 Página delantera > Programación > COMPRENSIÓN DE SUS DATOS: LOS FUNDAMENTOS DEL ANÁLISIS EXPLORATORIO DE DATOS.
Página delantera > Programación > COMPRENSIÓN DE SUS DATOS: LOS FUNDAMENTOS DEL ANÁLISIS EXPLORATORIO DE DATOS.
COMPRENSIÓN DE SUS DATOS: LOS FUNDAMENTOS DEL ANÁLISIS EXPLORATORIO DE DATOS.
 Navegar:805
Navegar:805
Introducción
Según el objetivo final que tenga sobre sus datos como resultado de un modelo de aprendizaje automático, el desarrollo de visualizaciones y la incorporación de aplicaciones fáciles de usar, desarrollar fluidez en los datos al comienzo del proyecto reforzará el éxito final.
Fundamentos de EDA
Aquí es donde aprendemos cómo la necesidad del preprocesamiento de datos beneficia a los analistas de datos.
Debido a la inmensidad y a las diversas fuentes, es más probable que los datos de hoy sean anormales. El preprocesamiento de datos se ha convertido en la etapa fundamental en el campo de la ciencia de datos, ya que los datos de alta calidad dan como resultado modelos y predicciones más sólidos.
El análisis de datos exploratorio es una herramienta que utilizan los científicos de datos para ver qué datos pueden exponer fuera del modelado formal o de la tarea de prueba de suposiciones.
El científico de datos siempre debe realizar EDA para garantizar resultados confiables y aplicables a cualquier resultado y objetivo afectado. También ayuda a los científicos y analistas a confirmar que están en el camino correcto para lograr los resultados deseados.
Algunos de los ejemplos de preguntas de investigación que guían el estudio son:
1. ¿Existe algún efecto significativo del preprocesamiento de datos?
¿Enfoques de análisis (valores faltantes, agregado de valores, filtrado de datos, valores atípicos, transformación de variables y reducción de variables) sobre resultados precisos del análisis de datos?
2. ¿A qué nivel significativo es necesario el análisis de datos de preprocesamiento en los estudios de investigación?
Métricas de análisis de datos exploratorios y su importancia
1.Filtrado de datos
Esta es la práctica de seleccionar una sección más pequeña de un conjunto de datos y utilizar ese subconjunto para visualización o análisis. Se conserva el conjunto de datos completo, pero sólo se utiliza un subconjunto para el cálculo; El filtrado suele ser un procedimiento temporal. Descubrir observaciones inexactas, incorrectas o deficientes del estudio, extraer datos para un grupo de interés específico o buscar información para un período específico se pueden resumir mediante filtros. El científico de datos debe especificar una regla o lógica durante el filtrado para extraer casos para el estudio.
2.Agregación de datos
La agregación de datos requiere reunir datos no procesados en una única ubicación y resumirlos para su análisis. La agregación de datos aumenta el valor informativo, práctico y utilizable de los datos. La perspectiva de un usuario técnico se utiliza a menudo para definir la frase. La agregación de datos es el proceso de integrar datos no procesados de muchas bases de datos o fuentes de datos en una base de datos centralizada en el caso de un analista o ingeniero. Luego, los números agregados se crean combinando los datos sin procesar. Una suma o promedio es una ilustración sencilla de un valor agregado. Los datos agregados se utilizan en análisis, informes, paneles y otros productos de datos. La agregación de datos puede aumentar la productividad, la toma de decisiones y el tiempo para obtener información.
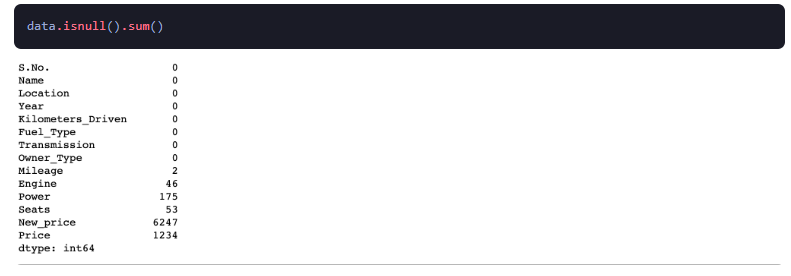
3.Datos faltantes
En análisis de datos, los valores faltantes son otro nombre para faltar
datos. Ocurre cuando variables o encuestados específicos se omiten o se omiten. Pueden ocurrir omisiones debido a una entrada de datos incorrecta, archivos perdidos o tecnología rota. Los datos faltantes pueden provocar de forma intermitente un sesgo en el modelo, según su tipo, lo que los hace problemáticos. Los datos faltantes implican que, dado que los datos pueden provenir a veces de muestras engañosas, los resultados solo pueden generalizarse dentro de los parámetros del estudio. Para garantizar la coherencia en todo el conjunto de datos, es necesario recodificar todos los valores faltantes con etiquetas "N/A" (abreviatura de "no aplicable").
4.Transformación de datos
Los datos se reescalan usando una función u otro método matemático
operación en cada observación durante una transformación. Nosotros
ocasionalmente modifique los datos para que sea más fácil modelar cuando
está muy sesgado (ya sea positiva o negativamente).
En otras palabras, se debería intentar una transformación de datos que se ajuste al supuesto de aplicar una prueba estadística paramétrica si
la(s) variable(s) no se ajusta(n) a una distribución normal. La transformación de datos más popular es log (o registro natural), que se utiliza con frecuencia cuando todas las observaciones son positivas y la mayoría de los valores de los datos se agrupan alrededor de cero en relación con los valores más significativos del conjunto de datos.

Ilustración del diagrama
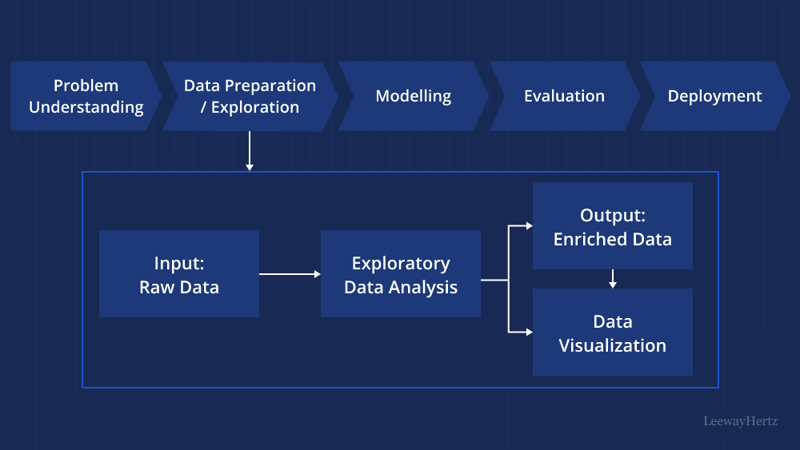
Técnicas de visualización en EDA
Las técnicas de visualización desempeñan un papel esencial en EDA, ya que nos permiten explorar y comprender visualmente estructuras y relaciones de datos complejas. Algunas técnicas de visualización comunes utilizadas en EDA son:
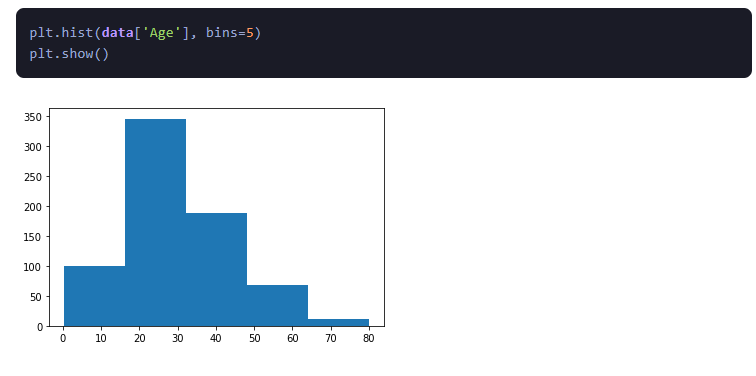
1.Histogramas:
Los histogramas son representaciones gráficas que muestran la distribución de variables numéricas. Ayudan a comprender la tendencia central y la dispersión de los datos al visualizar la distribución de frecuencia.
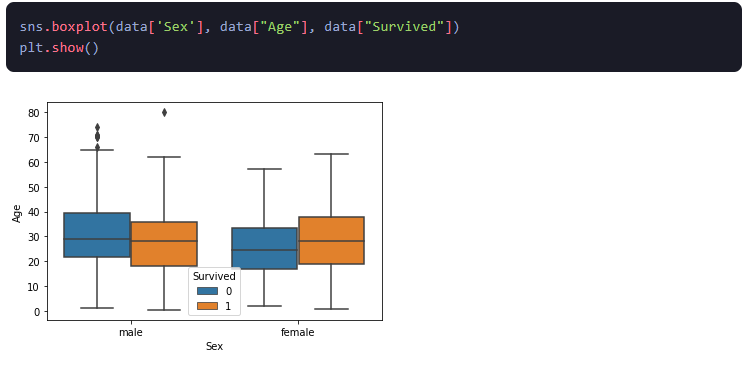
2.Gráficos de caja: Un diagrama de caja es un gráfico que muestra la distribución de una variable numérica. Esta técnica de visualización ayuda a identificar valores atípicos y comprender la dispersión de los datos mediante la visualización de sus cuartiles.
3.Heatmaps: Son representaciones gráficas de datos en los que los colores representan valores. A menudo se utilizan para mostrar conjuntos de datos complejos, lo que proporciona una forma rápida y sencilla de visualizar patrones y tendencias en grandes cantidades de datos.
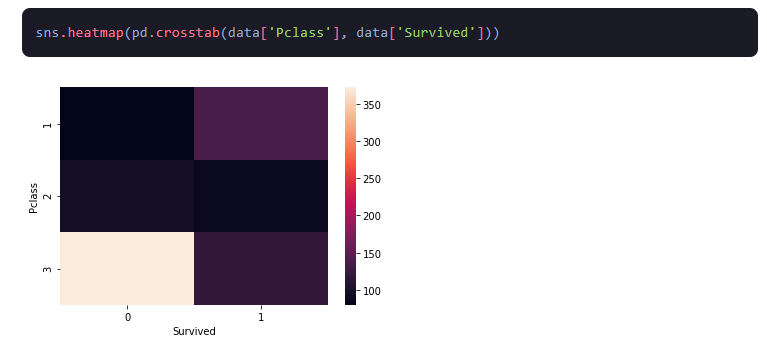
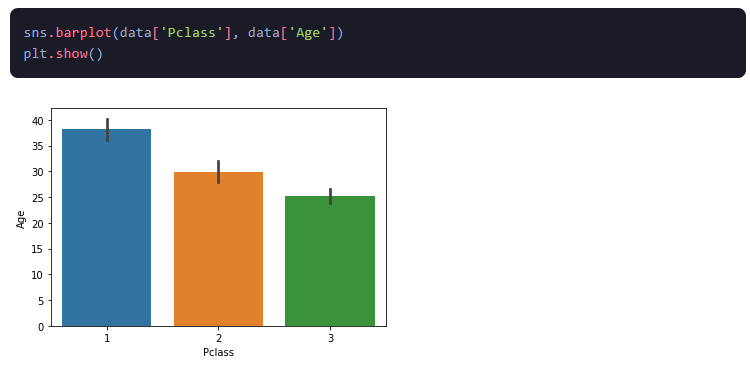
4.Gráficos de barras: Un gráfico de barras es un gráfico que muestra la distribución de una variable categórica. Se utiliza para visualizar la distribución de frecuencia de los datos, lo que ayuda a comprender la frecuencia relativa de cada categoría.
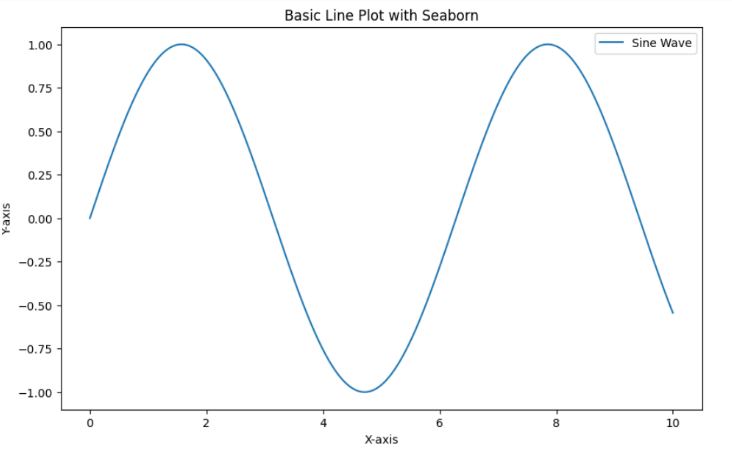
5.Gráficos de líneas: Un gráfico de líneas es un gráfico que muestra la tendencia de una variable numérica a lo largo del tiempo. Se utiliza para visualizar los cambios en los datos a lo largo del tiempo e identificar patrones o tendencias.

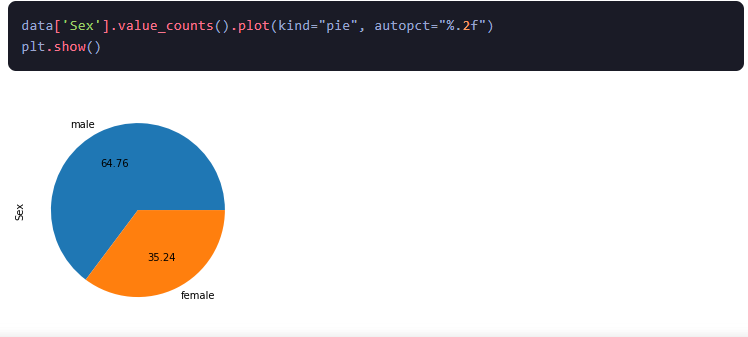
5.Gráficos circulares: Los gráficos circulares son gráficos que muestran la proporción de una variable categórica. Se utiliza para visualizar la proporción relativa de cada categoría y comprender la distribución de los datos.
-
 ¿Cómo mostrar correctamente la fecha y hora actuales en el formato "DD/MM/YYYY HH: MM: SS.SS" en Java?cómo mostrar la fecha y la hora actuales en "dd/mm/aa radica en el uso de diferentes instancias de SimpleFormat con diferentes patrones de f...Programación Publicado el 2025-04-09
¿Cómo mostrar correctamente la fecha y hora actuales en el formato "DD/MM/YYYY HH: MM: SS.SS" en Java?cómo mostrar la fecha y la hora actuales en "dd/mm/aa radica en el uso de diferentes instancias de SimpleFormat con diferentes patrones de f...Programación Publicado el 2025-04-09 -
¿Cómo puedo manejar los nombres de archivo UTF-8 en las funciones del sistema de archivos de PHP?manejando los nombres de archivo UTF-8 en las funciones del sistema de archivos de PHP al crear carpetas que contienen caracteres UTF-8 utiliz...Programación Publicado el 2025-04-09
-
¿Cómo manejar la entrada del usuario en el modo exclusivo de pantalla completa de Java?manejo de la entrada del usuario en el modo exclusivo de la pantalla completa en java introducción cuando ejecuta una aplicación Java en mod...Programación Publicado el 2025-04-09
-
¿Por qué no `cuerpo {margen: 0; } `¿Siempre elimina el margen superior en CSS?abordando la eliminación del margen del cuerpo en css para desarrolladores web novatos, eliminar el margen del elemento corporal puede ser una...Programación Publicado el 2025-04-09
-
¿Cómo redirigir múltiples tipos de usuarios (estudiantes, maestros y administradores) a sus respectivas actividades en una aplicación Firebase?rojo: cómo redirigir múltiples tipos de usuarios a las actividades respectivas Comprender el problema en una aplicación de votación basada...Programación Publicado el 2025-04-09
-
¿Cómo establecer dinámicamente las claves en los objetos JavaScript?cómo crear una clave dinámica para una variable de objeto JavaScript al intentar crear una clave dinámica para un objeto JavaScript, usando esta...Programación Publicado el 2025-04-09
-
¿Por qué Microsoft Visual C ++ no implementa correctamente la instanciación de la plantilla de dos fases?El misterio de la plantilla de dos fases "roto" instanciación en Microsoft Visual c declaración de problemas: usuarios comúnmente ...Programación Publicado el 2025-04-09
-
Fit de objeto: la cubierta falla en IE y Edge, ¿cómo solucionar?Object-Fit: la portada falla en IE y Edge, ¿cómo solucionar? utilizando objeto-fit: cover; en CSS para mantener la altura de imagen consistent...Programación Publicado el 2025-04-09
-
¿Cómo resolver el error \ "Uso no válido de la función de grupo \" en MySQL al encontrar el recuento máximo?cómo recuperar el recuento máximo usando mysql en mysql, puede que pueda un problema al intentar encontrar el recuento máximo de valores agrup...Programación Publicado el 2025-04-09
-
¿Cómo cargar archivos con parámetros adicionales utilizando java.net.urlconnection y codificación multipart/formulario?de carga de archivos con solicitudes http para cargar archivos a un servidor HTTP al tiempo que envía parámetros adicionales, java.net.urlconn...Programación Publicado el 2025-04-09
-
¿Cómo capturar y transmitir stdout en tiempo real para la ejecución del comando de chatbot?capturando stdout en tiempo real desde la ejecución de comandos en el reino de desarrollar chatbots capaces de ejecutar comandos, un requisito...Programación Publicado el 2025-04-09
-
¿Por qué no muestra imágenes de Firefox utilizando la propiedad CSS `Content`?Mostrando imágenes con URL de contenido en Firefox Se ha encontrado un problema cuando ciertos navegadores, específicamente Firefox, no muestr...Programación Publicado el 2025-04-09
-
¿Cómo crear una animación CSS suave de izquierda-derecha para un DIV dentro de su contenedor?animación CSS genérica para el movimiento de derecha izquierda En este artículo, exploraremos la creación de una animación genérica de CSS par...Programación Publicado el 2025-04-09
-
¿Qué método para declarar múltiples variables en JavaScript es más mantenible?declarando múltiples variables en JavaScript: explorando dos métodos en JavaScript, los desarrolladores a menudo encuentran la necesidad de de...Programación Publicado el 2025-04-09
-
¿Se pueden apilar múltiples elementos adhesivos uno encima del otro en CSS puro?¿Es posible tener múltiples elementos pegajosos apilados uno encima del otro en CSS puro? El comportamiento deseado se puede ver Aquí: https...Programación Publicado el 2025-04-09















Estudiar chino
- 1 ¿Cómo se dice "caminar" en chino? 走路 pronunciación china, 走路 aprendizaje chino
- 2 ¿Cómo se dice "tomar un avión" en chino? 坐飞机 pronunciación china, 坐飞机 aprendizaje chino
- 3 ¿Cómo se dice "tomar un tren" en chino? 坐火车 pronunciación china, 坐火车 aprendizaje chino
- 4 ¿Cómo se dice "tomar un autobús" en chino? 坐车 pronunciación china, 坐车 aprendizaje chino
- 5 ¿Cómo se dice conducir en chino? 开车 pronunciación china, 开车 aprendizaje chino
- 6 ¿Cómo se dice nadar en chino? 游泳 pronunciación china, 游泳 aprendizaje chino
- 7 ¿Cómo se dice andar en bicicleta en chino? 骑自行车 pronunciación china, 骑自行车 aprendizaje chino
- 8 ¿Cómo se dice hola en chino? 你好Pronunciación china, 你好Aprendizaje chino
- 9 ¿Cómo se dice gracias en chino? 谢谢Pronunciación china, 谢谢Aprendizaje chino
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









