 Página delantera > Programación > Hice una aplicación de verificación de recuento de tokens usando Streamlit en Snowflake (SiS)
Página delantera > Programación > Hice una aplicación de verificación de recuento de tokens usando Streamlit en Snowflake (SiS)
Hice una aplicación de verificación de recuento de tokens usando Streamlit en Snowflake (SiS)
 Navegar:196
Navegar:196
Introducción
Hola, soy ingeniero de ventas en Snowflake. Me gustaría compartir algunas de mis experiencias y experimentos con ustedes a través de varias publicaciones. En este artículo, le mostraré cómo crear una aplicación usando Streamlit en Snowflake para verificar el recuento de tokens y estimar los costos de Cortex LLM.
Nota: Esta publicación representa mis opiniones personales y no las de Snowflake.
¿Qué es Streamlit en Snowflake (SiS)?
Streamlit es una biblioteca de Python que le permite crear interfaces de usuario web con código Python simple, eliminando la necesidad de HTML/CSS/JavaScript. Puedes ver ejemplos en la Galería de aplicaciones.
Streamlit en Snowflake le permite desarrollar y ejecutar aplicaciones web Streamlit directamente en Snowflake. Es fácil de usar con solo una cuenta de Snowflake y excelente para integrar datos de tablas de Snowflake en aplicaciones web.
Acerca de Streamlit en Snowflake (Documentación oficial de Snowflake)
¿Qué es la corteza del copo de nieve?
Snowflake Cortex es un conjunto de funciones de IA generativa en Snowflake. Cortex LLM le permite llamar a modelos de lenguaje grandes que se ejecutan en Snowflake usando funciones simples en SQL o Python.
Funciones del modelo de lenguaje grande (LLM) (Snowflake Cortex) (Documentación oficial de Snowflake)
Descripción general de funciones
Imagen
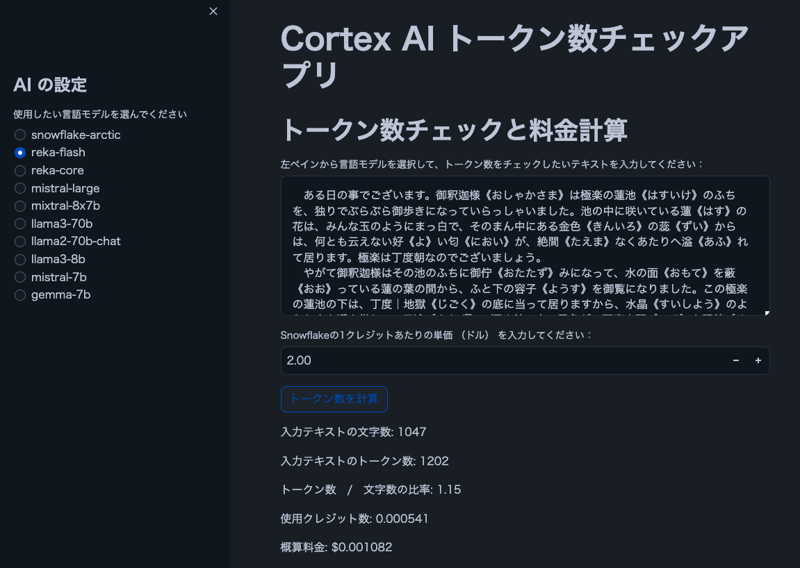
Nota: El texto de la imagen es de "The Spider's Thread" de Ryunosuke Akutagawa.
Características
- Los usuarios pueden seleccionar un modelo de Cortex LLM
- Mostrar recuentos de caracteres y tokens para el texto ingresado por el usuario
- Mostrar la proporción de tokens a caracteres
- Calcule el costo estimado según el precio del crédito de Snowflake
Nota: tabla de precios de Cortex LLM (PDF)
Requisitos previos
- Cuenta Snowflake con acceso a Cortex LLM
- snowflake-ml-python 1.1.2 o posterior
Nota: Disponibilidad regional de Cortex LLM (Documentación oficial de Snowflake)
Código fuente
import streamlit as st
from snowflake.snowpark.context import get_active_session
import snowflake.snowpark.functions as F
# Get current session
session = get_active_session()
# Application title
st.title("Cortex AI Token Count Checker")
# AI settings
st.sidebar.title("AI Settings")
lang_model = st.sidebar.radio("Select the language model you want to use",
("snowflake-arctic", "reka-core", "reka-flash",
"mistral-large2", "mistral-large", "mixtral-8x7b", "mistral-7b",
"llama3.1-405b", "llama3.1-70b", "llama3.1-8b",
"llama3-70b", "llama3-8b", "llama2-70b-chat",
"jamba-instruct", "gemma-7b")
)
# Function to count tokens (using Cortex's token counting function)
def count_tokens(model, text):
result = session.sql(f"SELECT SNOWFLAKE.CORTEX.COUNT_TOKENS('{model}', '{text}') as token_count").collect()
return result[0]['TOKEN_COUNT']
# Token count check and cost calculation
st.header("Token Count Check and Cost Calculation")
input_text = st.text_area("Select a language model from the left pane and enter the text you want to check for token count:", height=200)
# Let user input the price per credit
credit_price = st.number_input("Enter the price per Snowflake credit (in dollars):", min_value=0.0, value=2.0, step=0.01)
# Credits per 1M tokens for each model (as of 2024/8/30, mistral-large2 is not supported)
model_credits = {
"snowflake-arctic": 0.84,
"reka-core": 5.5,
"reka-flash": 0.45,
"mistral-large2": 1.95,
"mistral-large": 5.1,
"mixtral-8x7b": 0.22,
"mistral-7b": 0.12,
"llama3.1-405b": 3,
"llama3.1-70b": 1.21,
"llama3.1-8b": 0.19,
"llama3-70b": 1.21,
"llama3-8b": 0.19,
"llama2-70b-chat": 0.45,
"jamba-instruct": 0.83,
"gemma-7b": 0.12
}
if st.button("Calculate Token Count"):
if input_text:
# Calculate character count
char_count = len(input_text)
st.write(f"Character count of input text: {char_count}")
if lang_model in model_credits:
# Calculate token count
token_count = count_tokens(lang_model, input_text)
st.write(f"Token count of input text: {token_count}")
# Ratio of tokens to characters
ratio = token_count / char_count if char_count > 0 else 0
st.write(f"Token count / Character count ratio: {ratio:.2f}")
# Cost calculation
credits_used = (token_count / 1000000) * model_credits[lang_model]
cost = credits_used * credit_price
st.write(f"Credits used: {credits_used:.6f}")
st.write(f"Estimated cost: ${cost:.6f}")
else:
st.warning("The selected model is not supported by Snowflake's token counting feature.")
else:
st.warning("Please enter some text.")
Conclusión
Esta aplicación facilita la estimación de costos para cargas de trabajo de LLM, especialmente cuando se trata de idiomas como el japonés, donde a menudo hay una brecha entre el recuento de caracteres y el recuento de tokens. ¡Espero que te resulte útil!
Anuncios
Copo de nieve Novedades Actualizaciones en X
Estoy compartiendo las novedades de Snowflake en X. ¡No dudes en seguirnos si estás interesado!
Versión en inglés
Bot de novedades de Snowflake (versión en inglés)
https://x.com/snow_new_en
Versión japonesa
Bot de novedades de Snowflake (versión japonesa)
https://x.com/snow_new_jp
Historial de cambios
(20240914) Publicación inicial
Artículo original japonés
https://zenn.dev/tsubasa_tech/articles/4dd80c91508ec4
-
 ¿Estará realmente el despertar falso en Java?Los despertar espurios en java: realidad o mito? El concepto de despertar espurios en la sincronización de Java ha sido un tema de discusión dur...Programación Publicado el 2025-07-10
¿Estará realmente el despertar falso en Java?Los despertar espurios en java: realidad o mito? El concepto de despertar espurios en la sincronización de Java ha sido un tema de discusión dur...Programación Publicado el 2025-07-10 -
¿Cómo puedo manejar los nombres de archivo UTF-8 en las funciones del sistema de archivos de PHP?manejando los nombres de archivo UTF-8 en las funciones del sistema de archivos de PHP al crear carpetas que contienen caracteres UTF-8 utiliz...Programación Publicado el 2025-07-10
-
Implementación dinámica reflectante de la interfaz GO para la exploración del método RPCReflection para la implementación de la interfaz dinámica en Go Reflection In GO es una herramienta poderosa que permite la inspección y manip...Programación Publicado el 2025-07-10
-
¿Cómo combinar datos de tres tablas MySQL en una nueva tabla?mysql: creando una nueva tabla de datos y columnas de tres tablas pregunta: ¿cómo puedo crear una nueva tabla que combine los datos selecci...Programación Publicado el 2025-07-10
-
¿Por qué no es una solicitud posterior a capturar la entrada en PHP a pesar del código válido?abordando la solicitud de solicitud de la publicación $ _Server ['php_self'];?> "Método =" post "> [&] la intenci...Programación Publicado el 2025-07-10
-
Métodos de acceso y gestión de las variables de entorno de PythonAccediendo a las variables de entorno en python para acceder a las variables de entorno en Python, utilizar el objeto os.environ , que repres...Programación Publicado el 2025-07-10
-
¿Cómo repetir eficientemente los caracteres de cadena para la sangría en C#?repitiendo una cadena para la indentación al sangrar una cadena basada en la profundidad de un elemento, es conveniente tener una forma eficie...Programación Publicado el 2025-07-10
-
¿Por qué no `cuerpo {margen: 0; } `¿Siempre elimina el margen superior en CSS?abordando la eliminación del margen del cuerpo en css para desarrolladores web novatos, eliminar el margen del elemento corporal puede ser una...Programación Publicado el 2025-07-10
-
¿Cómo implementar una función hash genérica para tuplas en colecciones desordenadas?Función hash genérica para tuplas en colecciones no ordenadas los contenedores std :: unordened_map y std :: unordened_set proporcionan una mi...Programación Publicado el 2025-07-10
-
¿Por qué no muestra imágenes de Firefox utilizando la propiedad CSS `Content`?Mostrando imágenes con URL de contenido en Firefox Se ha encontrado un problema cuando ciertos navegadores, específicamente Firefox, no muestr...Programación Publicado el 2025-07-10
-
¿Qué método es más eficiente para la detección de Point-in-Polygon: Ray Tracing o Matplotlib \ 's Rath.Contains_Points?Detección eficiente de Point-in-Polygon en python determinando si un punto se encuentra dentro de un polígono es una tarea frecuente en la geome...Programación Publicado el 2025-07-10
-
Python Metaclass Principio de trabajo y creación y personalización de clases¿Qué son los metaclasses en Python? MetAclasses son responsables de crear objetos de clase en Python. Así como las clases crean instancias, las ...Programación Publicado el 2025-07-10
-
¿Cómo simplificar el análisis de JSON en PHP para matrices multidimensionales?Parsing JSON con php tratando de analizar los datos JSON en PHP puede ser un desafío, especialmente cuando se trata de matrices multidimensional...Programación Publicado el 2025-07-10
-
¿Cómo recuperar eficientemente la última fila para cada identificador único en PostgreSQL?postgresql: extrayendo la última fila para cada identificador único en postgresql, puede encontrar situaciones en las que necesita extraer la ...Programación Publicado el 2025-07-10
-
Python Leer el archivo CSV UnicodeDeCodeError Ultimate Solutionunicode decode error en el archivo csv lectura al intentar leer un archivo csv en python usando el modulo CSV incorporado, (unicodeScal No se ...Programación Publicado el 2025-07-10















Estudiar chino
- 1 ¿Cómo se dice "caminar" en chino? 走路 pronunciación china, 走路 aprendizaje chino
- 2 ¿Cómo se dice "tomar un avión" en chino? 坐飞机 pronunciación china, 坐飞机 aprendizaje chino
- 3 ¿Cómo se dice "tomar un tren" en chino? 坐火车 pronunciación china, 坐火车 aprendizaje chino
- 4 ¿Cómo se dice "tomar un autobús" en chino? 坐车 pronunciación china, 坐车 aprendizaje chino
- 5 ¿Cómo se dice conducir en chino? 开车 pronunciación china, 开车 aprendizaje chino
- 6 ¿Cómo se dice nadar en chino? 游泳 pronunciación china, 游泳 aprendizaje chino
- 7 ¿Cómo se dice andar en bicicleta en chino? 骑自行车 pronunciación china, 骑自行车 aprendizaje chino
- 8 ¿Cómo se dice hola en chino? 你好Pronunciación china, 你好Aprendizaje chino
- 9 ¿Cómo se dice gracias en chino? 谢谢Pronunciación china, 谢谢Aprendizaje chino
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









