
Comment l'optimisation des comparaisons accélère le tri Python
 Parcourir:916
Parcourir:916
Dans ce texte les termes Python et CPython, qui est l'implémentation de référence du langage, sont utilisés de manière interchangeable. Cet article concerne spécifiquement CPython et ne concerne aucune autre implémentation de Python.
Python est un langage magnifique qui permet à un programmeur d'exprimer ses idées en termes simples, laissant la complexité de la mise en œuvre réelle dans les coulisses.
L'une des choses qu'il résume est le tri.
Vous pouvez facilement trouver la réponse à la question « comment le tri est implémenté en Python ? » ce qui répond presque toujours à une autre question : « Quel algorithme de tri Python utilise-t-il ?
Cependant, cela laisse souvent derrière lui quelques détails d'implémentation intéressants.
Il y a un détail d'implémentation qui, à mon avis, n'est pas suffisamment discuté, même s'il a été introduit il y a plus de sept ans dans python 3.7 :
sorted() et list.sort() ont été optimisés pour les cas courants afin d'être jusqu'à 40 à 75 % plus rapides. (Contribution d'Elliot Gorokhovsky dans bpo-28685.)
Mais avant de commencer...
Brève réintroduction au tri en Python
Lorsque vous devez trier une liste en python, vous avez deux options :
- Une méthode de liste : list.sort(*, key=None, reverse=False), qui trie la liste donnée sur place
- Une fonction intégrée : sorted(iterable, /, *, key=None, reverse= False), qui renvoie une liste triée sans modifier son argument
Si vous devez trier un autre itérable intégré, vous ne pouvez utiliser sorted que quel que soit le type d'itérable ou de générateur passé en paramètre.
sorted renvoie toujours une liste car il utilise list.sort en interne.
Voici un équivalent approximatif de l'implémentation C triée de CPython réécrite en python pur :
def sorted(iterable: Iterable[Any], key=None, reverse=False):
new_list = list(iterable)
new_list.sort(key=key, reverse=reverse)
return new_list
Oui, c'est aussi simple que cela.
Comment Python accélère le tri
Comme le dit la documentation interne de Python pour le tri :
Il est parfois possible de remplacer des comparaisons spécifiques à un type plus rapides par le PyObject_RichCompareBool générique plus lent
Et en bref cette optimisation peut être décrite ainsi :
Lorsqu'une liste est homogène, Python utilise fonction de comparaison spécifique au type
Qu'est-ce qu'une liste homogène ?
Une liste homogène est une liste qui contient des éléments d'un seul type.
Par exemple:
homogeneous = [1, 2, 3, 4]
En revanche, il ne s'agit pas d'une liste homogène :
heterogeneous = [1, "2", (3, ), {'4': 4}]
Fait intéressant, le didacticiel officiel de Python indique :
Les listes sont mutables et leurs éléments sont généralement homogènes et sont accessibles en itérant sur la liste
Une remarque sur les tuples
Ce même tutoriel indique :
Les tuples sont immuables et contiennent généralement une séquence hétérogène d'éléments
Donc, si jamais vous vous demandez quand utiliser un tuple ou une liste, voici une règle générale :
si les éléments sont du même type, utilisez une liste, sinon utilisez un tuple
Attendez, et qu'en est-il des tableaux ?
Python implémente un objet conteneur de tableau homogène pour les valeurs numériques.
Cependant, depuis Python 3.12, les tableaux n'implémentent pas leur propre méthode de tri.
La seule façon de les trier est d'utiliser sorted, qui crée en interne une liste à partir du tableau, effaçant ainsi toutes les informations liées au type.
Pourquoi utiliser la fonction de comparaison spécifique au type est-il utile ?
Les comparaisons en python sont coûteuses, car Python effectue diverses vérifications avant d'effectuer une comparaison réelle.
Voici une explication simplifiée de ce qui se passe sous le capot lorsque vous comparez deux valeurs en python :
- Python vérifie que les valeurs transmises à la fonction de comparaison ne sont pas NULL
- Si les valeurs sont de types différents, mais que l'opérande droit est un sous-type de celui de gauche, Python utilise la fonction de comparaison de l'opérande droit, mais inversée (par exemple, il utilisera )
- Si les valeurs sont du même type ou de types différents mais qu'aucune des deux n'est un sous-type de l'autre :
- Python va d'abord essayer la fonction de comparaison de l'opérande gauche
- Si cela échoue, il essaiera la fonction de comparaison de l'opérande droit, mais inversée.
- Si cela échoue également et que la comparaison concerne l'égalité ou l'inégalité, elle renverra une comparaison d'identité (Vrai pour les valeurs qui font référence au même objet en mémoire)
- Sinon, cela génère TypeError
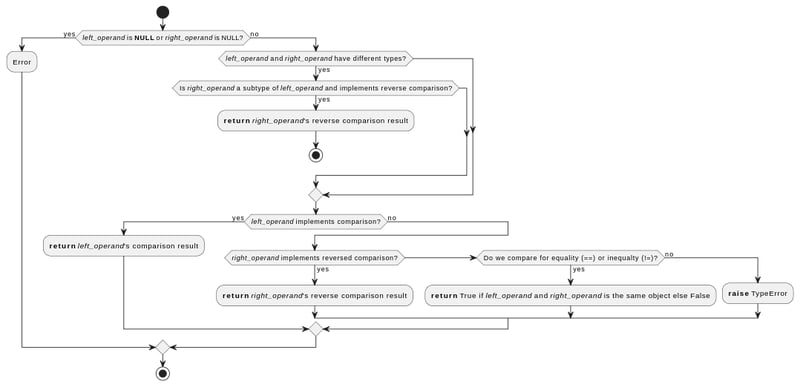
En plus de cela, les fonctions de comparaison propres à chaque type implémentent des vérifications supplémentaires.
Par exemple, lors de la comparaison de chaînes, Python vérifiera si les caractères de la chaîne occupent plus d'un octet de mémoire, et la comparaison float comparera différemment une paire de float, un float et un int.
Une explication et un diagramme plus détaillés peuvent être trouvés ici : Ajout d'optimisations de tri basées sur les données à CPython
Avant l'introduction de cette optimisation, Python devait exécuter toutes ces vérifications spécifiques au type et non spécifiques au type chaque fois que deux valeurs étaient comparées lors du tri.
Vérification des types d'éléments de liste à l'avance
Il n'y a pas de moyen magique de savoir si tous les éléments d'une liste sont du même type, si ce n'est de parcourir la liste et de vérifier chaque élément.
Python fait presque exactement cela : vérifier les types de clés de tri générées par la fonction clé transmise à list.sort ou triées en tant que paramètre
Construire une liste de clés
Si une fonction clé est fournie, Python l'utilise pour construire une liste de clés, sinon il utilise les propres valeurs de la liste comme clés de tri.
De manière simplifiée à l'extrême, la construction des clés peut être exprimée comme le code python suivant.
if key is None:
keys = list_items
else:
keys = [key(list_item) for list_item in list_item]
Notez que les clés utilisées en interne dans CPython sont un tableau C de références d'objets CPython, et non une liste Python
Une fois les clés construites, Python vérifie leurs types.
Vérification du type de clé
Lors de la vérification des types de clés, l'algorithme de tri de Python tente de déterminer si tous les éléments du tableau de clés sont soit str, int, float ou tuple, ou simplement du même type, avec quelques contraintes pour les types de base.
Il convient de noter que la vérification des types de clés ajoute un travail supplémentaire au départ. Python fait cela parce que cela s'avère généralement rentable en rendant le tri plus rapide, en particulier pour les listes plus longues.
contraintes int
int ne devrait pas être un bignum
En pratique, cela signifie que pour que cette optimisation fonctionne, l'entier doit être inférieur à 2^30 - 1 (cela peut varier selon la plateforme)
En remarque, voici un excellent article qui explique comment Python gère les gros entiers : # Comment Python implémente les entiers super longs ?
contraintes str
Tous les caractères d'une chaîne doivent occuper moins d'un octet de mémoire, ce qui signifie qu'ils doivent être représentés par des valeurs entières comprises entre 0 et 255
En pratique, cela signifie que les chaînes ne doivent être constituées que de caractères latins, d'espaces et de certains caractères spéciaux trouvés dans la table ASCII.
contraintes de flottement
Il n'y a aucune contrainte pour les flottants pour que cette optimisation fonctionne.
contraintes de tuple
- Seul le type du premier élément est vérifié
- Cet élément lui-même ne doit pas être un tuple lui-même
- Si tous les tuples partagent le même type pour leur premier élément, l'optimisation de comparaison leur est appliquée
- Tous les autres éléments sont comparés comme d'habitude
Comment puis-je appliquer ces connaissances ?
Tout d’abord, n’est-ce pas passionnant à savoir ?
Deuxièmement, mentionner ces connaissances pourrait être une bonne idée lors d'un entretien avec un développeur Python.
En ce qui concerne le développement réel du code, comprendre cette optimisation peut vous aider à améliorer les performances de tri.
Optimiser en sélectionnant judicieusement le type de valeurs
Selon le benchmark du PR qui a introduit cette optimisation, le tri d'une liste composée uniquement de flottants plutôt que d'une liste de flottants avec ne serait-ce qu'un seul entier à la fin est presque deux fois plus rapide.
Alors, quand il est temps d'optimiser, transformer une liste comme celle-ci
floats_and_int = [1.0, -1.0, -0.5, 3]
Dans une liste qui ressemble à ceci
just_floats = [1.0, -1.0, -0.5, 3.0] # note that 3.0 is a float now
pourrait améliorer les performances.
Optimiser en utilisant des clés pour les listes d'objets
Bien que l'optimisation du tri de Python fonctionne bien avec les types intégrés, il est important de comprendre comment elle interagit avec les classes personnalisées.
Lors du tri des objets de classes personnalisées, Python s'appuie sur les méthodes de comparaison que vous définissez, telles que __lt__ (inférieur à) ou __gt__ (supérieur à).
Cependant, l'optimisation spécifique au type ne s'applique pas aux classes personnalisées.
Python utilisera toujours la méthode de comparaison générale pour ces objets.
Voici un exemple :
class MyClass:
def __init__(self, value):
self.value = value
def __lt__(self, other):
return self.value
Dans ce cas, Python utilisera la méthode __lt__ pour les comparaisons, mais il ne bénéficiera pas de l'optimisation spécifique au type. Le tri fonctionnera toujours correctement, mais il ne sera peut-être pas aussi rapide que le tri des types intégrés.
Si les performances sont essentielles lors du tri des objets personnalisés, envisagez d'utiliser une fonction clé qui renvoie un type intégré :
sorted_list = sorted(my_list, key=lambda x: x.value)
Épilogue
Une optimisation prématurée, en particulier en Python, est mauvaise.
Vous ne devez pas concevoir l'intégralité de votre application autour d'optimisations spécifiques dans CPython, mais il est bon d'être conscient de ces optimisations : bien connaître vos outils est un moyen de devenir un développeur plus compétent.
Être attentif à de telles optimisations vous permet d'en profiter lorsque la situation l'exige, notamment lorsque les performances deviennent critiques :
Considérez un scénario dans lequel votre tri est basé sur des horodatages : l'utilisation d'une liste homogène d'entiers (horodatages Unix) au lieu d'objets datetime pourrait exploiter efficacement cette optimisation.
Cependant, il est crucial de se rappeler que la lisibilité et la maintenabilité du code doivent avoir la priorité sur de telles optimisations.
Bien qu'il soit important de connaître ces détails de bas niveau, il est tout aussi important d'apprécier les abstractions de haut niveau de Python qui en font un langage si productif.
Python est un langage étonnant, et explorer ses profondeurs peut vous aider à mieux le comprendre et à devenir un meilleur programmeur Python.
-
 Comment éviter les fuites de mémoire lors de la tranchage du langage GO?la fuite de la mémoire dans les tranches go Comprendre les fuites de mémoire dans les tranches de go peut être un défi. Cet article vise à app...La programmation Publié le 2025-07-08
Comment éviter les fuites de mémoire lors de la tranchage du langage GO?la fuite de la mémoire dans les tranches go Comprendre les fuites de mémoire dans les tranches de go peut être un défi. Cet article vise à app...La programmation Publié le 2025-07-08 -
Comment corriger \ "MySQL_Config INSTRUST \" Erreur lors de l'installation de MySQL-Python sur Ubuntu / Linux?Erreur d'installation de mysql-python: "mysql_config non fondée" tentant d'installer mysql-python sur ubuntu / linux box peu...La programmation Publié le 2025-07-08
-
Causes et solutions pour la défaillance de la détection du visage: erreur -215Gestion des erreurs: résolution "Erreur: (-215)! Vide () Dans la fonction détectMultiSCALE" dans OpenCv lorsque vous pouvez utiliser...La programmation Publié le 2025-07-08
-
Guide de création de pages Fastapi Custom 404 PagePage personnalisée 404 non trouvé avec fastapi Pour créer une page 404 personnalisée, Fastapi propose plusieurs approches. La méthode appropri...La programmation Publié le 2025-07-08
-
Pourquoi mon image d'arrière-plan CSS apparaît-elle?Troubleshoot: Image d'arrière-plan CSS n'apparaissant pas Vous avez rencontré un problème où votre image d'arrière-plan échoue mal...La programmation Publié le 2025-07-08
-
\ "tandis que (1) vs pour (;;): L'optimisation du compilateur élimine-t-elle les différences de performances? \"while (1) vs pour (;;): y a-t-il une différence de vitesse? Question: LOOPS? Réponse: Dans la plupart des compilateurs modernes, il ...La programmation Publié le 2025-07-08
-
Comment convertir efficacement les fuseaux horaires en PHP?Conversion efficace du fuseau horaire en php Dans PHP, la gestion des fuseaux horaires peut être une tâche simple. Ce guide fournira une méthode...La programmation Publié le 2025-07-08
-
Quand une application Web GO ferme-t-elle la connexion de la base de données?Gestion des connexions de bases de données dans les applications Web Go Dans les applications Web simples GO qui utilisent des bases de données ...La programmation Publié le 2025-07-08
-
`Console.log` montre la raison de l'exception de la valeur de l'objet modifiéobjets et console.log: une bizarrerie démêlée lorsque vous travaillez avec des objets et console.log, vous pouvez rencontrer un comportement p...La programmation Publié le 2025-07-08
-
Format d'heure locale et guide d'affichage de décalage du fuseau horaire localAffichage de la date / heure du format des paramètres locaux de l'utilisateur avec le décalage du temps Lors de la présentation des dates ...La programmation Publié le 2025-07-08
-
Conseils pour trouver la position d'élément dans Java ArrayRécupération de la position de l'élément dans les tableaux java dans la classe des tableaux de Java, il n'y a pas de méthode directe &...La programmation Publié le 2025-07-08
-
Comment analyser les nombres en notation exponentielle à l'aide de décimal.parse ()?analysant un nombre à partir de la notation exponentielle Lorsque vous tentez d'analyser une chaîne exprimée en notation exponentielle en ...La programmation Publié le 2025-07-08
-
Comment capturer et diffuser Stdout en temps réel pour l'exécution de la commande chatbot?Capturant stdout en temps réel à partir de l'exécution de commandes dans le domaine de l'élaboration de chatbots capables d'exécut...La programmation Publié le 2025-07-08
-
Comment télécharger des fichiers avec des paramètres supplémentaires à l'aide de java.net.urlconnection et de codage multipart / formulaire de formulaire?Téléchargement des fichiers avec les demandes http pour télécharger des fichiers sur un serveur http tout en soumettant des paramètres supplém...La programmation Publié le 2025-07-08
-
Comment puis-je exécuter plusieurs instructions SQL dans une seule requête en utilisant Node-Mysql?Prise en charge de la requête multi-statement dans Node-Mysql Dans Node.js, la question se pose lors de l'exécution de plusieurs instructi...La programmation Publié le 2025-07-08















Étudier le chinois
- 1 Comment dit-on « marcher » en chinois ? 走路 Prononciation chinoise, 走路 Apprentissage du chinois
- 2 Comment dit-on « prendre l’avion » en chinois ? 坐飞机 Prononciation chinoise, 坐飞机 Apprentissage du chinois
- 3 Comment dit-on « prendre un train » en chinois ? 坐火车 Prononciation chinoise, 坐火车 Apprentissage du chinois
- 4 Comment dit-on « prendre un bus » en chinois ? 坐车 Prononciation chinoise, 坐车 Apprentissage du chinois
- 5 Comment dire conduire en chinois? 开车 Prononciation chinoise, 开车 Apprentissage du chinois
- 6 Comment dit-on nager en chinois ? 游泳 Prononciation chinoise, 游泳 Apprentissage du chinois
- 7 Comment dit-on faire du vélo en chinois ? 骑自行车 Prononciation chinoise, 骑自行车 Apprentissage du chinois
- 8 Comment dit-on bonjour en chinois ? 你好Prononciation chinoise, 你好Apprentissage du chinois
- 9 Comment dit-on merci en chinois ? 谢谢Prononciation chinoise, 谢谢Apprentissage du chinois
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









