploads/20241006/17282217676702924713227.png","datePublished":"2024-11-02T21:56:21+08:00","dateModified":"2024-11-02T21:56:21+08:00","author":{"@type":"Person","name":"luping.net","url":"https://www.luping.net/articlelist/0_1.html"}} Page de garde > La programmation > Déploiement d'un modèle d'apprentissage automatique en tant qu'application Web à l'aide de Streamlit
Page de garde > La programmation > Déploiement d'un modèle d'apprentissage automatique en tant qu'application Web à l'aide de Streamlit
 Parcourir:215
Parcourir:215
Un modèle d'apprentissage automatique est essentiellement un ensemble de règles ou de mécanismes utilisés pour faire des prédictions ou trouver des modèles dans les données. Pour faire simple (et sans crainte de simplification excessive), une courbe de tendance calculée selon la méthode des moindres carrés dans Excel est aussi un modèle. Cependant, les modèles utilisés dans les applications réelles ne sont pas si simples : ils impliquent souvent des équations et des algorithmes plus complexes, et pas seulement des équations simples.
Dans cet article, je vais commencer par créer un modèle d'apprentissage automatique très simple et le publier sous la forme d'une application Web très simple pour avoir une idée du processus.
Ici, je me concentrerai uniquement sur le processus, pas sur le modèle ML lui-même. J'utiliserai également Streamlit et Streamlit Community Cloud pour publier facilement des applications Web Python.
Grâce à scikit-learn, une bibliothèque Python populaire pour l'apprentissage automatique, vous pouvez rapidement entraîner des données et créer un modèle avec seulement quelques lignes de code pour des tâches simples. Le modèle peut ensuite être enregistré sous forme de fichier réutilisable avec joblib. Ce modèle enregistré peut être importé/chargé comme une bibliothèque Python classique dans une application Web, permettant à l'application de faire des prédictions à l'aide du modèle entraîné !
URL de l'application : https://yh-machine-learning.streamlit.app/
GitHub : https://github.com/yoshan0921/yh-machine-learning.git
Cette application vous permet d'examiner les prédictions faites par un modèle de forêt aléatoire formé sur l'ensemble de données Palmer Penguins. (Voir la fin de cet article pour plus de détails sur les données d'entraînement.)
Plus précisément, le modèle prédit les espèces de manchots en fonction de diverses caractéristiques, notamment l'espèce, l'île, la longueur du bec, la longueur des nageoires, la taille du corps et le sexe. Les utilisateurs peuvent naviguer dans l'application pour voir comment différentes fonctionnalités affectent les prédictions du modèle.
Écran de prédiction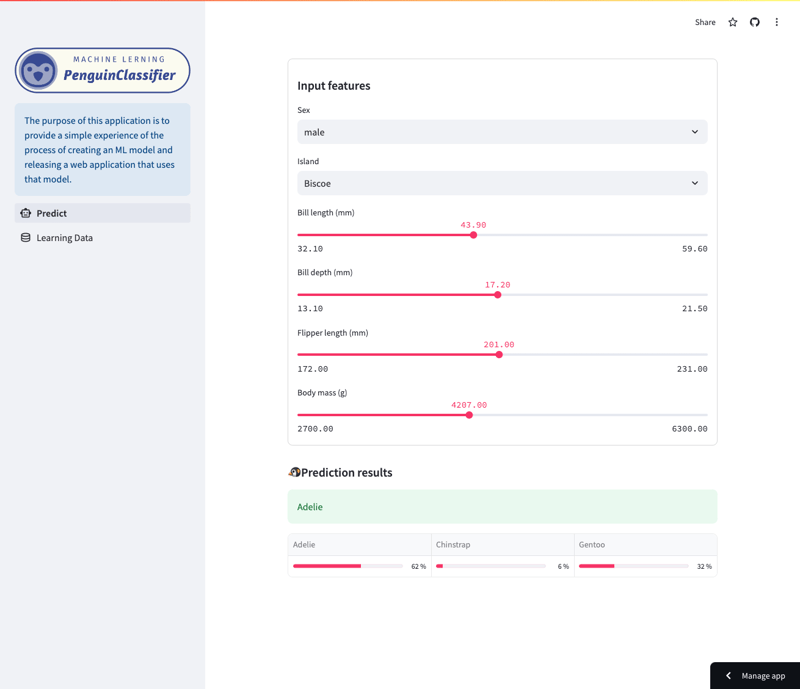
Écran de visualisation/données d'apprentissage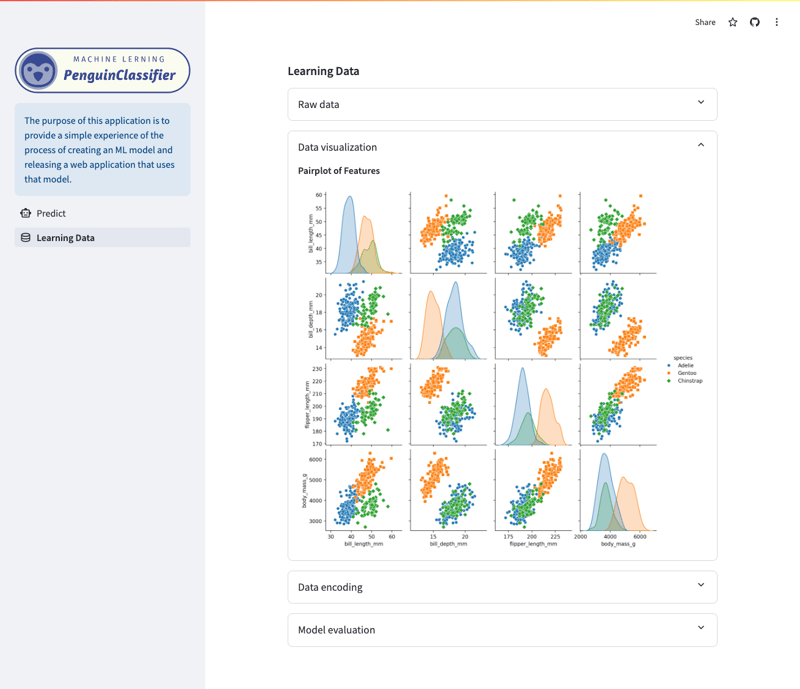
import pandas as pd from sklearn.model_selection import train_test_split from sklearn.ensemble import RandomForestClassifier from sklearn.metrics import accuracy_score import joblib
pandas est une bibliothèque Python spécialisée dans la manipulation et l'analyse de données. Il prend en charge le chargement, le prétraitement et la structuration des données à l'aide de DataFrames, préparant les données pour les modèles d'apprentissage automatique.
sklearn est une bibliothèque Python complète pour l'apprentissage automatique qui fournit des outils de formation et d'évaluation. Dans cet article, je vais construire un modèle en utilisant une méthode d'apprentissage appelée Random Forest.
joblib est une bibliothèque Python qui permet d'enregistrer et de charger des objets Python, comme des modèles d'apprentissage automatique, de manière très efficace.
df = pd.read_csv("./dataset/penguins_cleaned.csv")
X_raw = df.drop("species", axis=1)
y_raw = df.species
Chargez l'ensemble de données (données d'entraînement) et séparez-le en fonctionnalités (X) et variables cibles (y).
encode = ["island", "sex"]
X_encoded = pd.get_dummies(X_raw, columns=encode)
target_mapper = {"Adelie": 0, "Chinstrap": 1, "Gentoo": 2}
y_encoded = y_raw.apply(lambda x: target_mapper[x])
Les variables catégorielles sont converties en un format numérique à l'aide d'un encodage à chaud (X_encoded). Par exemple, si « île » contient les catégories « Biscoe », « Dream » et « Torgersen », une nouvelle colonne est créée pour chacune (island_Biscoe, island_Dream, island_Torgersen). La même chose est faite pour le sexe. Si les données d'origine sont « Biscoe », la colonne island_Biscoe sera définie sur 1 et les autres sur 0.
L'espèce variable cible est mappée à des valeurs numériques (y_encoded).
x_train, x_test, y_train, y_test = train_test_split(
X_encoded, y_encoded, test_size=0.3, random_state=1
)
Pour évaluer un modèle, il est nécessaire de mesurer les performances du modèle sur des données non utilisées pour la formation. Le format 7:3 est largement utilisé comme pratique générale dans l'apprentissage automatique.
clf = RandomForestClassifier() clf.fit(x_train, y_train)
La méthode d'ajustement est utilisée pour entraîner le modèle.
Le x_train représente les données d'entraînement pour les variables explicatives et le y_train représente les variables cibles.
En appelant cette méthode, le modèle entraîné sur la base des données d'entraînement est stocké dans clf.
joblib.dump(clf, "penguin_classifier_model.pkl")
joblib.dump() est une fonction permettant de sauvegarder des objets Python au format binaire. En enregistrant le modèle dans ce format, le modèle peut être chargé à partir d'un fichier et utilisé tel quel sans avoir à être à nouveau entraîné.
import streamlit as st import numpy as np import pandas as pd import joblib
stremlit est une bibliothèque Python qui facilite la création et le partage d'applications Web personnalisées pour les projets d'apprentissage automatique et de science des données.
numpy est une bibliothèque Python fondamentale pour le calcul numérique. Il prend en charge de grands tableaux et matrices multidimensionnels, ainsi qu'un ensemble de fonctions mathématiques pour fonctionner efficacement sur ces tableaux.
data = {
"island": island,
"bill_length_mm": bill_length_mm,
"bill_depth_mm": bill_depth_mm,
"flipper_length_mm": flipper_length_mm,
"body_mass_g": body_mass_g,
"sex": sex,
}
input_df = pd.DataFrame(data, index=[0])
encode = ["island", "sex"]
input_encoded_df = pd.get_dummies(input_df, prefix=encode)
Les valeurs d'entrée sont récupérées à partir du formulaire de saisie créé par Stremlit et les variables catégorielles sont codées en utilisant les mêmes règles que lors de la création du modèle. Notez que l'ordre de chaque donnée doit également être le même que lors de la création du modèle. Si l'ordre est différent, une erreur se produira lors de l'exécution d'une prévision à l'aide du modèle.
clf = joblib.load("penguin_classifier_model.pkl")
"penguin_classifier_model.pkl" est le fichier dans lequel le modèle précédemment enregistré est stocké. Ce fichier contient un RandomForestClassifier formé au format binaire. L'exécution de ce code charge le modèle dans clf, vous permettant de l'utiliser pour des prédictions et des évaluations sur de nouvelles données.
prediction = clf.predict(input_encoded_df) prediction_proba = clf.predict_proba(input_encoded_df)
clf.predict(input_encoded_df) : utilise le modèle entraîné pour prédire la classe pour les nouvelles données d'entrée codées, en stockant le résultat dans la prédiction.
clf.predict_proba(input_encoded_df) : calcule la probabilité pour chaque classe, en stockant les résultats dans prédiction_proba.
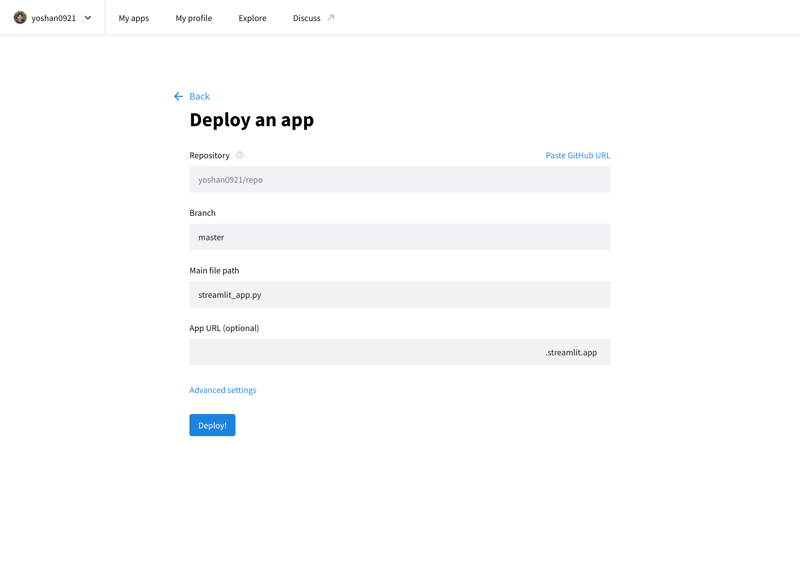
Vous pouvez publier votre application développée sur Internet en accédant au Stremlit Community Cloud (https://streamlit.io/cloud) et en spécifiant l'URL du référentiel GitHub.

Oeuvre de @allison_horst (https://github.com/allisonhorst)
Le modèle est entraîné à l'aide de l'ensemble de données Palmer Penguins, un ensemble de données largement reconnu pour la pratique des techniques d'apprentissage automatique. Cet ensemble de données fournit des informations sur trois espèces de manchots (Adélie, à jugulaire et papou) de l'archipel Palmer en Antarctique. Les principales fonctionnalités incluent :
Cet ensemble de données provient de Kaggle et est accessible ici. La diversité des caractéristiques en fait un excellent choix pour créer un modèle de classification et comprendre l'importance de chaque caractéristique dans la prédiction des espèces.



![[Forfait quotidien] ms](http://www.luping.net/uploads/20241006/17282235656702994dea8b1.jpg)





















Clause de non-responsabilité: Toutes les ressources fournies proviennent en partie d'Internet. En cas de violation de vos droits d'auteur ou d'autres droits et intérêts, veuillez expliquer les raisons détaillées et fournir une preuve du droit d'auteur ou des droits et intérêts, puis l'envoyer à l'adresse e-mail : [email protected]. Nous nous en occuperons pour vous dans les plus brefs délais.
Copyright© 2022 湘ICP备2022001581号-3