 Page de garde > La programmation > Entropix : techniques d'échantillonnage pour maximiser les performances d'inférence
Page de garde > La programmation > Entropix : techniques d'échantillonnage pour maximiser les performances d'inférence
Entropix : techniques d'échantillonnage pour maximiser les performances d'inférence
 Parcourir:403
Parcourir:403
Entropix : techniques d'échantillonnage pour maximiser les performances d'inférence
Selon le fichier README d'Entropix, Entropix utilise une méthode d'échantillonnage basée sur l'entropie. Cet article explique les techniques d'échantillonnage spécifiques basées sur l'entropie et la varentropie.
Entropie et Varentropie
Commençons par expliquer l'entropie et la varentropie, car ce sont des facteurs clés pour déterminer la stratégie d'échantillonnage.
Entropie
En théorie de l'information, l'entropie est une mesure de l'incertitude d'une variable aléatoire. L'entropie d'une variable aléatoire X est définie par l'équation suivante :
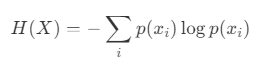
- X : une variable aléatoire discrète.
- x_i : Le i-ème état possible de X.
- p(x_i) : la probabilité de l'état x_i.
L'entropie est maximisée lorsque la distribution de probabilité est uniforme. À l’inverse, lorsqu’un état spécifique est beaucoup plus probable que d’autres, l’entropie diminue.
Varentropie
La varentropie, étroitement liée à l'entropie, représente la variabilité du contenu de l'information. Compte tenu du contenu informationnel I(X), de l'entropie H(X) et de la variance pour une variable aléatoire X, la varentropie V E(X) est définie comme suit :
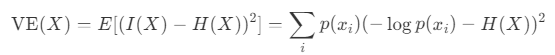
La varentropie devient grande lorsque les probabilités p(x_i) varient considérablement. Il devient petit lorsque les probabilités sont uniformes, soit lorsque la distribution a une entropie maximale, soit lorsqu'une valeur a une probabilité de 1 et que toutes les autres ont une probabilité de 0.
Méthodes d'échantillonnage
Ensuite, explorons comment les stratégies d'échantillonnage changent en fonction des valeurs d'entropie et de varentropie.
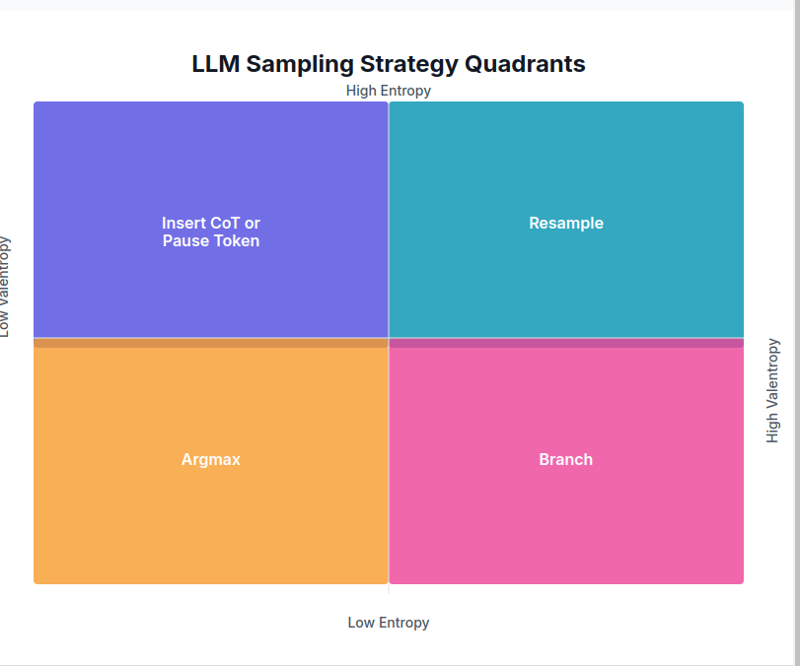
1. Faible entropie, faible varentropie → Argmax
Dans ce scénario, un jeton particulier a une probabilité de prédiction beaucoup plus élevée que les autres. Puisque le prochain jeton est presque certain, Argmax est utilisé.
if entLien de code
2. Faible entropie, varentropie élevée → Branche
Cela se produit lorsqu'il existe une certaine confiance, mais que plusieurs options viables existent. Dans ce cas, la stratégie Branche est utilisée pour échantillonner parmi plusieurs choix et sélectionner le meilleur résultat.
elif ent 5.0: temp_adj = 1.2 0.3 * interaction_strength top_k_adj = max(5, int(top_k * (1 0.5 * (1 - agreement)))) return _sample(logits, temperature=min(1.5, temperature * temp_adj), top_p=top_p, top_k=top_k_adj, min_p=min_p, generator=generator)Lien de code
Bien que cette stratégie soit appelée « Branche », le code actuel semble ajuster la plage d'échantillonnage et sélectionner un seul chemin. (Si quelqu'un a plus d'informations, des éclaircissements supplémentaires seraient appréciés.)
3. Entropie élevée, varentropie faible → CoT ou insérer un jeton de pause
Lorsque les probabilités de prédiction du jeton suivant sont assez uniformes, indiquant que le contexte suivant n'est pas certain, un jeton de clarification est inséré pour résoudre l'ambiguïté.
elif ent > 3.0 and ventLien de code
4. Haute entropie, haute varentropie → Rééchantillonner
Dans ce cas, il existe plusieurs contextes et les probabilités de prédiction du prochain jeton sont faibles. Une stratégie de rééchantillonnage est utilisée avec un réglage de température plus élevé et un top-p plus bas.
elif ent > 5.0 and vent > 5.0: temp_adj = 2.0 0.5 * attn_vent top_p_adj = max(0.5, top_p - 0.2 * attn_ent) return _sample(logits, temperature=max(2.0, temperature * temp_adj), top_p=top_p_adj, top_k=top_k, min_p=min_p, generator=generator)Lien de code
Cas intermédiaires
Si aucune des conditions ci-dessus n'est remplie, un échantillonnage adaptatif est effectué. Plusieurs échantillons sont prélevés et le meilleur score d'échantillonnage est calculé en fonction des informations d'entropie, de varentropie et d'attention.
else: return adaptive_sample( logits, metrics, gen_tokens, n_samples=5, base_temp=temperature, base_top_p=top_p, base_top_k=top_k, generator=generator )Lien de code
Références
- Référentiel Entropix
- Que fait Entropix ?
-
 FIT OBJET: la couverture échoue dans IE et Edge, comment réparer?objet-fit: la couverture échoue dans IE et Edge, comment corriger? Utilisation d'objet-fit: couverture; Dans CSS pour maintenir la hauteur...La programmation Publié le 2025-03-10
FIT OBJET: la couverture échoue dans IE et Edge, comment réparer?objet-fit: la couverture échoue dans IE et Edge, comment corriger? Utilisation d'objet-fit: couverture; Dans CSS pour maintenir la hauteur...La programmation Publié le 2025-03-10 -
Comment puis-je récupérer efficacement les valeurs d'attribut à partir de fichiers XML à l'aide de PHP?Récupération des valeurs d'attribut à partir de fichiers xml dans php Chaque développeur rencontre la nécessité de analyser les fichiers X...La programmation Publié le 2025-03-10
-
Comment limiter la plage de défilement d'un élément dans un élément parent de taille dynamique?Implémentation de limites de hauteur CSS pour les éléments de défilement vertical dans une interface interactive, le contrôle du comportement ...La programmation Publié le 2025-03-10
-
Plusieurs éléments collants peuvent-ils être empilés les uns sur les autres en CSS pur?Est-il possible d'avoir plusieurs éléments collants empilés les uns sur les autres en pur css? Le comportement souhaité peut être vu Ici:...La programmation Publié le 2025-03-10
-
Anomalies de valeur clé du tableau PHP: Comprendre le cas curieux de 07 et 08Problème de valeur de clé du tableau php avec 07 & 08 Un tableau contient divers éléments avec des touches associées. Dans PHP, un problème in...La programmation Publié le 2025-03-10
-
Comment extraire un élément aléatoire d'un tableau en PHP?sélection aléatoire à partir d'un tableau en php, l'obtention d'un élément aléatoire à partir d'un tableau peut être accompli av...La programmation Publié le 2025-03-10
-
Pourquoi mon image d'arrière-plan CSS apparaît-elle?Troubleshoot: Image d'arrière-plan CSS n'apparaissant pas Vous avez rencontré un problème où votre image d'arrière-plan échoue mal...La programmation Publié le 2025-03-10
-
Pourquoi Pytz montre-t-il des décalages de fuseau horaire inattendus initialement?Dicontenance du fuseau horaire avec pytz Certains flammes de temps présentent des décalages particuliers lorsqu'ils sont initialement obte...La programmation Publié le 2025-03-10
-
Pourquoi la demande de postn \ 'ne capture-t-elle pas d'entrée en PHP malgré le code valide?Adresses du post Demande Dysfonctionnement en php Dans l'extrait de code présenté: "Méthode =" post "> " ...La programmation Publié le 2025-03-10
-
Pourquoi les images affichent-elles des images à l'aide de la propriété CSS «Content»?Affichage des images avec URL de contenu dans Firefox Un problème a été rencontré lorsque certains navigateurs, spécifiquement Firefox, n'...La programmation Publié le 2025-03-10
-
Comment vérifier si un objet a un attribut spécifique dans Python?Méthode pour déterminer l'existence de l'attribut d'objet Cette enquête cherche une méthode pour vérifier la présence d'un att...La programmation Publié le 2025-03-10
-
Y a-t-il une différence de performance entre l'utilisation d'une boucle for-out et un itérateur pour la traversée de collecte en Java?pour chaque boucle vs iterator: efficacité dans la collection Traversal introduction Lorsque vous traversez une collection dans Java, le c...La programmation Publié le 2025-03-10
-
Comment surmonter les restrictions de redéfinition de la fonction de PHP?surmonter les limitations de redéfinition de la fonction de Php dans php, définir une fonction avec le même nom plusieurs fois est un non. Ten...La programmation Publié le 2025-03-10
-
Pourquoi est-ce que je reçois MySQL Error # 1089: clé de préfixe incorrect?MySql Error # 1089: Key de préfixe incorrect Les utilisateurs de MySQL peuvent rencontrer du code d'erreur # 1089, indiquant une utilisati...La programmation Publié le 2025-03-10
-
Comment pouvez-vous utiliser des données de groupe par pour pivoter dans MySQL?Pivoting des résultats de la requête en utilisant le groupe mysql par Dans une base de données relationnelle, les données pivotant se réfèrent...La programmation Publié le 2025-03-10















Étudier le chinois
- 1 Comment dit-on « marcher » en chinois ? 走路 Prononciation chinoise, 走路 Apprentissage du chinois
- 2 Comment dit-on « prendre l’avion » en chinois ? 坐飞机 Prononciation chinoise, 坐飞机 Apprentissage du chinois
- 3 Comment dit-on « prendre un train » en chinois ? 坐火车 Prononciation chinoise, 坐火车 Apprentissage du chinois
- 4 Comment dit-on « prendre un bus » en chinois ? 坐车 Prononciation chinoise, 坐车 Apprentissage du chinois
- 5 Comment dire conduire en chinois? 开车 Prononciation chinoise, 开车 Apprentissage du chinois
- 6 Comment dit-on nager en chinois ? 游泳 Prononciation chinoise, 游泳 Apprentissage du chinois
- 7 Comment dit-on faire du vélo en chinois ? 骑自行车 Prononciation chinoise, 骑自行车 Apprentissage du chinois
- 8 Comment dit-on bonjour en chinois ? 你好Prononciation chinoise, 你好Apprentissage du chinois
- 9 Comment dit-on merci en chinois ? 谢谢Prononciation chinoise, 谢谢Apprentissage du chinois
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









