 Page de garde > La programmation > Extraire des données de PDF délicats avec Google Gemini en lignes de Python
Page de garde > La programmation > Extraire des données de PDF délicats avec Google Gemini en lignes de Python
Extraire des données de PDF délicats avec Google Gemini en lignes de Python
 Parcourir:619
Parcourir:619
Dans ce guide, je vais vous montrer comment extraire des données structurées à partir de PDF à l'aide de modèles de langage de vision (VLM) comme Gemini Flash ou GPT-4o.
Gemini, la dernière série de modèles de langage visuel de Google, a démontré des performances de pointe en matière de compréhension de textes et d'images. Cette capacité multimodale améliorée et cette longue fenêtre contextuelle le rendent particulièrement utile pour le traitement de données PDF visuellement complexes avec lesquelles les modèles d'extraction traditionnels ont du mal, telles que des figures, des graphiques, des tableaux et des diagrammes.
Ce faisant, vous pouvez facilement créer votre propre outil d'extraction de données pour l'extraction visuelle de fichiers et Web. Voici comment procéder :
La longue fenêtre contextuelle et la capacité multimodale de Gemini le rendent particulièrement utile pour le traitement de données PDF visuellement complexes là où les modèles d'extraction traditionnels ont du mal.
Configuration de votre environnement
Avant de nous lancer dans l'extraction, configurons notre environnement de développement. Ce guide suppose que Python est installé sur votre système. Sinon, téléchargez-le et installez-le depuis https://www.python.org/downloads/
⚠️ Notez que si vous ne souhaitez pas utiliser Python, vous pouvez utiliser la plateforme cloud sur thepi.pe pour télécharger vos fichiers et télécharger votre résultat au format CSV sans écrire de code.
Installer les bibliothèques requises
Ouvrez votre terminal ou votre invite de commande et exécutez les commandes suivantes :
pip install git https://github.com/emcf/thepipe pip install pandas
Pour ceux qui découvrent Python, pip est le programme d'installation du package pour Python, et ces commandes téléchargeront et installeront les bibliothèques nécessaires.
Configurez votre clé API
Pour utiliser thepipe, vous avez besoin d'une clé API.
Avertissement : bien que thepi.pe soit un outil open source gratuit, l'API a un coût d'environ 0,00002 $ par jeton. Si vous souhaitez éviter de tels coûts, consultez les instructions de configuration locale sur GitHub. Notez que vous devrez toujours payer le prestataire LLM de votre choix.
Voici comment l'obtenir et le configurer :
- Visitez https://thepi.pe/platform/
- Créez un compte ou connectez-vous
- Trouvez votre clé API dans la page des paramètres

Maintenant, vous devez définir ceci comme variable d'environnement. Le processus varie en fonction de votre système d'exploitation :
- Copiez la clé API depuis le menu des paramètres sur la plateforme thepi.pe
Pour Windows :
- Recherchez « Variables d'environnement » dans le menu Démarrer
- Cliquez sur "Modifier les variables d'environnement système"
- Cliquez sur le bouton "Variables d'environnement"
- Sous "Variables utilisateur", cliquez sur "Nouveau"
- Définissez le nom de la variable comme THEPIPE_API_KEY et la valeur comme votre clé API
- Cliquez sur "OK" pour enregistrer
Pour macOS et Linux :
Ouvrez votre terminal et ajoutez cette ligne à votre fichier de configuration shell (par exemple, ~/.bashrc ou ~/.zshrc) :
export THEPIPE_API_KEY=your_api_key_here
Puis rechargez votre configuration :
source ~/.bashrc # or ~/.zshrc
Définir votre schéma d'extraction
La clé d'une extraction réussie consiste à définir un schéma clair pour les données que vous souhaitez extraire. Supposons que nous extrayons des données d'un document de facturation :

Un exemple de page du document Devis quantitatif. Les données de chaque page sont indépendantes des autres pages, nous effectuons donc notre extraction "par page". Il y a plusieurs éléments de données à extraire par page, nous définissons donc plusieurs extractions sur True
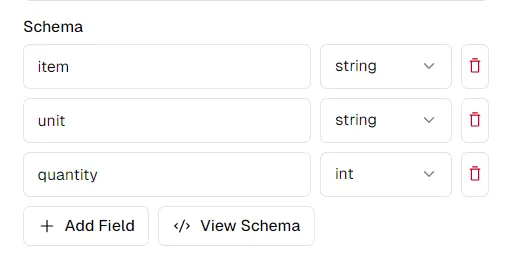
En regardant les noms de colonnes, nous pourrions vouloir extraire un schéma comme celui-ci :
schema = {
"item": "string",
"unit": "string",
"quantity": "int",
}
Vous pouvez modifier le schéma à votre guise sur la plateforme thepi.pe. En cliquant sur "Afficher le schéma", vous obtiendrez un schéma que vous pourrez copier et coller pour l'utiliser avec l'API Python
Extraction de données à partir de PDF
Utilisons maintenant extract_from_file pour extraire les données d'un PDF :
from thepipe.extract import extract_from_file results = extract_from_file( file_path = "bill_of_quantity.pdf", schema = schema, ai_model = "google/gemini-flash-1.5b", chunking_method = "chunk_by_page" )
Ici, nous avons chunking_method="chunk_by_page" car nous voulons envoyer chaque page au modèle d'IA individuellement (le PDF est trop volumineux pour être alimenté en une seule fois). Nous définissons également multiple_extractions=True car les pages PDF contiennent chacune plusieurs lignes de données. Voici à quoi ressemble une page du PDF :
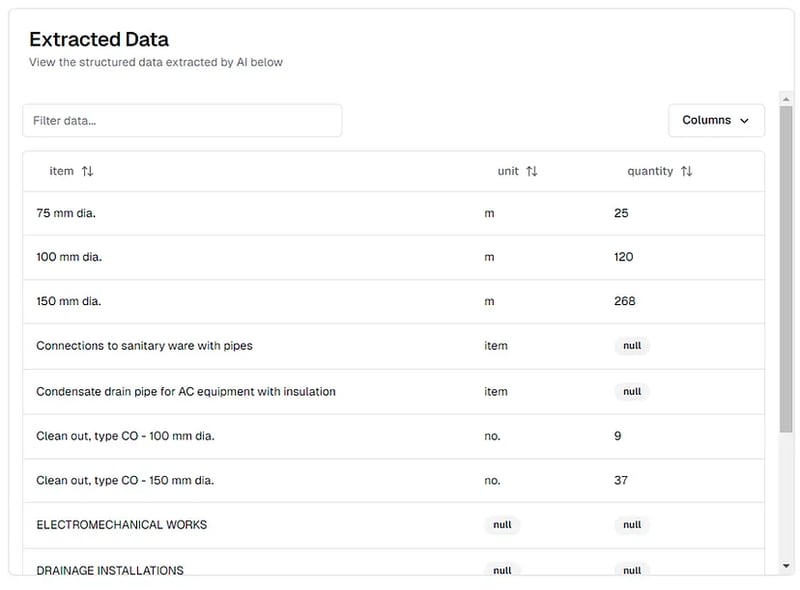
Les résultats de l'extraction du PDF de la facture quantitative tels que consultés sur la plateforme pi.pe
Traitement des résultats
Les résultats de l'extraction sont renvoyés sous forme de liste de dictionnaires. Nous pouvons traiter ces résultats pour créer un DataFrame pandas :
import pandas as pd df = pd.DataFrame(results) # Display the first few rows of the DataFrame print(df.head())
Cela crée un DataFrame avec toutes les informations extraites, y compris le contenu textuel et les descriptions d'éléments visuels tels que les figures et les tableaux.
Exportation vers différents formats
Maintenant que nous avons nos données dans un DataFrame, nous pouvons facilement les exporter vers différents formats. Voici quelques options :
Exportation vers Excel
df.to_excel("extracted_research_data.xlsx", index=False, sheet_name="Research Data")
Cela crée un fichier Excel nommé « extracted_research_data.xlsx » avec une feuille nommée « Research Data ». Le paramètre index=False empêche l'index DataFrame d'être inclus en tant que colonne distincte.
Exportation au format CSV
Si vous préférez un format plus simple, vous pouvez exporter au format CSV :
df.to_csv("extracted_research_data.csv", index=False)
Cela crée un fichier CSV qui peut être ouvert dans Excel ou dans n'importe quel éditeur de texte.
Notes de fin
La clé d'une extraction réussie réside dans la définition d'un schéma clair et l'utilisation des capacités multimodales du modèle d'IA. À mesure que vous vous familiariserez avec ces techniques, vous pourrez explorer des fonctionnalités plus avancées telles que des méthodes de segmentation personnalisées, des invites d'extraction personnalisées et l'intégration du processus d'extraction dans des pipelines de données plus vastes.
-
 Comment puis-je sélectionner par programmation tout le texte dans un clic div sur la souris?Sélection du texte div sur la souris Cliquez sur Question Étant donné un élément div avec du contenu de texte, comment l'utilisateur peut-...La programmation Publié le 2025-07-13
Comment puis-je sélectionner par programmation tout le texte dans un clic div sur la souris?Sélection du texte div sur la souris Cliquez sur Question Étant donné un élément div avec du contenu de texte, comment l'utilisateur peut-...La programmation Publié le 2025-07-13 -
Comment modifier efficacement l'attribut CSS du ": après" pseudo-élément utilisant jQuery?Comprendre les limites des pseudo-éléments dans jQuery: accéder au ": après" sélecteur dans le développement Web, des pseudo-élément...La programmation Publié le 2025-07-13
-
CSS peut-il localiser les éléments HTML basés sur une valeur d'attribut?ciblant les éléments HTML avec n'importe quelle valeur d'attribut dans CSS Dans CSS, il est possible de cibler les éléments basés sur ...La programmation Publié le 2025-07-13
-
Pourquoi y a-t-il des rayures dans mon fond de dégradé linéaire, et comment puis-je les réparer?bannissant les bandes d'arrière-plan à partir du gradient linéaire Lorsque vous utilisez la propriété linéaire-gradient pour un arrière-pl...La programmation Publié le 2025-07-13
-
Comment extraire du texte entre parenthèses efficacement en PHP en utilisant Regexphp: extraire du texte dans les parenthèses de manière optimale lors de l'extraction de texte enfermé entre parenthèses, il est essentiel ...La programmation Publié le 2025-07-13
-
Guide pour résoudre les problèmes CORS dans Spring Security 4.1 et plusSpring Security Cors Filter: dépannage des problèmes communs Lors de l'intégration de Spring Security dans un projet existant, vous pouvez...La programmation Publié le 2025-07-13
-
Pourquoi la demande de postn \ 'ne capture-t-elle pas d'entrée en PHP malgré le code valide?Adresses du post Demande Dysfonctionnement en php Dans l'extrait de code présenté: "Méthode =" post "> " ...La programmation Publié le 2025-07-13
-
Méthode pour convertir correctement les caractères Latin1 en UTF8 dans UTF8 MySQL TableConvertir les caractères latins1 dans une table utf8 en utf8 Vous avez rencontré un problème où les caractères avec diacritique (par exemple, ...La programmation Publié le 2025-07-13
-
Comment définir dynamiquement les touches dans les objets JavaScript?Comment créer une clé dynamique pour une variable d'objet JavaScript lorsque vous essayez de créer une clé dynamique pour un objet JavaScrip...La programmation Publié le 2025-07-13
-
Guide de création de pages Fastapi Custom 404 PagePage personnalisée 404 non trouvé avec fastapi Pour créer une page 404 personnalisée, Fastapi propose plusieurs approches. La méthode appropri...La programmation Publié le 2025-07-13
-
Comment pouvez-vous définir les variables dans les modèles de lame Laravel avec élégance?Définition des variables dans les modèles de lame Laravel avec élégance Comprendre comment attribuer des variables dans les modèles de lame es...La programmation Publié le 2025-07-13
-
Python Lire le fichier CSV UnicodedeCodeerror Ultimate SolutionUnicode Decode Erreur dans la lecture du fichier CSV Lorsque vous essayez de lire un fichier CSV dans Python à l'aide du module CSV intégr...La programmation Publié le 2025-07-13
-
Puis-je migrer mon cryptage de McRypt à OpenSSL et décrypter les données cryptées McRypt à l'aide d'OpenSSL?Mise à niveau de ma bibliothèque de chiffrement de McRypt à OpenSSL Puis-je mettre à niveau ma bibliothèque de cryptage à partir de McRypt à O...La programmation Publié le 2025-07-13
-
Comment afficher correctement la date et l'heure actuelles dans le format "DD / MM / YYYY HH: MM: SS.SS" en Java?Comment afficher la date et l'heure actuelles dans "dd / mm / yyyy hh: mm: ss.ss" format dans le code java fourni, le problème a...La programmation Publié le 2025-07-13
-
Comment implémenter des événements personnalisés en utilisant le modèle d'observateur en Java?Création d'événements personnalisés dans java Les événements personnalisés sont indispensables dans de nombreux scénarios de programmation, ...La programmation Publié le 2025-07-13















Étudier le chinois
- 1 Comment dit-on « marcher » en chinois ? 走路 Prononciation chinoise, 走路 Apprentissage du chinois
- 2 Comment dit-on « prendre l’avion » en chinois ? 坐飞机 Prononciation chinoise, 坐飞机 Apprentissage du chinois
- 3 Comment dit-on « prendre un train » en chinois ? 坐火车 Prononciation chinoise, 坐火车 Apprentissage du chinois
- 4 Comment dit-on « prendre un bus » en chinois ? 坐车 Prononciation chinoise, 坐车 Apprentissage du chinois
- 5 Comment dire conduire en chinois? 开车 Prononciation chinoise, 开车 Apprentissage du chinois
- 6 Comment dit-on nager en chinois ? 游泳 Prononciation chinoise, 游泳 Apprentissage du chinois
- 7 Comment dit-on faire du vélo en chinois ? 骑自行车 Prononciation chinoise, 骑自行车 Apprentissage du chinois
- 8 Comment dit-on bonjour en chinois ? 你好Prononciation chinoise, 你好Apprentissage du chinois
- 9 Comment dit-on merci en chinois ? 谢谢Prononciation chinoise, 谢谢Apprentissage du chinois
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









